
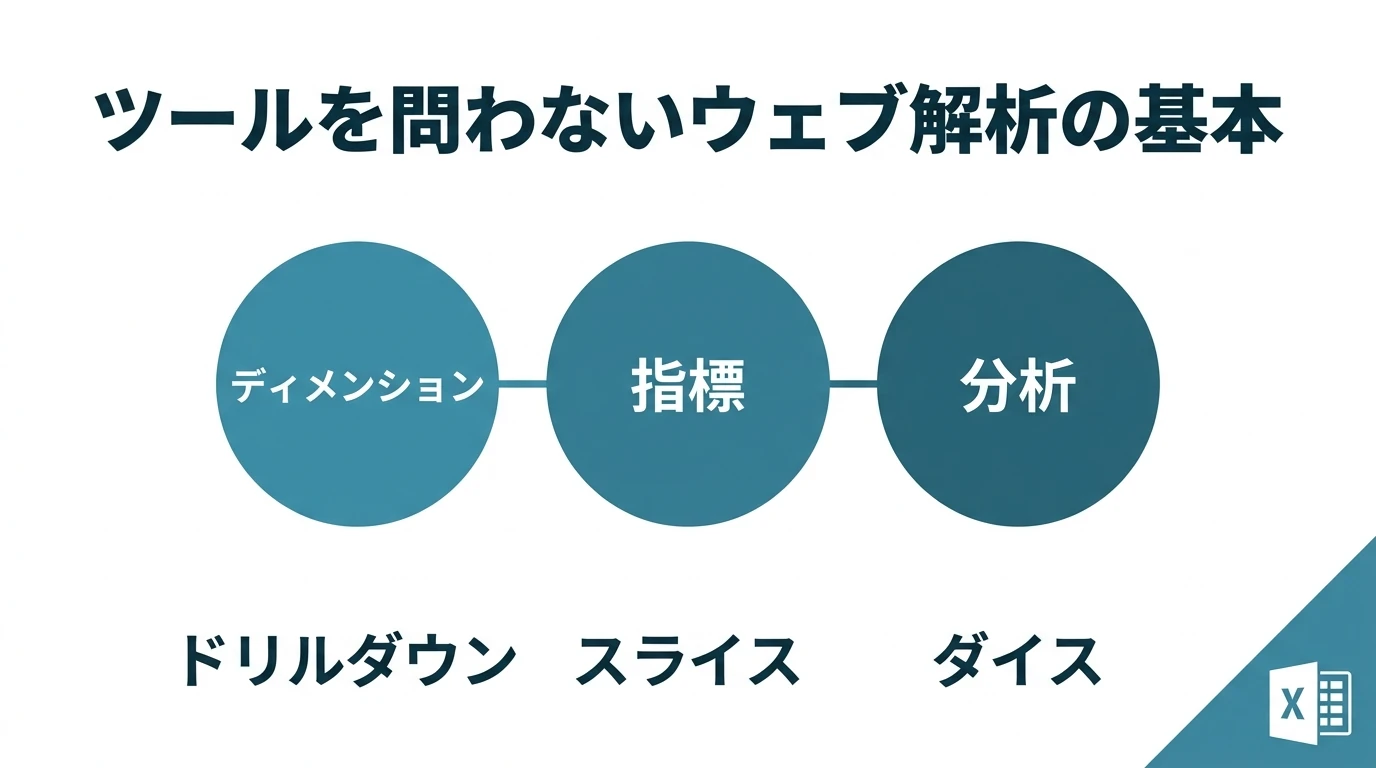
ツールを問わずやりたいのはアクセス解析 Googleアナリティクスは無料でアクセス解析、ウェブ解析ができるツールで、手軽に使えるような環境からよく「Googleアナリティクスの使いかたを学びたい」という声が出てくる。 有料なので使う人はあまり多くはないが、アクセス解析ツールといえばAdobe Analyticsも同じ仲間であり、やることは同じである。 重要なのは「Googleアナリティクス」という固有のツールの使い方を知ることではなく、アクセス解析/ウェブ解析の目的とプロセスを学ぶことである。ツールの違いは方言みたいなもので、使うときに知識として学べばいい。そうしておけばGA、AAだけでなく、どんなツールにも対応できるし、ログ解析に …
続きを読む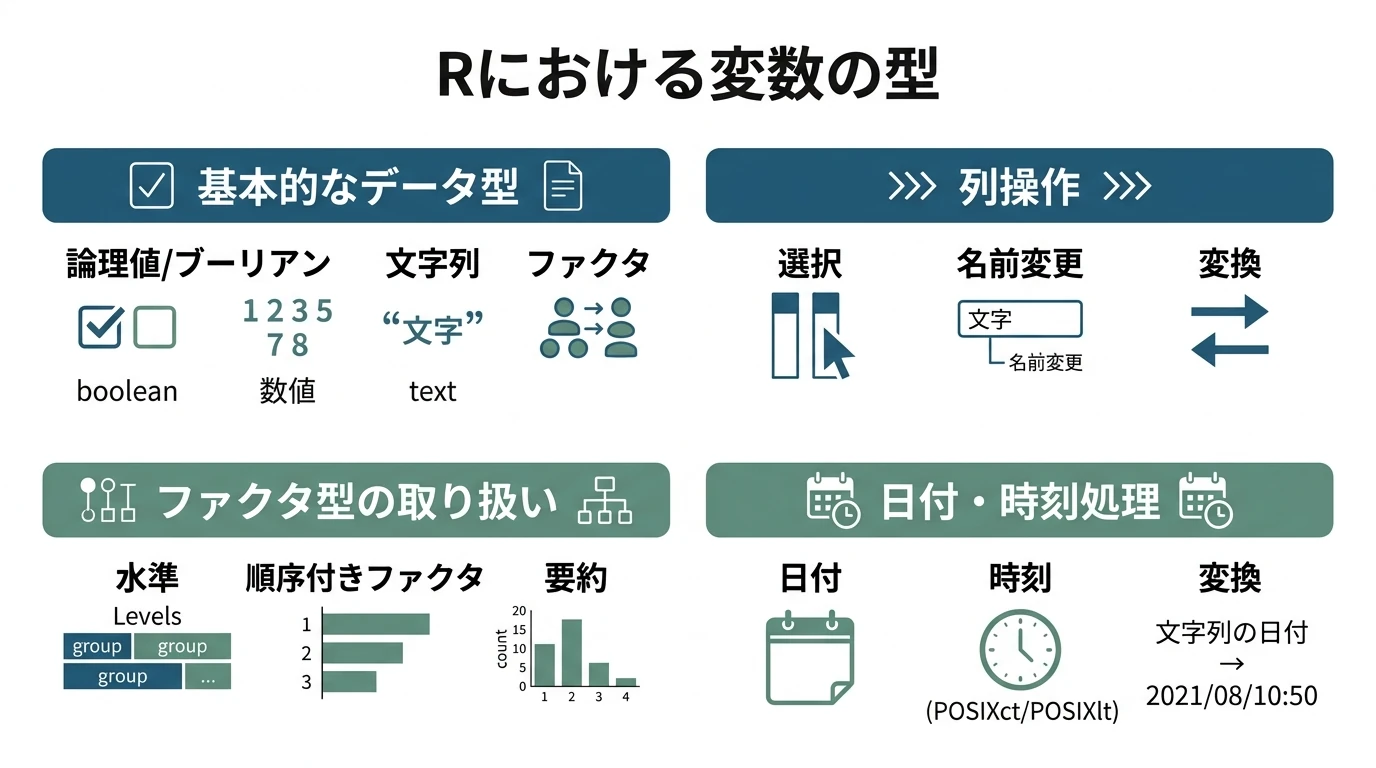
ローデータから分析対象とする変数のみ抽出し(個人情報など、保持すべきでない変数を削除するなど)、情報を失わない範囲で分析するためのデータセットを作る。分析プロジェクトにおけるローデータと同じ量の情報を持つ、整形された(扱いやすい)データセットを作るのである。 この後のデータクレンジング以降で、データの加工方法を変更するなどで手戻りが発生することもある。その際ローデータの読み込みまで戻るのは大変なので、ローデータを同じ情報を持つ、整形された状態のデータを作っておくのが重要である。データクレンジングで手戻りが発生しても、ここで整形したデータセットまで戻ればいい。 dtplyrについて 本記事ではdata.table(例:fread()で …
続きを読む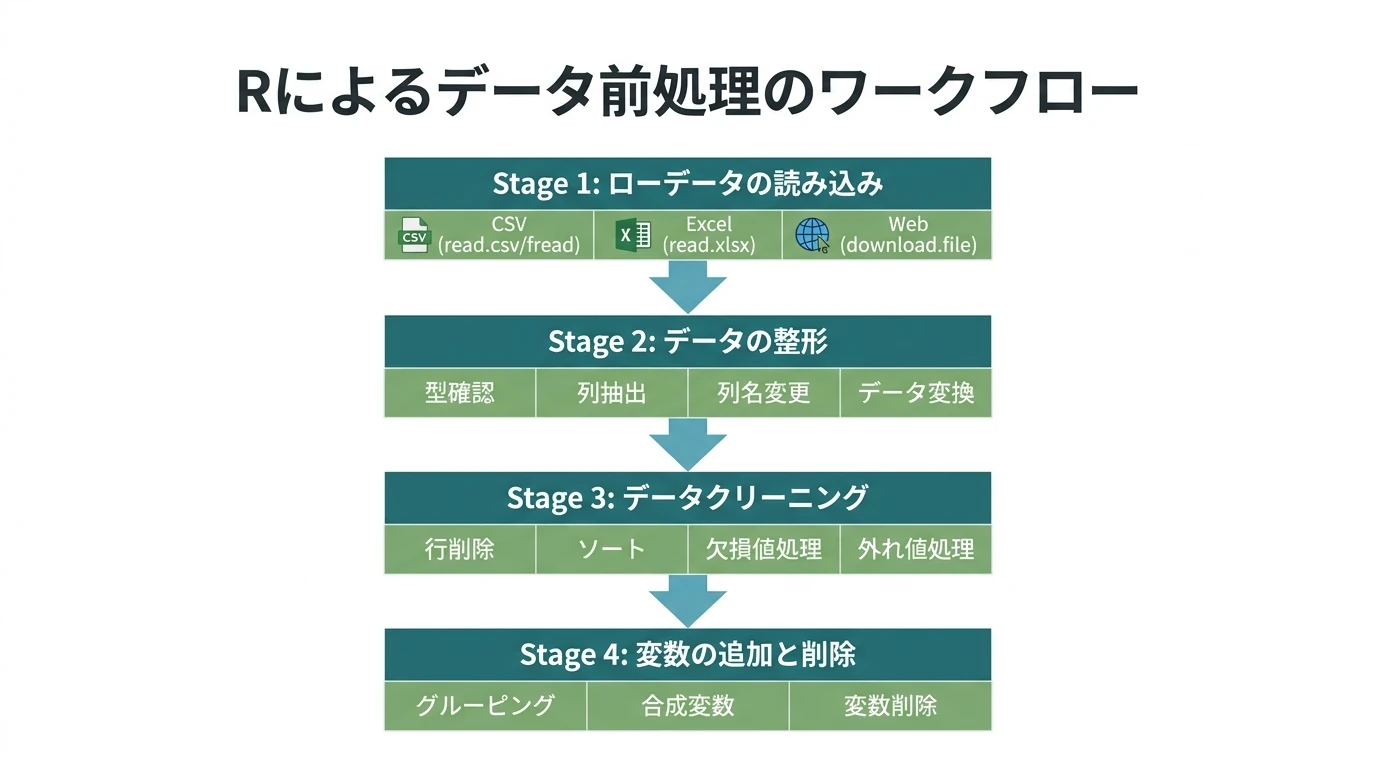
Rを使ったデータ前処理の方法を解説する。 データフレーム形式だけでなく、大きなデータを扱うのに高速なdata.tableを使ったデータの前処理の方法も解説する。 まず一般的にデータの前処理の手順は以下のようなものである。 ローデータの読み込み データの整形(分析用データセットの生成。データの持つ情報は保持) データの型確認 必要な(分析対象とする)列の抽出 列名の変更 データ変換 データの型変換 日時データの生成 因子データの生成(ordered) データクリーニング(正しく分析できるように必要に応じて情報を一部削る) 行の削除(抽出) 行の並べ替え(ソート) 標準化(scale) 欠損値処理 外れ値処理 結合 変数の追加と削除 変 …
続きを読む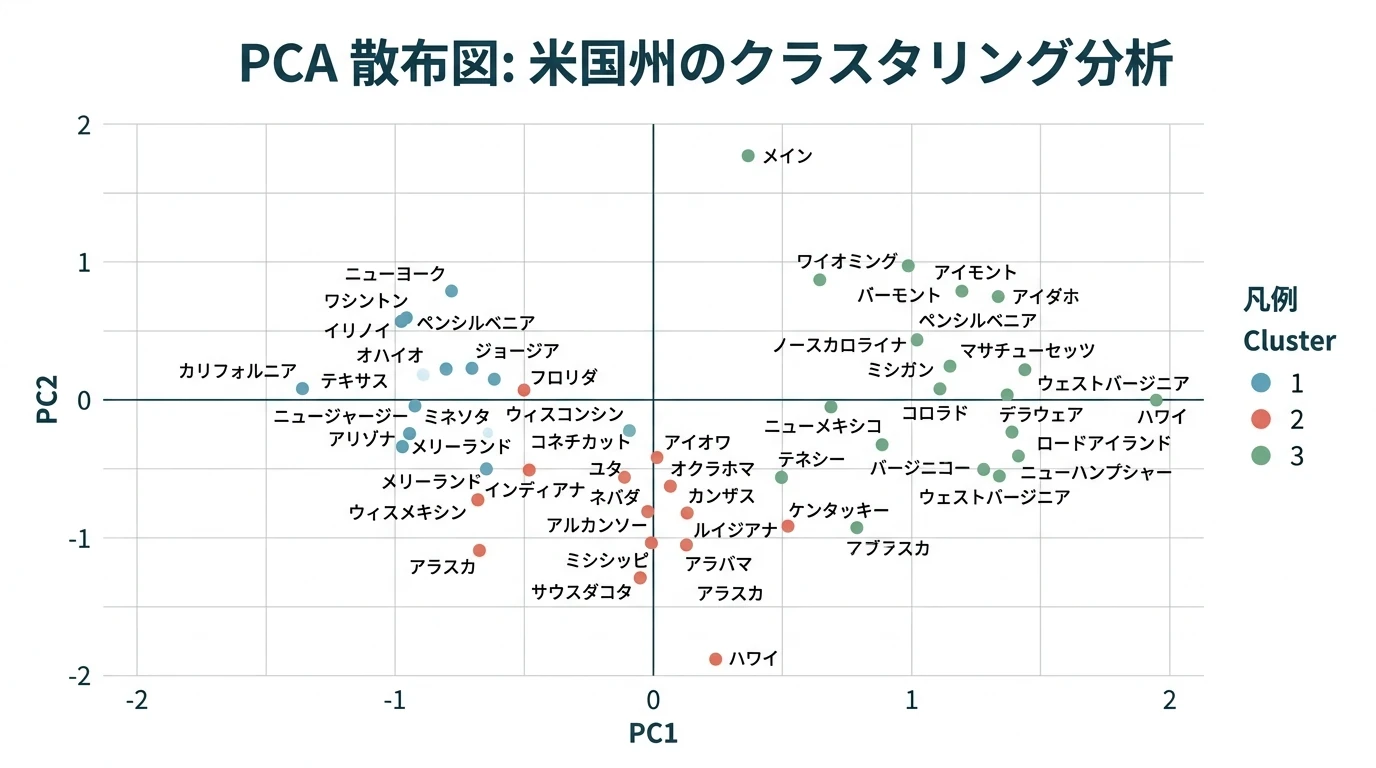
クラスター分析は 距離行列の生成(類似度行列ではない!) クラスタリングの実行 という流れになる。 それぞれのステップで、採用する 距離の種類 クラスタリングの方法 がチューニング変数となる。 この順に手順を見ていく。 行数、列数の多いビッグデータ向きのデータ形式であるMatrixパッケージに対応した距離行列についても説明する。 距離行列を生成する 類似度行列ではなく距離行列を作る。similarityではなくdistanceを作る。 直感的にはデータから距離の指標(どれだけ離れているか)ではなく類似度(どれだけ近いか)の指標を抽出し、そこからクラスタリングしたいケースが多いのだが、あくまで類似度指標に基づいた距離行列を生成するので …
続きを読む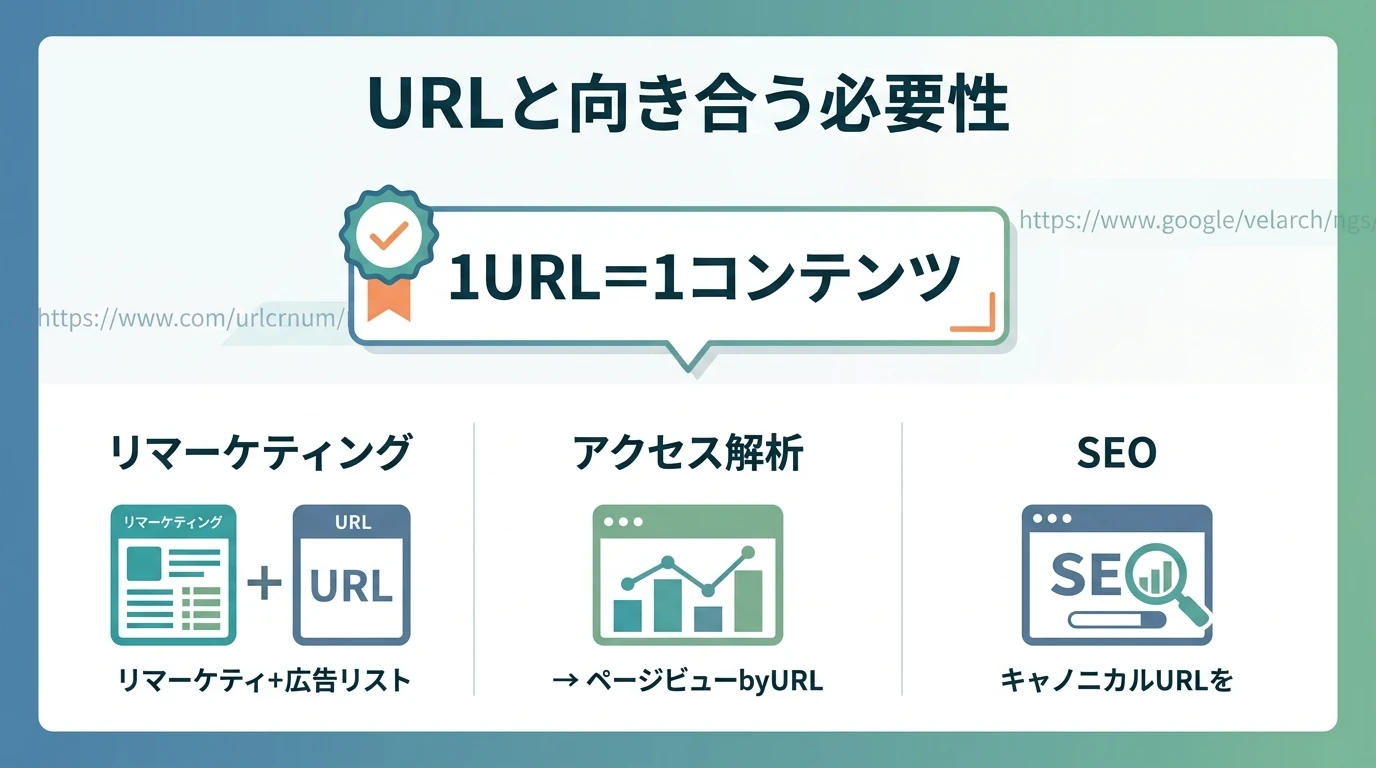
URLと向き合う必要性 URLはインターネット上でページのありかを特定する文字列。サイト制作、コンテンツ管理の観点のみならず、webマーケターにとってもさまざまな集客施策で直面するものである。 リマーケティング広告を配信する際、訪問したURL別にリストを作る アクセス解析においてページビューはURL単位で計測する SEO上はURLの正規化など、特に重要 意外と技術的に込み入ったところがある。 URLの基本は1URL=1コンテンツであり、1URLで複数のコンテンツが対応する(そのURLでアクセスしたときに表示されるコンテンツが時によって異なる)のでもよくないし、複数のURLで同一のコンテンツが対応するのも問題となる。こちらはSEOでは …
続きを読む