
LLMの性質を知る──初心者のための大規模言語モデル解説
概要
LLMの性質を知る──初心者のための大規模言語モデル解説
生成AIの技術を実際に使いこなすには、その中核にあるLLMすなわち大規模言語モデルの性質を正しく理解することが不可欠である。本記事では、LLMとは何か、どう使えばうまくいくのか、そしてどんな落とし穴があるのかを、初心者の方にもわかりやすく解説していく。
LLMとは何か
AI・生成AI・LLMの関係
まず、大きな枠組みから整理する。
AIとは、人間のように考えたり判断したりするコンピュータプログラムのことである。人間の知能を真似て、データから学習し、問題を解決する仕組み全般を指す。厳密な定義があるわけではないので、「コンピュータが賢くふるまう技術」くらいのイメージでいい。
AIの中にもさまざまな種類があるが、大きく分けると「生成AI」と「予測系AI」の2つの方向性がある。
生成AIは、新しいコンテンツを「作り出す」AIである。文章を書いたり、イラストを描いたり、音楽を作曲したり、動画を生成したりと、ゼロから何かを生み出すことができる。一方、予測系AIは、過去のデータをもとに未来を「予測する」AIである。たとえば、顧客の購入確率の予測、商品の需要予測、機器の異常検知、おすすめ商品のレコメンドなどがこれにあたる。
そしてLLM(Large Language Model=大規模言語モデル)は、生成AIの中でも、自然言語(人間の言葉)を扱う大規模なモデルのことである。代表的なLLMとしては、ChatGPT、Claude、Geminiなどがある。
生成AIの本質──「条件付き確率のお化け」
生成AIは「それっぽいもの」を返す
生成AIの本質を一言で表すなら、条件付き確率のお化けである。これはどういう意味なのか。
生成AIは、現在与えられた材料(入力)をもとに、「この文脈ではこういう出力が最も多かった」というパターンから、最もありそうな回答──つまりマジョリティの回答を返しているだけである。言い換えれば、与えられた条件から見て最も常識的な、それっぽいものを出力しているにすぎない。
ここから重要なことが導かれる。決まったルールに基づいて確実に処理してほしいことは、LLMには向かない。そういった処理はプログラムを書くのが適している。むしろ、そのプログラムをLLMに書かせるのが賢い使い方といえる。
条件=プロンプトが命
「条件付き確率」なのだから、条件をきちんと与えることが極めて重要となる。そして、その条件にあたるものが**プロンプト(AIへの指示文)**である。
たとえば、「あなたは優秀なB2Bセールスマンです」という役割を与えるのと、「あなたは熟練のデータアナリストです」と与えるのとでは、同じ質問をしても返ってくる答えの方向性がまったく変わる。セールスマンとして答えるときの「ありがちな回答」と、アナリストとして答えるときの「ありがちな回答」は違うからだ。
アウトプットは確率的にばらつく
生成AIの出力はあくまで確率的なものである。つまり、同じプロンプトで何度も実行しても、毎回まったく同じ回答が返ってくるわけではない。試しに同じ質問を何度か投げてみると、微妙に違う回答が返ってくることがわかるはずだ。
このことは、「たまたまうまくいった」ケースが存在することも意味する。AIの返す「それっぽいもの」がたまたま求めていたものにマッチすることがあり、次に同じプロンプトで質問しても同じ品質の回答が得られるとは限らない。ただし、良いプロンプトを書けば、このばらつきを小さくすることができる。再現性の高い出力を得ることが、プロンプト技術の大きな目標の一つである。
生成AIの得意・不得意
生成AIには明確な得意分野と苦手分野がある。
まず、学習データにないものは決定的に苦手である。たとえばプログラミング言語の選択でいえば、Pythonは世界中で広く使われており学習データも豊富なため、LLMはPythonのコード生成が得意だ。逆に、マイナーな言語ではデータが少ないため精度が落ちる。
また、タイミングの判断も苦手である。「いつ返信するのが最適か」「いつ行動すべきか」といった時間軸に関する判断は、LLM単体では難しい。
さらに、演繹的なアプローチ──つまり「AならばB、BならばC、ゆえにAならばC」のような厳密な論理の連鎖を確実にたどることが不得意である。LLMは「学習データの中で、こういう文脈ではこういう出力が多かった」というパターンから応答を生成しているため、論理的に考えているように見える回答でも、実際には「よくある論理的に見える文章のパターン」を再現しているに過ぎない。この点を理解しておくことは、LLMの出力を過信しないために非常に大切だ。
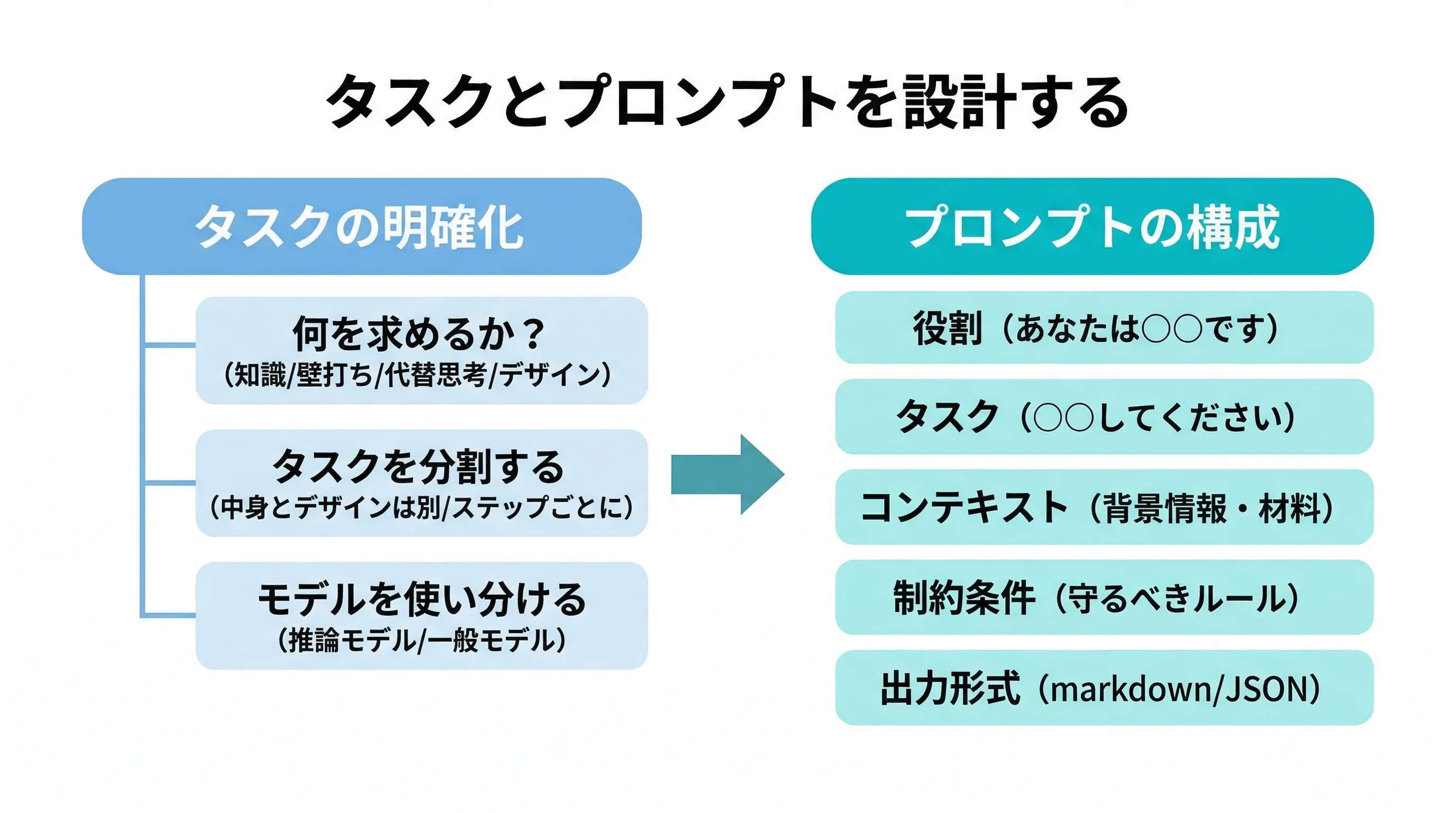
タスク──生成AIに「何を」求めるか
タスクの種類を意識する
生成AIを使うとき、まず自分は今、AIに何を求めているのかをその都度意識することが大切である。代表的なタスクの種類としては、知識を教えてもらうこと、壁打ち(アイデアの議論)相手になってもらうこと、情報を集約・整理してもらうこと、面倒な作業を代行してもらうこと、自分の代わりに考えてもらうこと、そしてイケてるデザインやクリエイティブを作ってもらうことなどがある。壁打ち相手として使う場合は、最後にやりとりの要約やフローチャート化をしてもらうとさらに効果的だ。このあたりの詳細は別記事で説明しているので、そちらも参考にするといい。
タスクに応じた「材料」を与える
タスクの種類によって、AIに与えるべき材料は変わってくる。そして、適切な材料を与えれば、AIは忠実にそれに従って動いてくれる。逆に、材料を与えないとAIはどうすればいいかわからず、わからないままに強引に「それっぽいもの」を返してくる。これが実は厄介で、一見もっともらしい回答に見えるため、そのまま受け入れてしまいがちだ。不十分な材料でのやりとりを繰り返しても、アウトプットの精度は上がらない。
具体的には、作業を頼むのであれば作業手順を示す、考えることを求めるのであれば考え方(後述するCoTなど)や着眼点を指示する、デザインであれば具体的なイメージや条件を示す、ということである。指示を突き詰めた究極の形がフローチャートである。処理の流れを分岐を含めて明確に示せば、AIの出力精度は飛躍的に上がる。
タスクを分割する
大きな仕事を一度にAIに丸投げするのではなく、タスクを分割することが重要だ。たとえば資料作成であれば、中身(コンテンツ)を作ることとデザインを整えることはまったく異なるタスクである。これをまとめて一度にやらせると、出来上がりが微妙だったときに、内容が悪いのかデザインが悪いのか判断しにくくなる。タスクを分割し、それぞれのステップでフィードバックをかければ、改善サイクルを早く回せる。
大きなイシュー(課題)に取り組む場合は、まずその解決手順自体をLLMに聞き、ステップごとにタスク化してから一つずつ進めるのが効果的だ。
モデルを使い分ける
LLMには推論モデルと一般モデルがある。深い思考や複雑な分析が必要な場面では推論モデルが力を発揮するが、知識を聞いたり常識的なやりとりをしたりするだけなら一般モデルで十分だ。個人が対話の中で使う限りコストをそこまで気にする必要はないが、サービス化して多くの人が使う場合にはモデル選択がコストに直結するため重要になる。
プロンプトの技術
基本的なプロンプトの構成
効果的なプロンプトには、基本的な構成要素がある。まず役割──AIにどんな立場で回答してほしいかを示す。次にタスク──具体的に何をしてほしいかを明確にする。そしてコンテキスト・背景情報──タスクの前提となる情報を提供する。さらに制約条件──守らなければならないルールや禁止事項を伝える。最後に出力形式──どのような形で結果を返してほしいかを指定する。出力形式については、テキストであればマークダウン形式が読みやすく加工もしやすいのでおすすめだ。データをやり取りする場合はJSON形式にすると正確性が高まる。
演繹的アプローチと帰納的アプローチ
プロンプトの組み立て方には、大きく2つのアプローチがある。
演繹的アプローチは、CoT(Chain of Thought)と呼ばれる手法に代表される。これは「まず○○を考え、次に△△を検討し、最後に□□を判断してください」のように、考え方の手順を明示的に示すやり方だ。
帰納的アプローチの代表的なものがFew-shotと呼ばれる手法だ。「こういう入力に対してはこういう出力が正解です」という具体的なパターン例をいくつか示し、「これらの例から類推して答えてください」と指示する。
一方のアプローチでうまくいかない場合は、もう一方を試してみると改善することがある。
すぐに使える実践Tips
プロンプトにステップバイステップで考えてくださいと追加するだけで、論理的な回答が得られやすくなる。初心者にも分かるように説明してくださいと加えると、専門用語が減って平易な表現になる。具体例を3つ挙げてくださいと付ければ、抽象的な説明に留まらず理解が深まる回答が返ってくる。これらはすぐに試せるテクニックなので、ぜひ普段のやりとりに取り入れてみてほしい。
コンテキストを制する
プロンプトを作るプロンプトという考え方
LLMとの対話には、見落とされがちな重要な側面がある。それは、LLMとの対話そのものが「次のプロンプトを作る作業」でもあるということだ。API経由でのやりとりでは、それまでの会話のすべてがコンテキスト(文脈情報)としてLLMに渡されている。つまり、LLMとの一連のやりとりは、満足のいくアウトプット品質を得るための、精度の高いプロンプトを段階的に作り上げていく作業なのである。
異なるコンテキストを組み合わせる
この考え方を発展させると、強力な使い方が見えてくる。たとえば、Deep Research(AIによる深い調査)の結果を、別のプロンプトのコンテキストとして組み込むことができる。自社データの分析をAIに頼む際に、事前に行った市場調査のDeep Research結果をコンテキストとして追加すれば、単なる自社データの分析だけのときとはまったく違う質の洞察が得られる。ただし、追加するコンテキストが本来の目的の邪魔にならないよう注意が必要だ。
コンテキストの限界──「AIは忘れる」
コンテキストの運用で最大のボトルネックとなるのが、インプットトークンの長さである。カタログスペック上は非常に長いコンテキストを扱えることになっていても、実際にはやりとりが長くなるにつれて精度が落ちていく。指示を無視したり、前に伝えた条件を「忘れた」かのようにふるまったりすることが増える。長いインプットトークンで真ん中を忘れる(無視する)“Lost in the Middle"という現象がまさにこれである。
対策としては、ある程度やりとりが長くなってきたらチャットをリセットすることが有効だ。その際、それまでのやりとりの内容をAIに要約させ、その要約を新しいチャットに貼り付けて再開すれば、重要な情報を引き継ぎつつリフレッシュできる。
もう一つ注意すべき点がある。プロジェクト機能などで暗黙のうちに使われている自分専用のコンテキストに頼りすぎると、自力でプロンプトを組み立てる力が衰えてしまう。あくまでプロンプトの基本を身につけた上で、便利な機能を活用するのが望ましい姿勢だ。
高度なプロンプトテクニック
対話型アプローチ
高度なテクニックの一つに、AIに対話をさせて、AIが必要な情報を自分で収集するように仕向ける方法がある。ユーザが最初から的確なプロンプトを作れない場合に特に効果的だ。
やり方としては、「まず私に必要な質問をしてから作業を開始してください」「明確にならない場合は次のステップに進まず、何度も聞きなおしてください」といった指示をプロンプトに含める。こうすることで、AIがインタビュアーのように振る舞い、タスクに必要な情報を引き出してくれる。
最初にAIに聞くべき3つの質問
あるタスクをAIに頼む前に、まずそのタスクについて以下の3点を質問すると効果的である。
1つ目は、AIにできること。そのタスクのうち、AIが得意な部分や確実にこなせる部分を把握する。2つ目は、AIにできないこと。苦手な部分や対応が難しい部分を事前に知ることで、代替手段を考えたり、妥協ラインを設定したりできる。3つ目は、AIが追加で欲しい情報。これを聞き出して、コンテキストとして与えることで、アウトプットの精度が下がりにくくなる。
AIのアウトプットに不満があるとき
タスクが大きすぎないか見直す
出力に満足できないとき、そもそもタスクが大きすぎる可能性がある。前述のとおり、タスクを適切な粒度に分割してから再度取り組んでみよう。
指示を無視される場合
AIに指示に忠実に動作させるのは、実は意外と難しいことである。結構な頻度で指示を無視する。指示に従わなかったことをその場で指摘すれば、次の瞬間は指示通りに動く。しかし、それだけでは別のタスクでまた同じように無視されることがある。
根本的な対策としては、なぜ指示に従わなかったのか、その理由をAIに直接聞いてみることだ。そして、どのようにプロンプトを書き換えれば従いやすくなるかも聞いてみよう。これによって得られたフィードバックを自分のプロンプト改善に役立てることができる。
着眼点が不足している場合
AIの回答が浅い、視点が足りないと感じる場合は、事前に着眼点をリストアップしておくことが有効である。そのリストアップ自体をAIとのブレインストーミングで行ってもよいだろう。「この問題についてどんな観点から考えるべきか」を先に整理してからタスクに入ることで、出力の深みが増す。
ハルシネーション(もっともらしい嘘)への対策
ハルシネーションとは、AIがもっともらしいが事実ではない情報を生成してしまう現象である。これに対しては、最終的にはユーザ自身の知識で判定するしかない部分もあるが、プロンプト技術での対応も可能だ。回答に根拠や出典を求める指示を入れたり、回答の最後に検証ステップを設けたりするシステムプロンプトを組み込むことで、リスクを軽減できる。ハルシネーションを防ぐためのプロンプト技術は別記事で説明しているので、そちらも参考にするといい。
良いプロンプトの判断基準
自分のプロンプトが「良いプロンプト」かどうかを判断するには、3つの基準がある。
まず、同じプロンプトで何度試しても安定した品質の回答が得られること。前述のとおり、生成AIの出力は確率的にばらつくが、良いプロンプトはそのばらつきを最小限に抑える。
次に、指示した通りの形式で出力されること。マークダウンで出すよう指示したらマークダウンで出る、箇条書きを求めたら箇条書きになる、というように、形式面の指示が確実に反映されていることだ。
最後に、余計な情報が含まれないこと。必要な情報が過不足なく、なるべく少ないトークンで出力されることが理想だ。冗長な前置きや不要な補足が減れば、それだけ実用的なアウトプットに近づく。
生成AIと業務
プロンプト作成は業務の言語化
業務をAI化するためにプロンプトを作る作業は、実は業務そのものを言語化する作業にほかならない。「この仕事ではどんな情報が必要で、どんな手順で、どんな判断基準で進めるのか」を明文化する行為であり、これは必ずしもAIに限った話ではなく、業務改善や引き継ぎにも直結する普遍的に価値のある取り組みだ。
ドキュメントはマークダウンで
業務で扱うドキュメントは、可能な限りマークダウン形式にしておくのがおすすめだ。マークダウンはテキストベースなので加工しやすく、さまざまな形式への変換も容易である。AIとのやりとりにおいても、マークダウンで書かれた文書はそのままコンテキストとして使いやすいという利点がある。
業務フローの再構築という覚悟
最後に、本格的にAIを仕事のサイクルに組み込んで運用するためには、業務フロー全体の再構築が必要になるということを強調しておく。既存の業務の一部をAIに置き換えるだけでは、AIの力を十分に引き出すことはできない。どこでAIを使い、どこで人間が判断し、どうフィードバックを回すかを含めた全体設計が求められる。そのためには相応の時間と労力が必要だ。やるならば覚悟を持って取り組もう。