
Google BigQueryでお手軽機械学習(BQML)
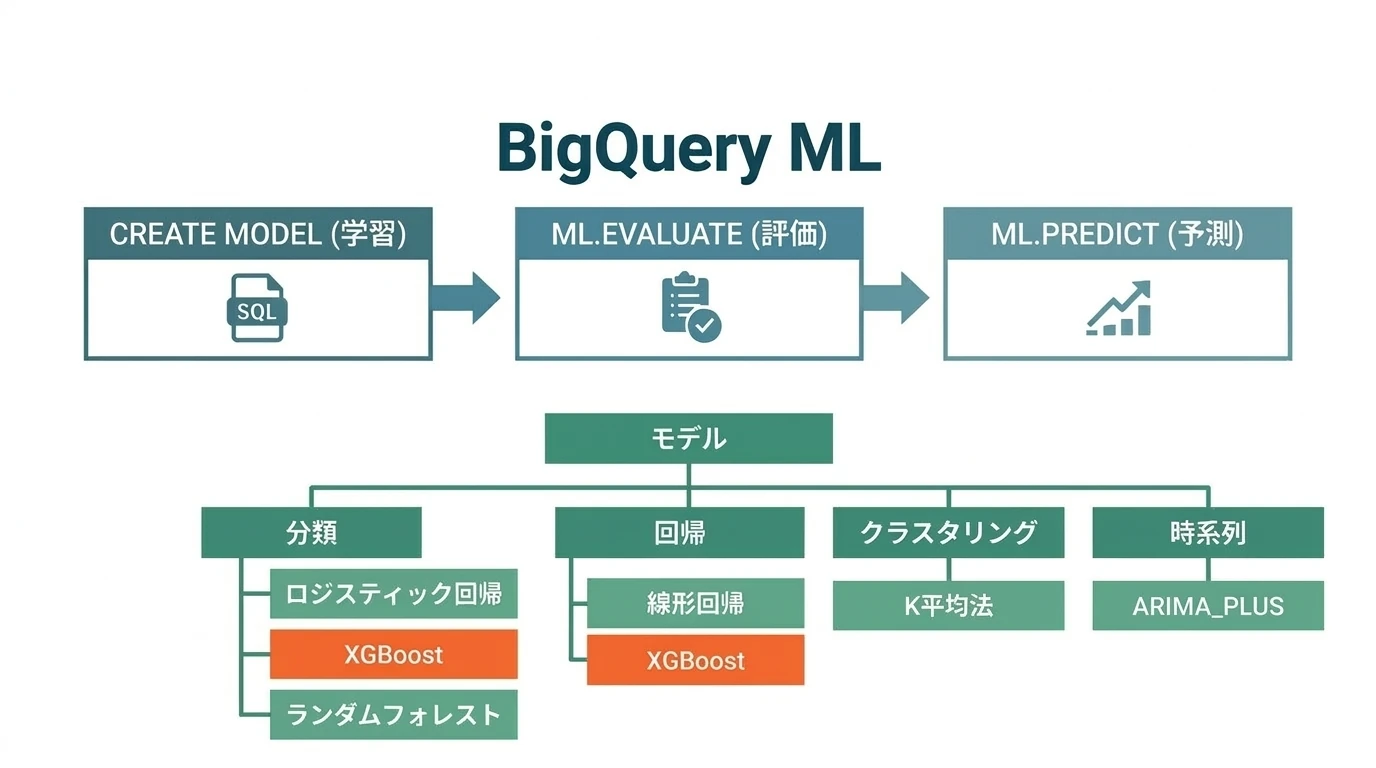
概要
BigQuery MLは生成AI(Geminiなど)との連携やVertex AI統合など多様な機能を提供しているが、企業の日常業務で扱う構造化データ(売上、顧客、在庫など)の予測分析において、最もコストパフォーマンスが高く実用的な手法は依然として勾配ブースティング木(XGBoost系)である。この記事では、SQLだけで完結するMLパイプラインの構築方法を実例とともに解説する。
BigQuery ML(BQML)では以下のモデルが使える:
- 線形回帰 - 類似のリモートデータでトレーニングされたモデルを使用して、新しいデータの数値指標の値を予測する。ラベルは実数で、正の無限大、負の無限大、NaN(非数値)にはできない。
- ロジスティック回帰 - 入力がlow-value、medium-value、high-valueのいずれであるかなど、2つ以上の有効な値を分類する場合に使用する。ラベルには最大50個の一意の値を指定できる。
- K平均法クラスタリング - データセグメンテーションに使用する。顧客セグメントの識別などに使える。教師なし学習なのでモデルのトレーニングを行う際にラベルは必要なく、トレーニングや評価用にデータの分割を行う必要もない。
- 行列分解 - 商品のレコメンデーションシステムの作成に使用する。過去の顧客行動、トランザクション、商品評価を使用して商品のおすすめを作成し、これらのレコメンデーションを使用してカスタマイズされたカスタマーエクスペリエンスを提供できる。
- 主成分分析(PCA) - 主成分を計算し、それらを使用してデータに基底変換を実行するプロセス。一般に、データのバリエーションをできるだけ多く保持しながら、各データポイントを最初のいくつかの主成分にのみ射影して低次元のデータを取得することで、次元数を削減するために使用される。
- 時系列 - 時系列予測と異常検出に使用する。ARIMA_PLUSモデルとARIMA_PLUS_XREGモデルは、複数のチューニングオプションを提供し、異常値、季節性、休日を自動で処理する。
- ディープニューラルネットワーク(DNN) - 分類モデルと回帰モデル用にTensorFlowベースのディープニューラルネットワークを構築する。
- ワイド&ディープ - レコメンデーションシステム、検索、ランキングに関する問題など、スパース入力による大規模な回帰と分類問題(多くの特徴値を持つカテゴリ特徴)に役立つ。
- オートエンコーダ - スパースデータ表現をサポートするTensorFlowベースのモデルを作成する。BigQuery MLのモデルは、教師なし異常検出や非線形次元削減などのタスクに使用できる。
- ブーストツリー - XGBoostに基づく分類モデルと回帰モデルを作成する。
- ランダムフォレスト - トレーニング時の分類、回帰、その他のタスク用に、複数の学習方法のディシジョンツリーを構築するために使用する。
- AutoML - 表形式データの分類モデルと回帰モデルを高速かつ大規模に構築してデプロイする教師ありMLサービス。
当初は線形回帰とロジスティック回帰だけだったが今では実用的な手法が増えた。何よりもXGBoostが使えるようになったのが大きい。
XGBoostのメリット
XGBoostは語弊を恐れずに言うと特に何も考えなくてもそれなりの精度が出る、素人でもそこそこのアウトプットを出せてしまう手法である。これまでの線形回帰やロジスティック回帰は前提条件が扱いが難しい手法だった。
XGBoostがお手軽というのは、
- 正規化不要
- カテゴリ変数と連続量を意識しなくてもいい
- 欠損値があってもいい
つまり特徴量の前処理の面倒な部分がかなり軽減されている。与えられた変数を特に加工しなくても使える。XGBoostはそういったことが不要な、お手軽で大変便利な手法である。
この記事ではBigQueryでお手軽に機械学習を体感してみようということで、XGBoostを使ってBQMLを説明する。
方法
データセットの準備
対象データは学習(train)/評価(evaluate/validate)/テストで予測するデータに分割する。目的変数と説明変数に加え、分割用の列subsetを作り
subset = 'TRAIN': 学習用データsubset = 'EVALUATE': 評価用データsubset = 'TEST': 予測用データ
という値を付与しておく。今回はBigQueryの公開サンプルデータであるbigquery-public-data.ml_datasets.ulb_fraud_detectionを使って不正取引の予測をするモデルを作る。
Classが目的変数となる不正取引フラグ- 特徴量は
V1~V28とAmount(取引額)。V1~V28はオリジナルの特徴量を主成分分析で集約したもの - これを学習:評価:テスト=8:1:1で分割する
create or replace table `my-project.test_dataset.ulb_fraud_detection` as
with t1 as (
select
row_number() over() id,
*,
rand() rnd
from `bigquery-public-data.ml_datasets.ulb_fraud_detection`
), t2 as (
select
* except(rnd),
case
when rnd < 0.8 then 'TRAIN'
when rnd < 0.9 then 'EVALUATE'
else 'TEST'
end subset
from t1
)
select * from t2 order by id;
BQMLの機械学習手順
まずBQMLの操作手順だが、機械学習の手順に沿い
- モデルの構築(TRAIN)
- モデルの評価(EVALUATE/VALIDATE)
- 予測
それぞれに対応したステートメントがある。
MLの処理
モデルの構築
CREATE OR REPLACE MODEL `データセット.モデル名`
TRANSFORM(そのまま使う列名1,
そのまま使う列名2,
変換用の関数(列名3) AS 別名3,
普通の関数でもいい(列名4) AS 別名4)
OPTIONS(MODEL_TYPE = 'モデル名'
input_label_cols=['目的変数']
パラメータ名1=値1,
パラメータ名2=値2) AS
SELECT 使う列名
FROM データのテーブル
WHERE subset = 'TRAIN' -- 学習用データ
;
TRANSFORM()は前処理の指定。TRANSFORMがない場合、SELECTしたテーブルの列がそのまま使われる。
OPTIONS()はモデル自体の指定。モデルの種類やパラメータを指定する。
- 学習対象テーブルからデータをSELECT
TRANSFORM()に基づいて前処理(データ加工など)OPTIONS()に基づいて学習
あらかじめ対象のテーブルに対して前処理を済ませているのであればTRANSFORM()は不要になる。
前処理固有の関数は https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-preprocessing-functions を参照。これらはMLでない普通のクエリの中でも使える。
ロジスティック回帰の場合
CREATE OR REPLACE MODEL `my-project.test_dataset.model_fraud_detection_logit_100_iter`
OPTIONS(
MODEL_TYPE='LOGISTIC_REG',
INPUT_LABEL_COLS=['Class']
) AS
select * except(id, Time, subset)
from `my-project.test_dataset.ulb_fraud_detection`
where subset = 'TRAIN';
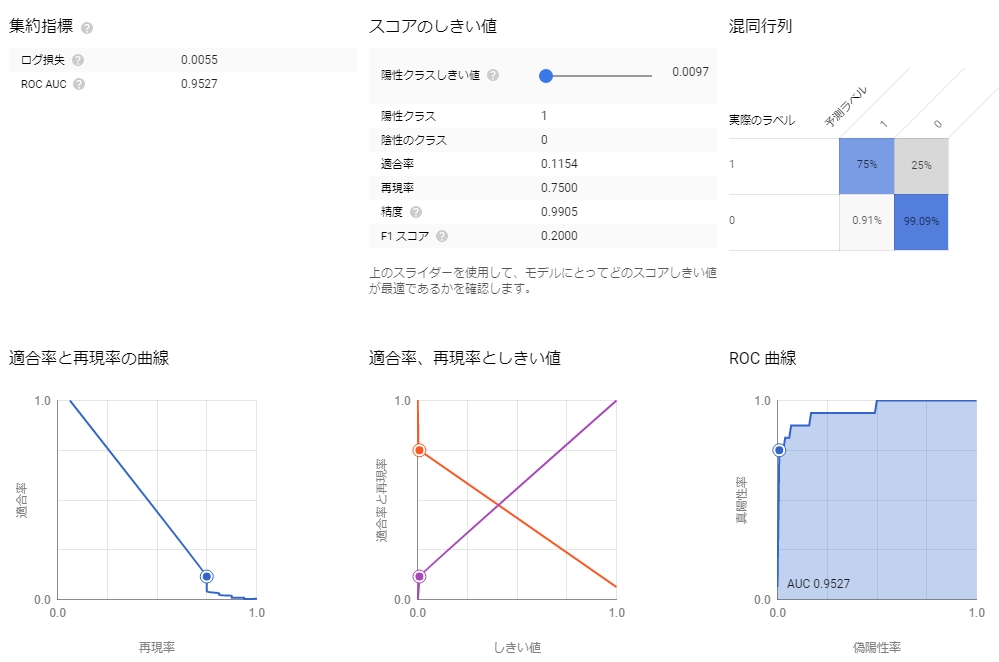
このケースでは特徴量が主成分化されているのでロジスティック回帰が使いやすい。
XGBoostの場合
CREATE OR REPLACE MODEL `my-project.test_dataset.model_fraud_detection_xgb_100_iter`
OPTIONS(
MODEL_TYPE='BOOSTED_TREE_CLASSIFIER',
MAX_ITERATIONS=100,
LEARN_RATE=0.1,
SUBSAMPLE=0.8,
INPUT_LABEL_COLS=['Class']
) AS
select * except(id, Time, subset)
from `my-project.test_dataset.ulb_fraud_detection`
where subset = 'TRAIN';
モデルの種類によってOPTIONS()で指定するパラメータが異なる。XGBoostのチューニングパラメータの詳細は以下のページに記載しているが
- 計算の繰り返し回数(
max_iterations):100回 - 学習率(
learn_rate):0.1 - 木を作る際に用いるレコード数のサンプリング率(
subsample):0.8
https://www.marketechlabo.com/r-xgboost-tuning/#パラメータ
結果はこのようになる。
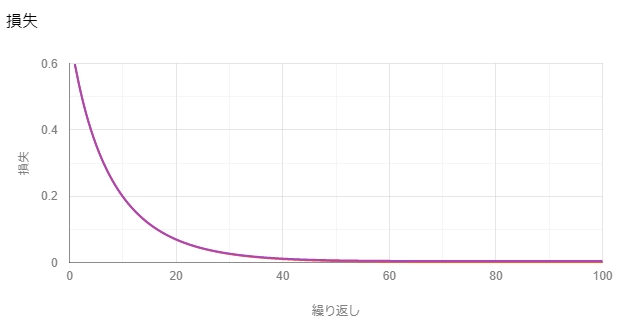
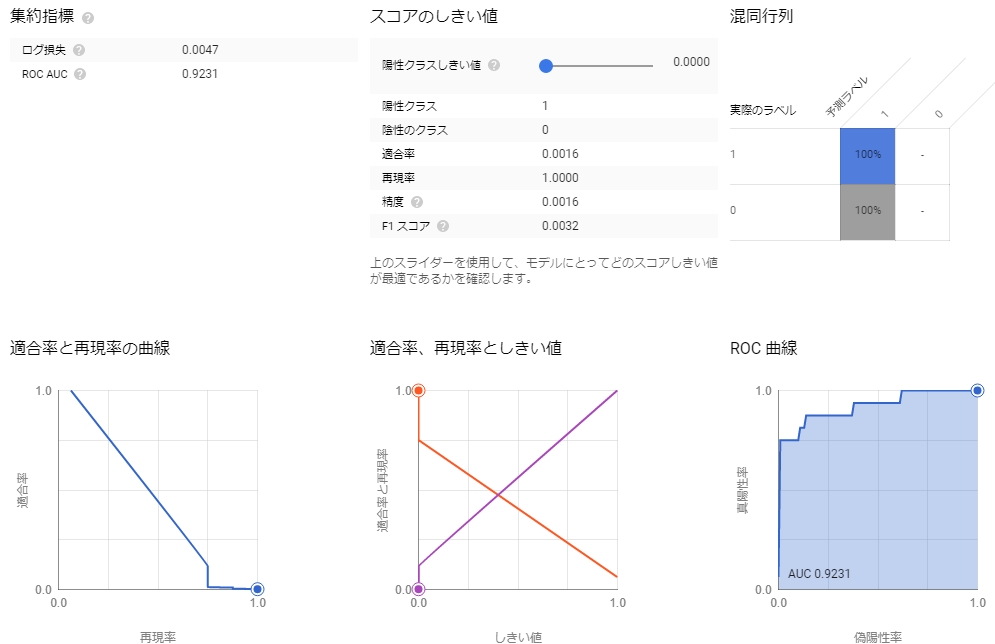
モデルの評価
SELECT * FROM ML.EVALUATE(MODEL `データセット.モデル名`, (
SELECT 使う列名
FROM データのテーブル
WHERE subset = 'EVALUATE' -- 評価用データ
));
たとえば
SELECT * FROM ML.EVALUATE(MODEL `my-project.test_dataset.model_fraud_detection_xgb_100_iter`, (
select * except(id, Time, subset)
from `my-project.test_dataset.ulb_fraud_detection`
where subset = 'EVALUATE'
));

予測
SELECT * FROM ML.PREDICT(MODEL `データセット.モデル名`, (
SELECT 使う列名
FROM データのテーブル
WHERE subset = 'TEST' -- テスト用データ
));
たとえば
SELECT * FROM ML.PREDICT(MODEL `my-project.test_dataset.model_fraud_detection_xgb_100_iter`, (
select * except(id, Time, subset)
from `my-project.test_dataset.ulb_fraud_detection`
where subset = 'TEST'
));
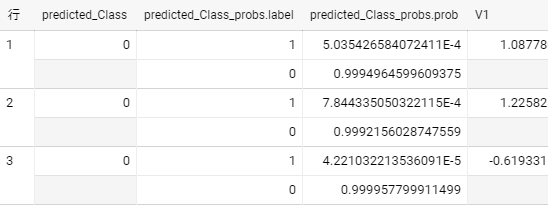
true/false予測では以下のように結果から確率を抽出して正解と比較するといい。
with predictions as (
SELECT * FROM ML.PREDICT(MODEL `my-project.test_dataset.model_fraud_detection_xgb_100_iter`, (
select * except(id, Time, subset)
from `my-project.test_dataset.ulb_fraud_detection`
where subset = 'TEST'
))
)
select
Class,
(select p.prob from unnest(predictions.predicted_Class_probs) p where p.label = 1) prob
from predictions;
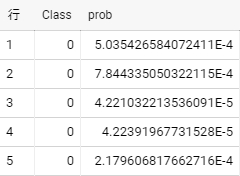
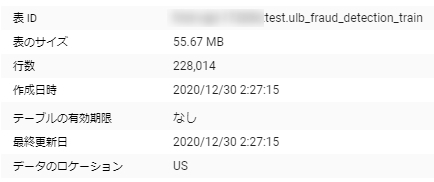
処理時間とコスト
学習データが22万行30列程度の55MBのデータ
100ラウンドの学習で10分/処理したデータ量が16GB
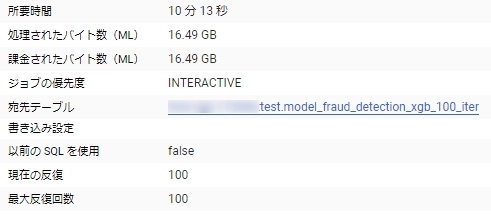
一方で3ラウンドの学習にした場合8分で処理したデータ量は変わらない。
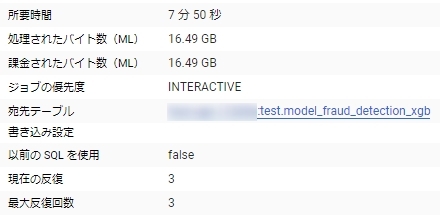
データを前処理するオーバーヘッドが大きいようで、ラウンド数を増やしてもコストはあまり変わらないようである。
評価と予測には時間がかからない。
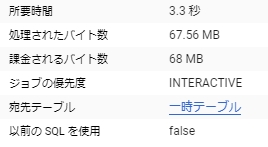
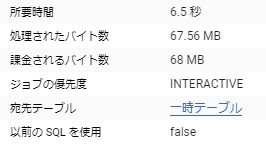
こんな感じでインスタンスを立てたり面倒な設定をしたりする必要もなく簡単に機械学習を実現できる。