
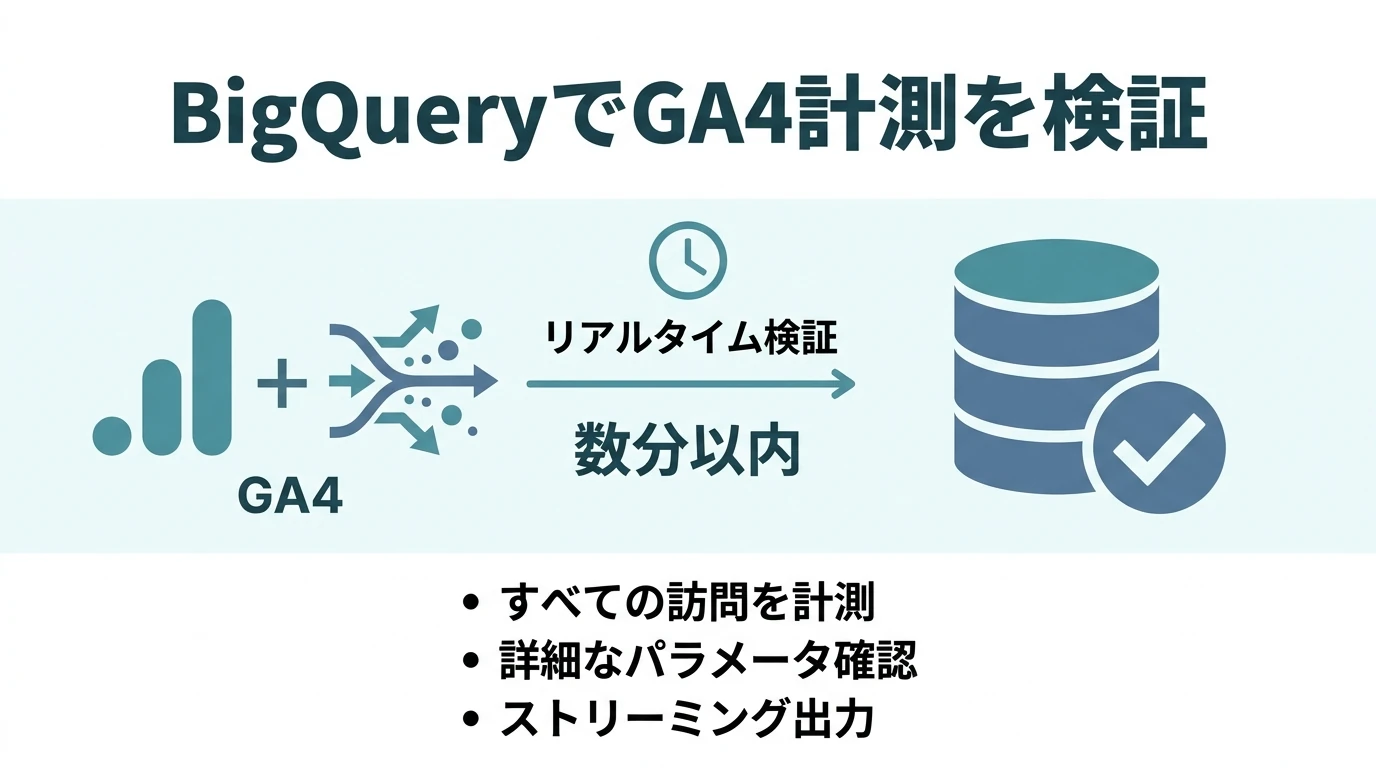
GA4の計測の検証はBigQueryエクスポートを使って行うのが普通になる。検証の方法にはいくつかあるのだが、ほかの方法だと欠点がある。 リアルタイムレポートではイベントが発生し、パラメータに値が入ってきているのはわかるが、どのイベントでどのパラメータの値が入っているかまではわからない。DebugViewは有効化しないと使えない。 BigQueryエクスポートを使うとすべてのサイト訪問に対して計測して数分以内には各パケット(イベント)でどのパラメータにどの値が入っているかがわかるし、詳細な検証ができる。 GA4のBigQueryデータはパラメータやユーザープロパティがネストされているため、クエリでは毎回それをフラット化する手続きをす …
続きを読む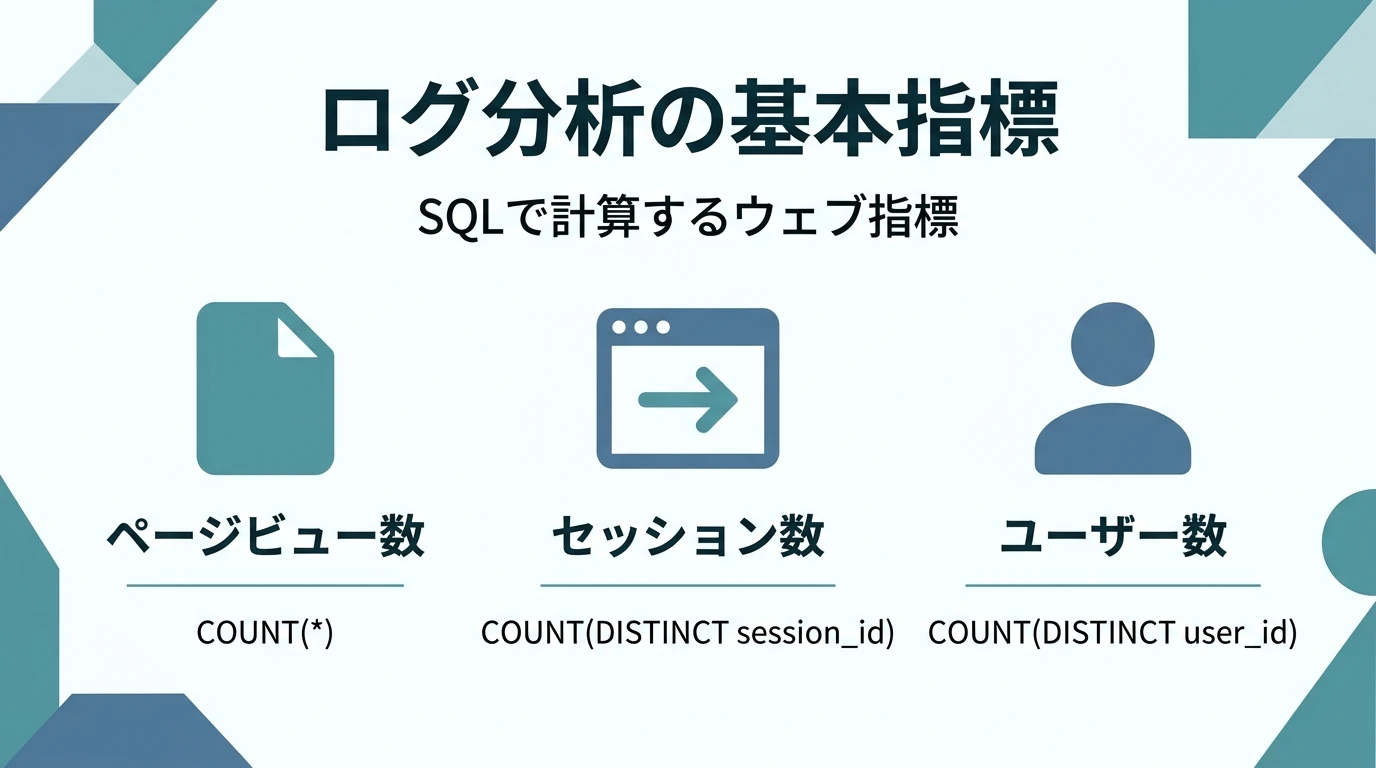
Googleアナリティクス4プロパティが登場し、誰でもBigQueryにログを出力できるようになった。ログ分析を始める環境は揃ったわけだが、ログ分析のノウハウはあまり世に出ていない。SQLを使ってこれらを分析する方法を少し紹介する。どんな高度なログ分析をするにしても、これが基本となる。 ウェブ分析の指標 ウェブ分析の基本は ページビュー数 セッション数 人数 のカウントである。複雑な分析も、結局カウントしているのはこの3つの指標に集約されることが多い。Eコマースになると購入金額の合計なども入ってくることはある。 そしてこれに「○○した」という条件が付いて イベント○○が発生した回数 ○○したページビュー数 パラメータ△△の値が□□だ …
続きを読む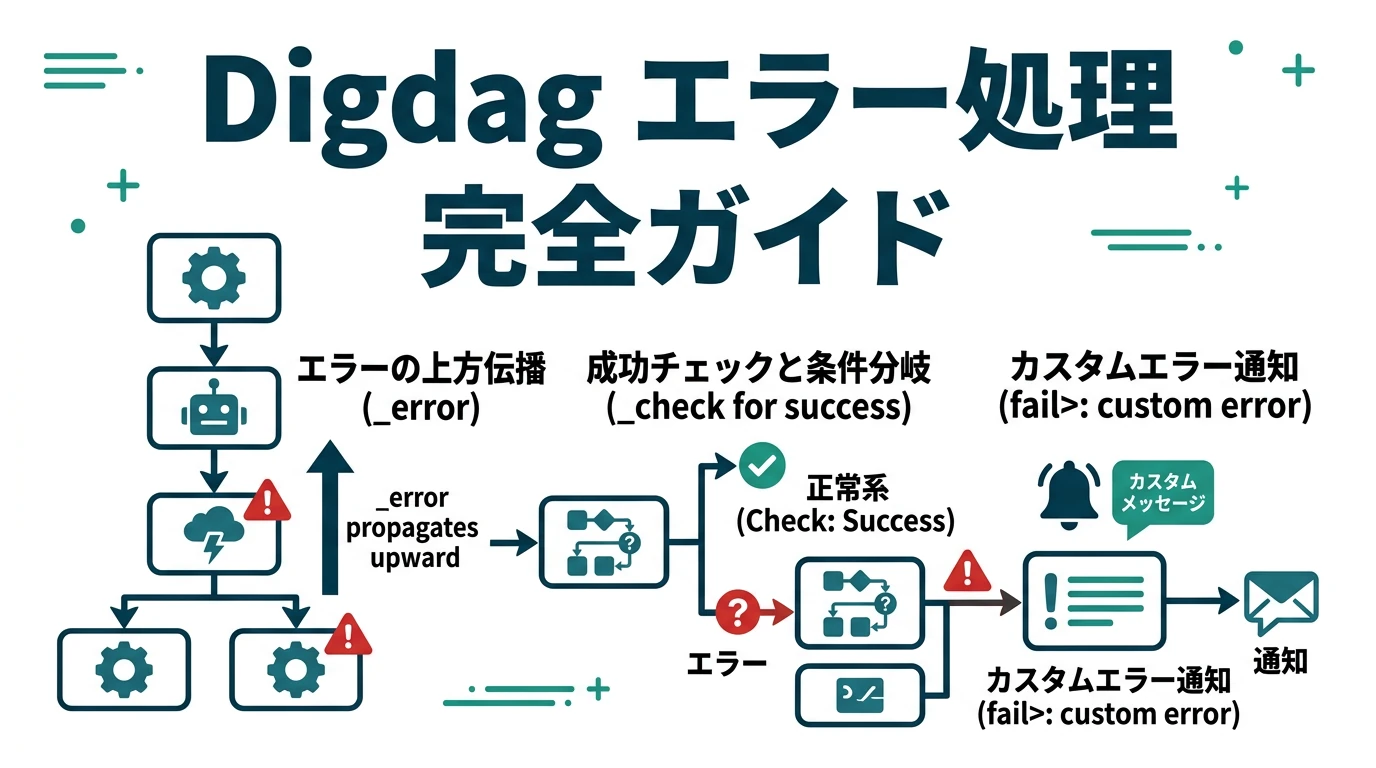
この記事はDigdag v0.9.41時点の検証結果に基づく。 Digdag / TreasureData Workflowのエラー処理。エラー時の処理を指定する_errorだけでなく_checkやfail>:などの処理もあり、エラー発生/成功時の処理をカスタマイズできる。自由度が高く、ワークフローの階層構造とともにうまく使えばワークフローのコードが簡潔になる。公式ドキュメントの説明が不十分なので補足する。 Digdagがエラーと判定して_errorを発動する条件 コマンドの戻り値が0であれば正常、0でなければエラーとみなす。つまりシェルスクリプト(sh:>)の場合は exit 1 であればエラーとなる。 _errorを複数の階層で …
続きを読む
GTMとGA4の高度な使い方。設定しておくと便利な変数やトリガーの使い方に加え、データレイヤーを徹底的に使いこなす。さらには計測だけでなく検証の手間を大幅に省くタグアシスタントの裏技を紹介する。 GTM設定の黒魔術 便利な変数 ページビューID ページビュー固有のID。 一度ページを読み込んでから、次に読み込むまでの間で保持されるIDで、そのIDをさまざまなツールに送ればそれをキーにデータ連携できる。 ツールA,B,Cの間でIDを連携する場合、 ツールAのIDを取得→Bに送る ツールAのIDを取得→Cに送る ツールBのIDを取得→Cに送る (CのIDを取得→Aに送る?) (CのIDを取得→Bに送る?) など、ツール数が増えると複雑に …
続きを読む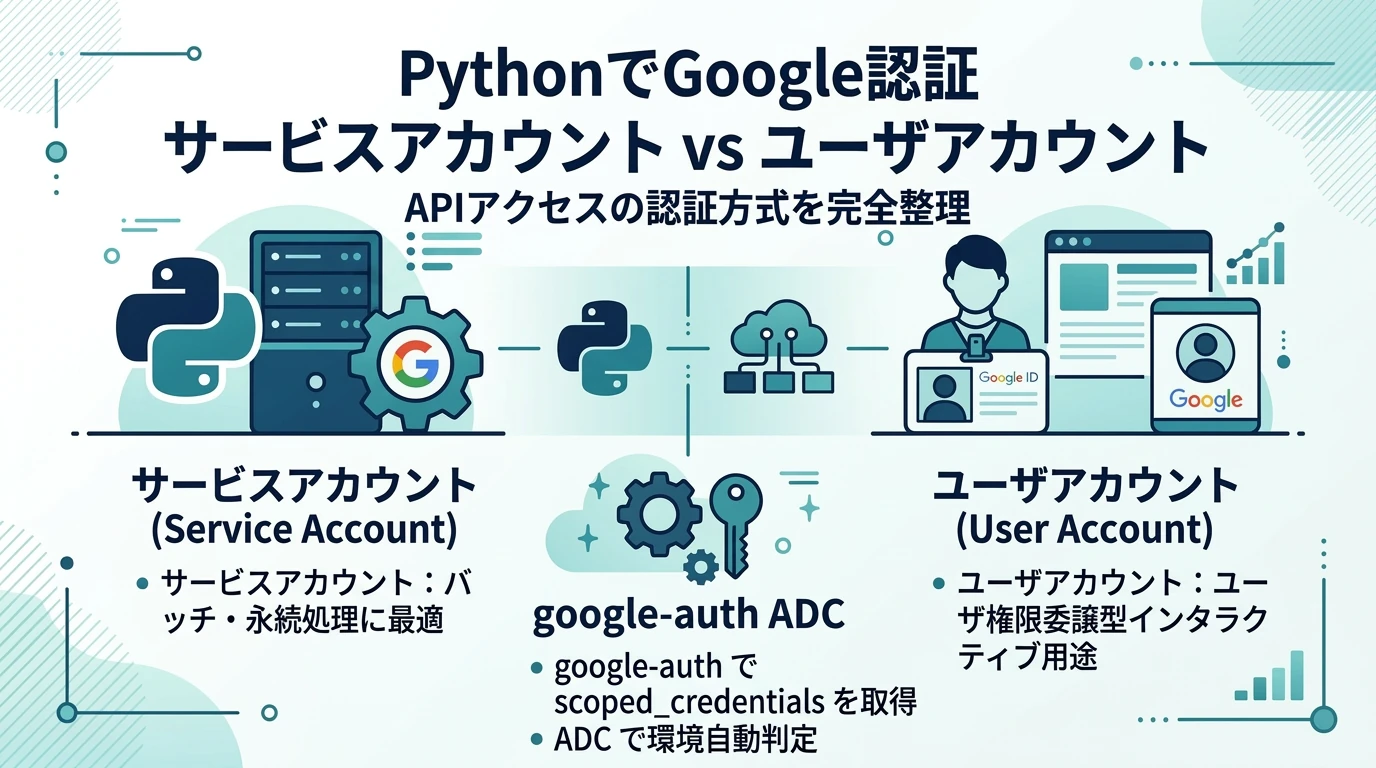
プログラムの中でGoogleのサービス(API)を操作するとき、Google認証が必要になる。しかしこれがややこしく、Googleの公式のドキュメントの記述も古かったりサービスの種類によって方法がばらばらだったりして分かりにくい。この記事ではこれを整理して説明する。 プログラムでGoogle認証する場面 具体的なケースを想定するとわかりやすいのだが、 たとえばGoogleアナリティクスからAPIでデータ取得し、そのデータをGoogle Cloud StorageやBigQueryに書き込みする場合、Googleアナリティクスのレポート閲覧権限(特定のビューに紐づいた)とGCPの権限(Google Cloud Storageの書き込み …
続きを読む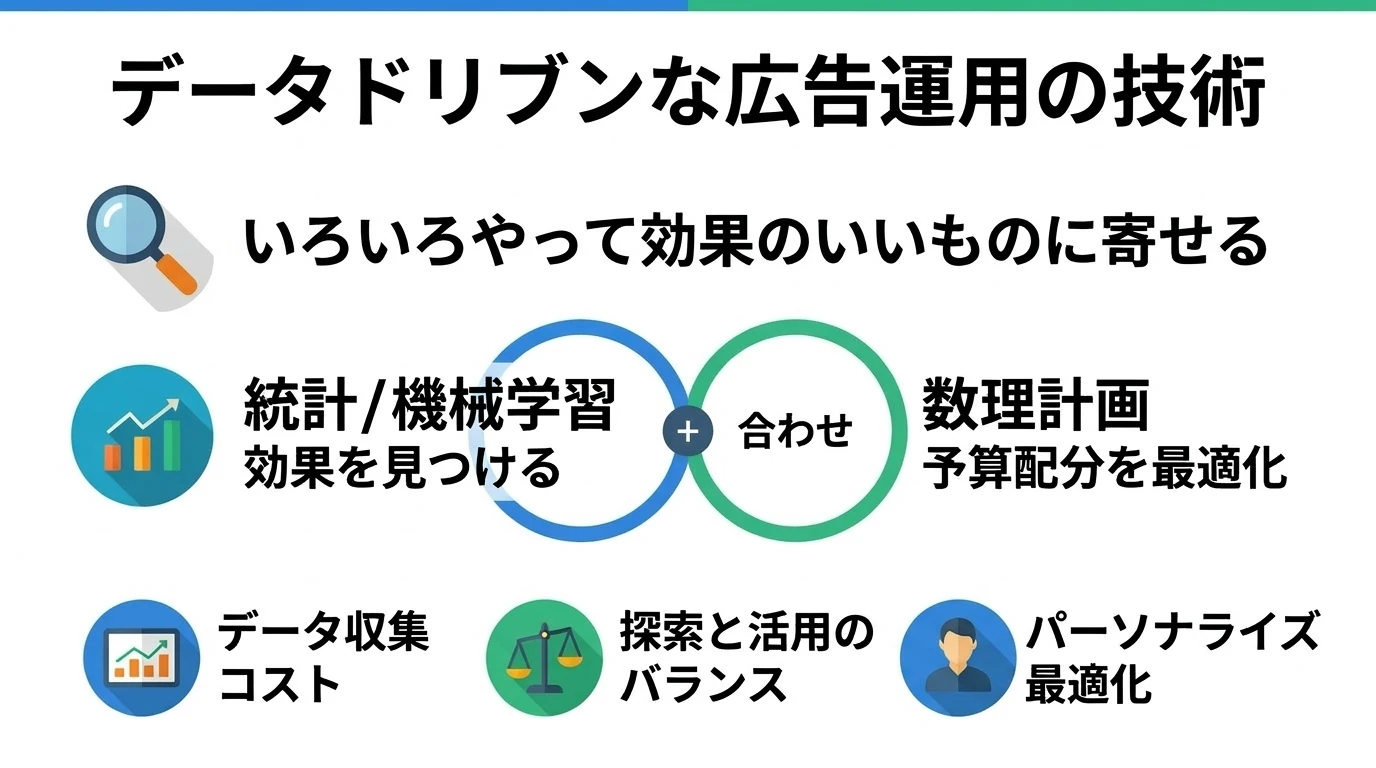
データに基づいた広告運用をするのであれば、データを適切に扱うための技術(方法論)に則る必要がある。データドリブンな運用に必要な技術を、使われる文脈とコアとなるキーワードととともに紹介する。 データに基づいた最適化のプロセスは手動運用、自動運用ともに基本は同じであり、自動運用は機械がそれを行っているだけである。データドリブンで手動運用する際のポイントと、自動運用がそれをいかにして効率化しているかを紹介する。最適化の裏側で何が行われているか、自動運用との付き合い方においても参考になるだろう。 データドリブンな運用とは? 「いろいろやって効果のいいものに寄せる」 が基本。ただし制約条件はいろいろある(予算など)。 「いろいろやっていいもの …
続きを読む
データ処理バッチでシェルスクリプトは便利 データ処理などでバッチプログラムを書くことは多い。Pythonなどのプログラム言語を使って全部記述する方法もあるし、最近ではGUIのワークフローを描けるツールも出てきている。 ただシェルスクリプトは依然として強い。シェルスクリプトは概して動作が高速で、イレギュラー処理に対しても柔軟に対応できる。gcloudやawscliなどのコマンドを使って記述できるので、できないことはない。機能がなければコマンドをインストールすることも可能。困ったときにも確実にゴールにたどり着くメリットがある。プログラム言語だとライブラリの出来に依存する。AirflowやPrefect、Cloud Composerなどワ …
続きを読む
Google Cloud Platformの静的コンテンツ配信機能は低コストで手軽に使うことができる。サーバサイドプログラム(PHPなど)のかかわらない静的ウェブサイトの配信(HTML+CSS+JavaScript+画像+動画など)だけであれば、ApacheやNginxなどのウェブサーバなど不要でできてしまう。スケーラブルでトラフィックによるサーバ負荷を気にする必要がない低コストの環境が簡単に使える。WordPressでも静的配信をしているのであれば相性がいい。キャンペーンのランディングページなどもこれで十分なケースがほとんどである。 この記事ではGoogle Cloud Storageを使った簡単な方法と、少し高度にはなるが独自ド …
続きを読む
ITPの仕様 この記事ではSafari/WebKitのIntelligent Tracking Prevention(ITP)の仕様を、2026年3月現在の最新情報に基づいて解説する。各ブラウザのプライバシー対策の全体像やサードパーティcookie代替技術についてはtracking-privacy-by-browsers.mdを参照されたい。 ITPの目的と概要 われわれウェブサイト運用者は cookieやローカルストレージなどを使ってブラウザにドメインのデータを保持し、 それらのデータを必要に応じてツール間で連携する ことによって行動計測やコンテンツの出し分けなどのマーケティング活動を行っている。ITPはウェブサイト訪問者のプライ …
続きを読む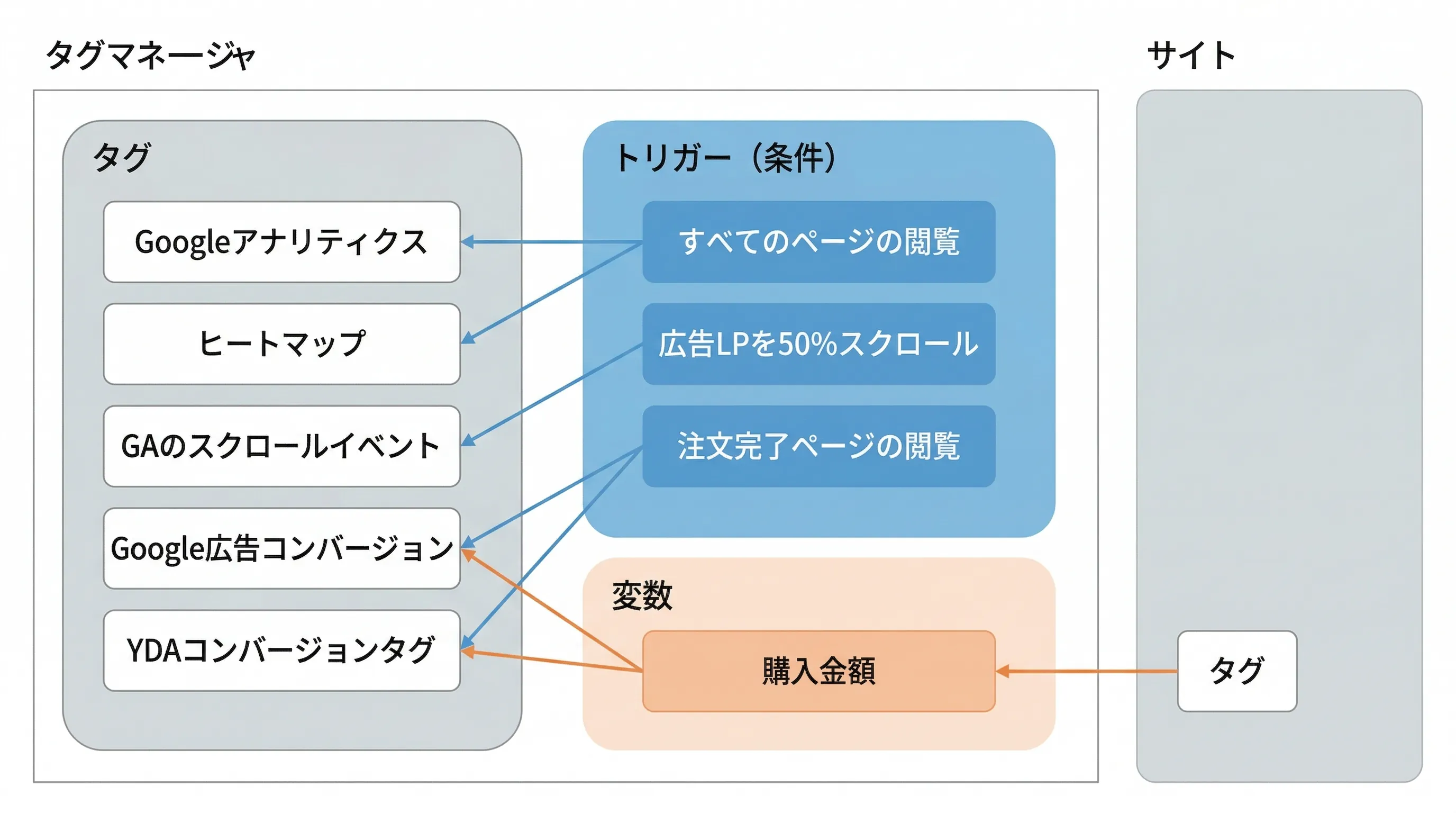
Googleタグマネージャー(GTM)を使ったタグマネジメントについて解説する。前半ではタグマネジメントの概念と仕組みの一般論、後半ではGTMの具体的な設定方法を説明する。 タグマネジメントとタグマネージャ タグマネジメントとはwebサイトに設置するタグの一元管理である。管理すべきタグには以下のようなものがある。 アクセス解析ツールのタグ 広告のコンバージョンタグ リマーケティングタグ 接客ツール(チャットなど)のタグ ABテストツールのタグ web施策が進んでいくと、これらのタグを複数、それぞれ異なるページに設置する必要が出てくる。どのタグをどんな条件で設置したか管理し、不要になったタグは削除するなどの運用を徹底しておかないと、同 …
続きを読む