目次
クラウドを使った理想のバッチ運用
Google Compute Engineのメリットはリサーブ不要で、
使う時間だけ起動してコストメリットを享受できる点にある。
毎日決まったバッチ処理をする時間だけインスタンスを起動し、終了時に停止する運用をすれば、
本当にバッチ処理を実行する時間しか課金対象にならない。
ハイスペックなインスタンスを使ってもそんなにコストはかからない。
そんな運用ができたら、毎日決まった時間にインスタンスを起動することができたら理想なのだが…
実はGoogle Cloud Platformの管理画面上ではできないのだが、
インスタンス管理用のGCEインスタンスを作れば可能になる。
他のインスタンスの実行管理をするためのインスタンス(マスタ)を常時起動しておいて、
そこからバッチ処理用のインスタンスをタイマー(cron)で起動させるのである。
大まかな流れ
Google Compute Engine にはgcloudコマンドがインストールされているが、
これを使えば他のインスタンスの起動、停止を行える。
毎日(毎週)決まったタイミングで他のインスタンスの起動することができる。
以下の流れである。
- 管理用インスタンス…常時起動
- 決まったタイミングでワーカーのインスタンスを起動
- cron
- 起動した直後のタイミングでバッチ処理を実行
- cronを使う
- /etc/rc.localに記述
- バッチ処理の終了時にインスタンスを停止するコマンドを入れておく
管理用インスタンスは常時起動しておく必要があるが、
インスタンス自体のハードウェアリソースを使うわけではないので
低スペックなインスタンスでも十分。f1-micro(メモリ0.6GB)の月額4ドルで十分、
USのインスタンスで十分である。
管理用のインスタンスではGCEの管理だけでなくBigQueryやCloud Storageのバッチ処理をやってもいい。
なおGoogle Cloud Shellではcronが実質使えないので、
自前でGCEのインスタンスを持っておく必要はある。
(Cloud Shellはログアウトして1時間経過するとcrontabの中身が消える)。
Google Cloud SDKがインストールされていればいいので、GCEに限らずローカルのPCでも
(常時起動していれば)実現可能である。(でもさすがにそこはGCP使おうよ…)
GCEの中で他のインスタンスを起動、停止する
gcloudコマンドなのでGCEに限らず、Google Cloud SDKがインストールされていればいい。
ターミナルにログイン時
インスタンスを起動する
gcloud compute instances start インスタンス名 --project プロジェクト名 --zone us-central1-c
インスタンスを停止する
gcloud compute instances stop インスタンス名 --project プロジェクト名 --zone us-central1-c
ターミナルに非ログイン時(cronで実行する場合など)
インスタンスを起動する
gcloud --account=アカウント名 compute instances start インスタンス名 --project プロジェクト名 --zone us-central1-c
--account=アカウント名でアカウントを指定するところがポイント。
実はデフォルトでgcloudコマンドを実行する際の認証済みのアカウントは、
インスタンスの設定「サービスアカウント」で指定したものになっている。
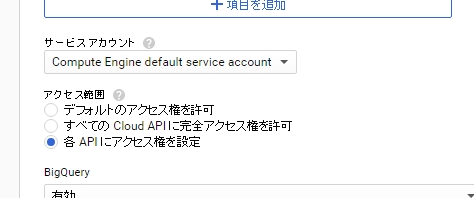
このアカウントを–accountで指定しないとcredentialが無効とのエラーが発生する。
上の例で「Compute Engine default service account」が
「999999999999-compute@developer.gserviceaccount.com」の場合、以下のようになる。
gcloud --account=999999999999-compute@developer.gserviceaccount.com compute instances start my-instance --project my-project-99999 --zone us-central1-c
もしくは
gcloud auth list
で現在認証済みのアカウントを探し、それを–accountで指定することができる。たとえば
Credentialed accounts:
- 999999999999-compute@developer.gserviceaccount.com <-- デフォルトのサービスアカウント
- my-account1@gmail.com <-- 追加したアカウント
の場合、
- 999999999999-compute@developer.gserviceaccount.com
- my-account1@gmail.com
が指定できる。
現在認証されていないアカウント、通常のユーザアカウントで実行したい場合は
gcloud auth login
で認証を通しておく。
なおGoogle Cloud Shellだとターミナルで直接実行することはできるが、
cronだと認証済みのアカウントでもcredentialが無効とのエラーが出る。
cronで設定
crontab -e
毎週月曜の午前5時2分にインスタンスを起動する場合(週次バッチ)
2 5 * * 1 gcloud --account=999999999999-compute@developer.gserviceaccount.com compute instances start my-instance --project my-project-99999 --zone us-central1-c >> /home/myuser/autoboot.log 2>&1
ワーカー側の処理
実際にバッチ処理を行うインスタンス(ワーカー)はバッチ処理の内容に応じて
ハードウェアリソースを調整しておく。
バッチ処理の自動実行は
- cronを使う
- 起動スクリプトの中に入れておく
(インストール済みのサービスを使う場合があるので、起動の最終段階)
方法がある。
処理を実行するだけでなく、実行終了時に
インスタンス停止することも自動化しておくといい。
(バッチ処理の最後に記述)
cron
(省略)
起動スクリプトに入れる
/etc/rc.localを使うのが簡単。
インスタンスの起動時にバッチ処理を行い、終了して5分後にシャットダウンする場合
/etc/rc.local
#!/bin/sh -e
:
バッチ処理1;
バッチ処理2;
sleep 5m
shutdown -h now
exit 0
ポイントはshutdownコマンドの実行前に5分間待機するというところ。
処理が終了した瞬間にシャットダウンされると、
トラブルシューティングの際にインスタンスを立ち上げてもすぐにシャットダウン
=ロジックに手を付ける時間がなくシャットダウン
されるということになる。
待機時間中に/etc/rc.localを書き換えてシャットダウンが実行されないように
するだけの余裕を残しておく必要がある。
ちなみに
shutdown -h -t 300
もダメ。すでにシャットダウンコマンドが実行されているので、インスタンスは落ちる。
/etc/rc.localを使う運用自体が最近のLinuxディストリビューションで非推奨なので、
このあたりを参考に。
http://qiita.com/irotoris/items/5187e0c741eca4d0c563
他にランレベルを使う方法もあるかもしれないので、
(メンテナンス用のランレベルとバッチ実行用のランレベルを分ける)
適切に運用してほしい。
BigQueryでデータ処理のクエリを実行する
GCPといえばBigQueryを使ってデータ処理のバッチを実行することが多い。
GCEにはbqコマンドがインストールされているが、GCEに限らずGoogle Cloud SDKがインストールされていれば処理自体は可能である。
bqコマンド
コマンドの詳細は以下を参照
http://www.apps-gcp.com/bq-command/
https://cloud.google.com/bigquery/bq-command-line-tool
バッチ処理の内容
BigQueryのクエリをバッチで実行する場合、現状で更新系が(ほぼ)使えないので
- 既存のテーブルに対するクエリを実行
- 結果を新しいテーブルとして作成する
という処理が中心になる。
1はできるが、2のデータの格納先のデータセット名、テーブル名を指定する必要がある。
要件としては
- 特定のディレクトリにクエリを記述したテキストファイルを格納しておいてまとめて実行
- クエリファイルの名前で格納先のデータセットとテーブル名を指定
- 日付連番に対応(
TABLE_DATE_RANGE()関数などで使えるように)
- 日付連番に対応(
- 実行する順番をクエリファイル名に数字として指定
- 実行結果のログは出力(エラー対策)
あたりになる。
スクリプトの例
クエリファイルの名前で設定を代用する。命名規則は
順番_データセット名.テーブル名.拡張子
01_my-dataset.new-table.sql
- アンダーバー(
_)とドット(.)は間違えないでね - 拡張子はなんでもいい
- テーブル名に
_DATEという文字列を入れるとTABLE_DATE_RANGE()関数に対応した日付に置き換える
doSql.sh
#!/bin/sh
SQLDIR=sqls # クエリのテキストファイルを格納したディレクトリ
DATESTR=`date +%Y%m%d` # テーブル名に日付を付けてTABLE_DATE_RANGE()関数などで使う
LOGFILE=log.txt # ログファイルの名前
for f in `find $SQLDIR -type f | sort`
do
dest=`echo $f | sed -e 's!^.*/!!' | sed -E "s/\.[^\.]+$//" | sed -E 's/^[^_]+_//g' | sed -E "s/_DATE/_$DATESTR/"`
echo $dest
echo '[' `date +"%Y/%m/%d %H:%M:%S"` ']' $f >> $LOGFILE
bq query --allow_large_results --destination_table=$dest --replace < $f >> $LOGFILE
done
ディレクトリ構造は
├── doSql.sh
├── log.txt
└── sqls
├── 01_my-dataset.new-table.sql
├── 02_my-dataset.new-table2_DATE.sql
└── 03_my-dataset2.table3_DATE.sql
cronで設定
crontab -e
毎日の午前6時2分にインスタンスを起動する場合(日次バッチ)
2 6 * * * /home/user1/doSql.sh
データ周辺の技術 の記事一覧