
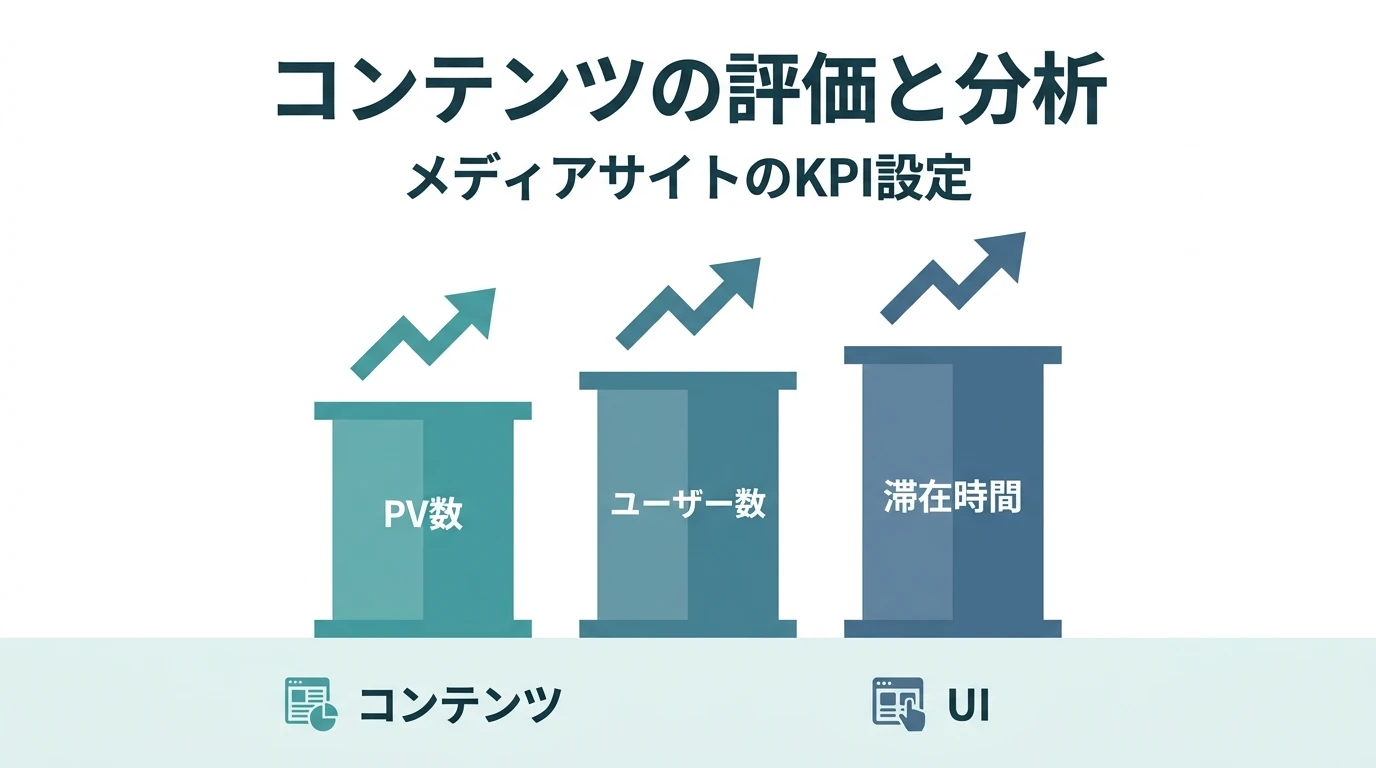
ニュースメディアや雑誌のウェブ版に加え、企業が自社で運営するオウンドメディアも多数存在する。こういったサイトではお問い合わせ、資料請求といった目先のコンバージョンがない。会員登録などはあったとしても、サイト全体のゴールというほどの位置づけではない。 こういった目先のコンバージョンポイントのないメディアサイトのアクセス解析で考慮することを解説する。 メディアサイトの分析で考慮すること メディアサイトのイシュー メディアサイトの運用の主眼はPV数を増やすことに置かれていることが多い。 それ以外ではユーザ数を増やす、滞在時間を上げる、会員数を増やすなどである。 それを実現するためのサイト内での施策は コンテンツ 何がウケるのか、どんな記事 …
続きを読む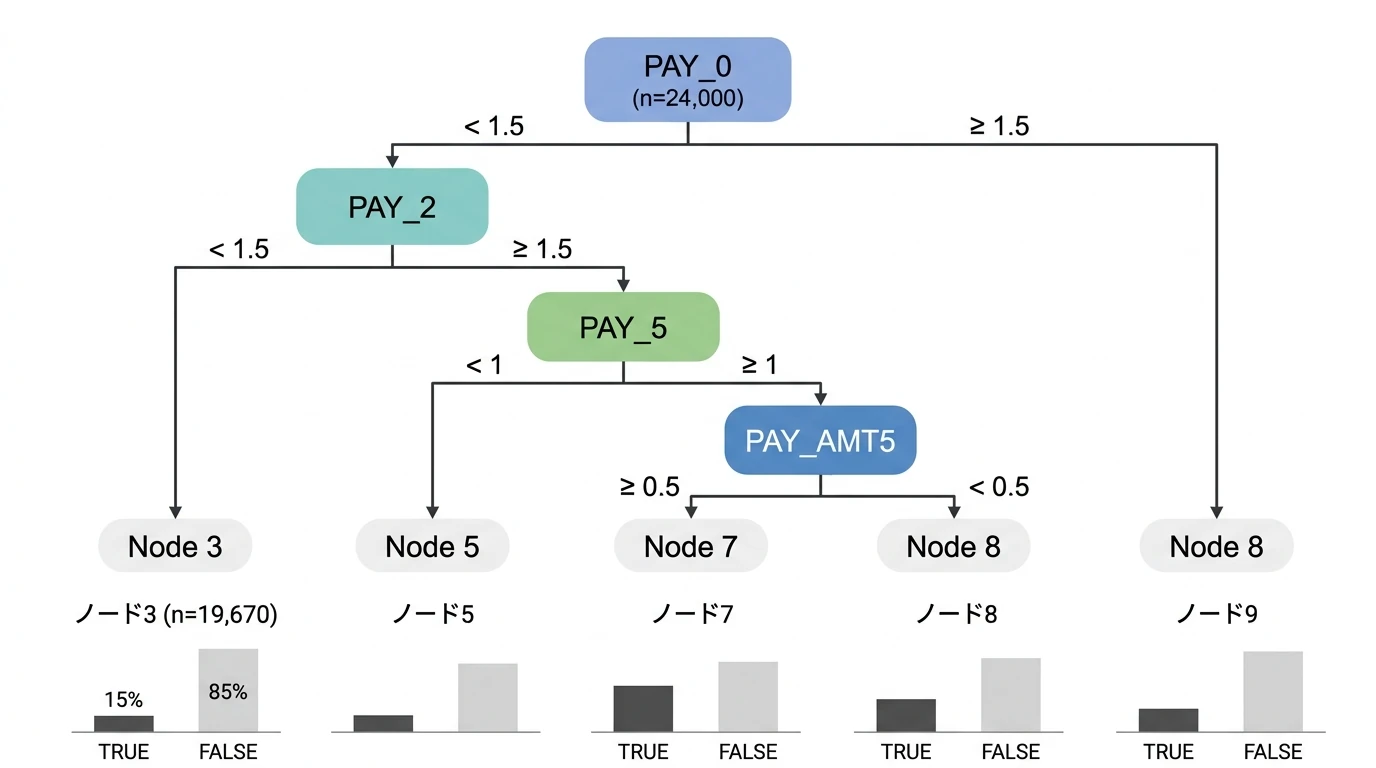
準備 決定木(decision tree)分析をする際、まず目的変数の種類とアルゴリズムを決定する。 アルゴリズム CART CHAID ID3 / C4.5 / C5.0 目的変数の型 目的変数の型によって扱いが変わる 質的変数(2値変数):分類木→目的変数が0/1, T/Fの場合はas.factor()でfactor型にデータ変換しておく 量的変数:回帰木 survivalオブジェクト (生起を表す2カラム) CARTはすべて対応、C4.5/C5.0は質的変数のみ ここではCARTアルゴリズムでツリーモデルを生成するrpartと、ランダムフォレストrangerを中心に説明する。 データセットと前処理 Default of …
続きを読む
GA4 ウェブ計測設計チェックリスト GA4設定前チェックリスト GA4の管理画面にログインする前に決めておくべき要件で、GA4に限らない、計測設計の要件定義である。これを決めずに管理画面を見るのは時間の無駄。このチェックリストを完成させるのに時間を割こう。 重要度:高 工数に影響するもの 計測対象 どのドメイン どのディレクトリ(サブドメインの扱いを含む) クロスドメイン計測の有無(対象ドメインの一覧を事前に洗い出す) おおよそのページ数 サイトの技術構成 ページ遷移方式 ページ遷移時にソフトナビゲーション(History APIやフレームワークのクライアントサイドルーティングによるDOM更新)が発生する箇所があるかどうか。アーキ …
続きを読む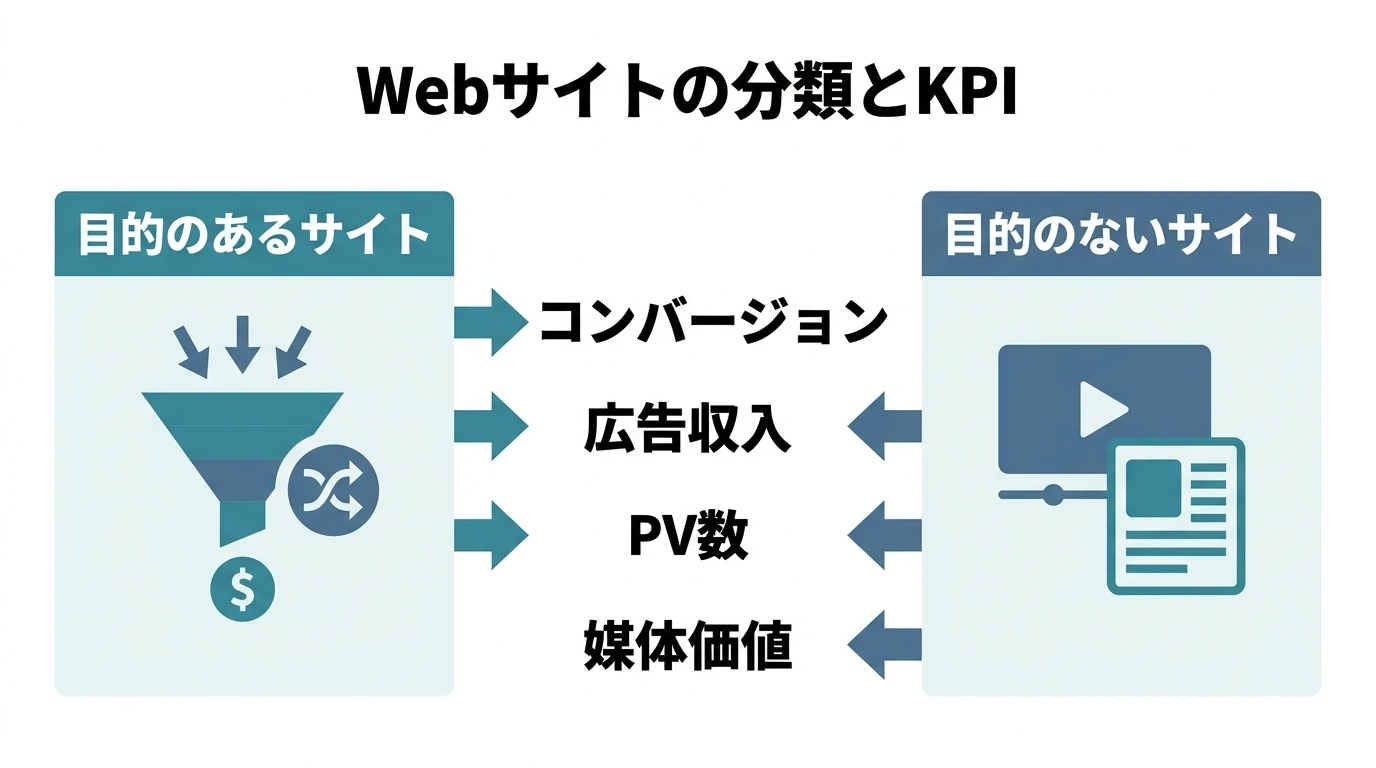
Webサイトの分類とKPIの方向性 目的のあるサイト 特定分野のポータルサイト、情報サイト(比較サイト、不動産ポータルなど) リードを送る 企業サイト ブランド紹介、理解 実店舗誘導 ECサイト リード獲得型(問合せ、資料請求) キャンペーン、プロモーションサイト 知ってもらう 参加してもらう 会員向けサイト 特定の行動 アクティブ率を高める →目的の達成数がKGIになる。KPIはそれを構成する要素。 基本的には目的達成までのカスタマージャーニー、コンセプトダイアグラムを描き、各ステップの到達数を見ていくのがいい。 目的の種類によってセッション限りで達成する場合と、ある程度のリードタイムをもって達成する場合がある。その場合は訪問間隔 …
続きを読む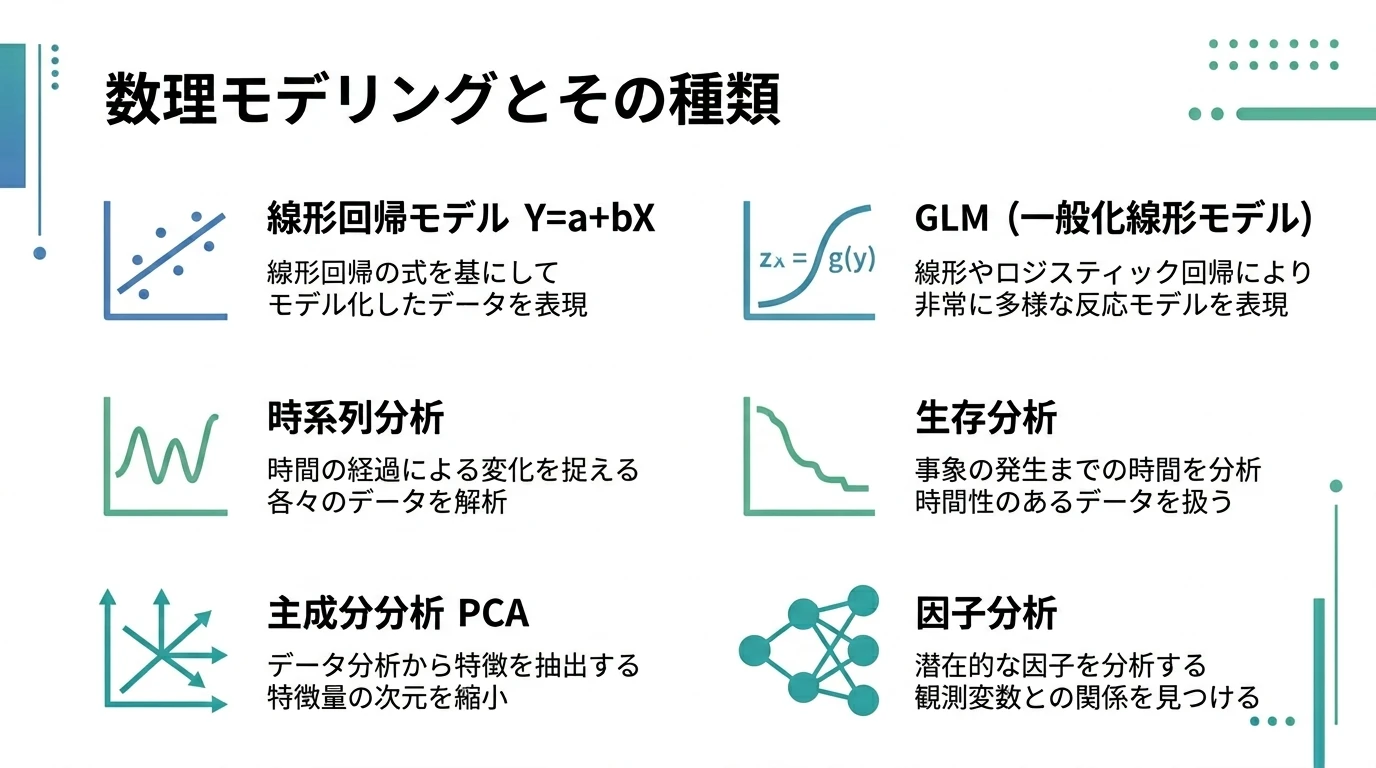
いわゆる回帰分析に代表される数理モデリングとその種類を説明していく。 数理モデリング 数理モデリングの考え方 因果関係を定量化 「Xという要因→Yという結果」という関係を $$Y=a+bX$$ で表す。 X=説明変数(独立変数) Y=被説明変数(従属変数、目的変数) いわゆる「回帰分析」である。 目的 因果関係とインパクトの大きさの特定 予測 モデリングの手続き モデル式の選択(単回帰、ロジット、…) 従属変数の特徴(分布の形状、ばらつき方)によって適切なモデルを選択する パラメータの推定 さまざまな推定法がある(最尤法、最小二乗法) そのモデルでいいか検証 あてはまりのよさ(fit) 決定係数 AIC 残差の評価(独立性、正規性、 …
続きを読む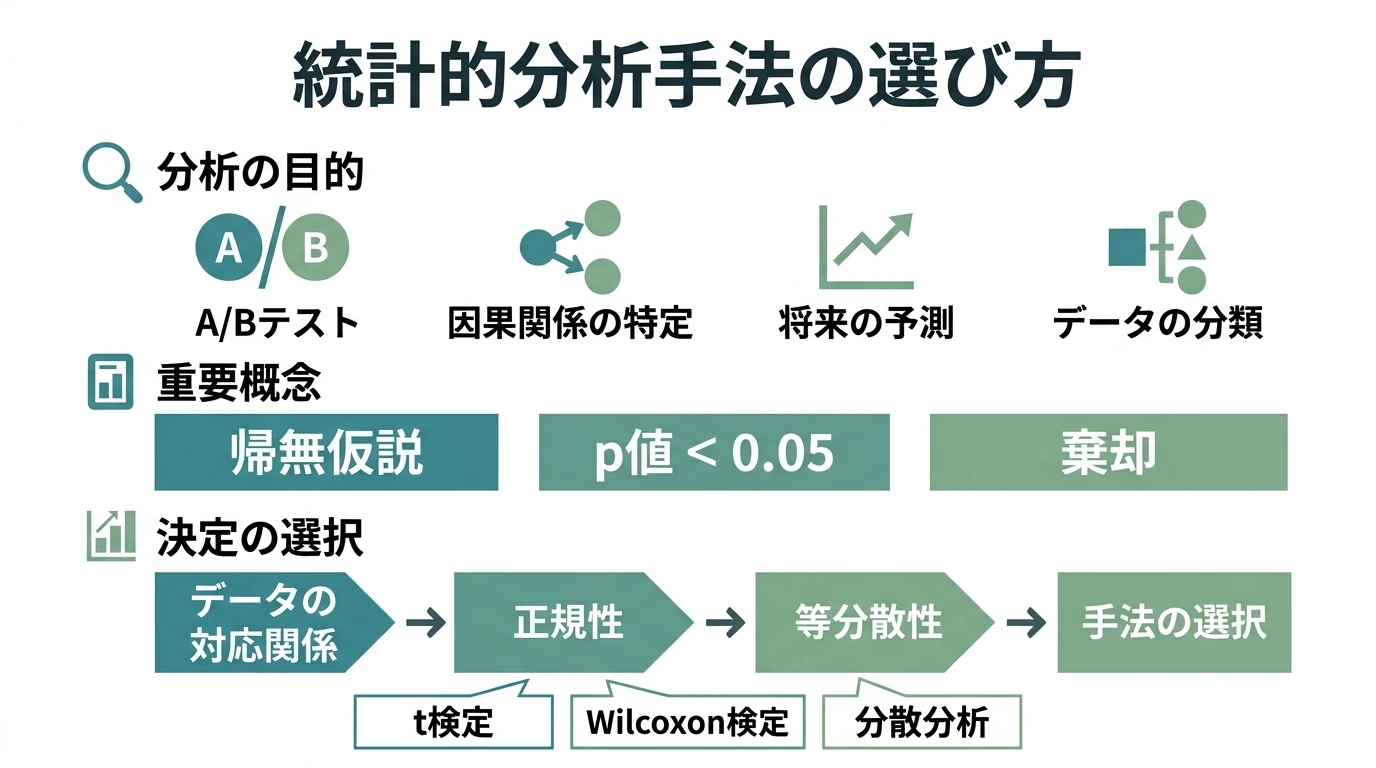
分析手法 目的とデータの性質に基づいて手法を選択 目的 違いがあるか知りたい=A/Bテスト (因果)関係を知りたい=何が効くかを知りたい 予測 分類 従属変数があって、それを分類するもの(クラス分類) 独立変数のみで、似ているものをまとめるもの(クラスタリング) レコメンド データの性質(手法の前提条件) 離散か連続か 正規性 等分散性 従属変数の分布の形状 http://readingmonkey.blog45.fc2.com/blog-entry-262.html 仮説検定 仮説検定とは? 基本的に比較するための方法 「A/Bテスト」→理論的に正確な手順がある。 ※比較する対象は2つ。3つ以上だと別の手法を用いることになる 仮説 …
続きを読む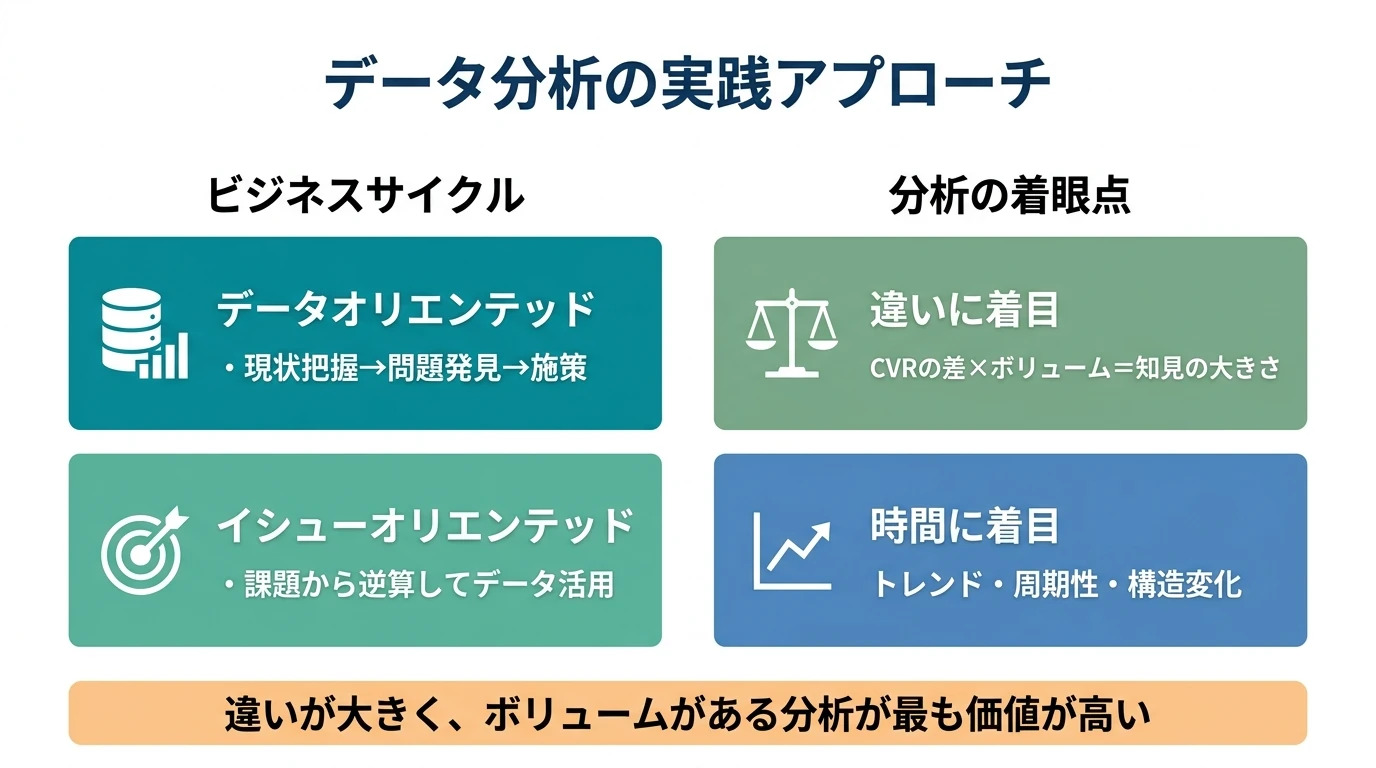
機械学習 「明示的にプログラムしなくても学習する能力をコンピュータに与えること」 つまり1から10までをプログラムしなくても、与えられたデータに基づいてコンピュータが学習し、賢くなっていくようにすることである。具体的には適切な分類、予測、レコメンド、異常検知を行う。また複数の選択肢から適切な選択を行わせるものもある。 学習の仕方による分類 教師あり学習 材料のデータと答えのデータを与えることで、正解率を高めていくものである。さまざまな要因のデータと、それに基づいて実際に発生した結果のデータがあって、要因から結果を分類/予測するケース。ここでは結果が教師データになる。 たとえばEメールの本文テキストがあって、それがスパムかどうか判断す …
続きを読む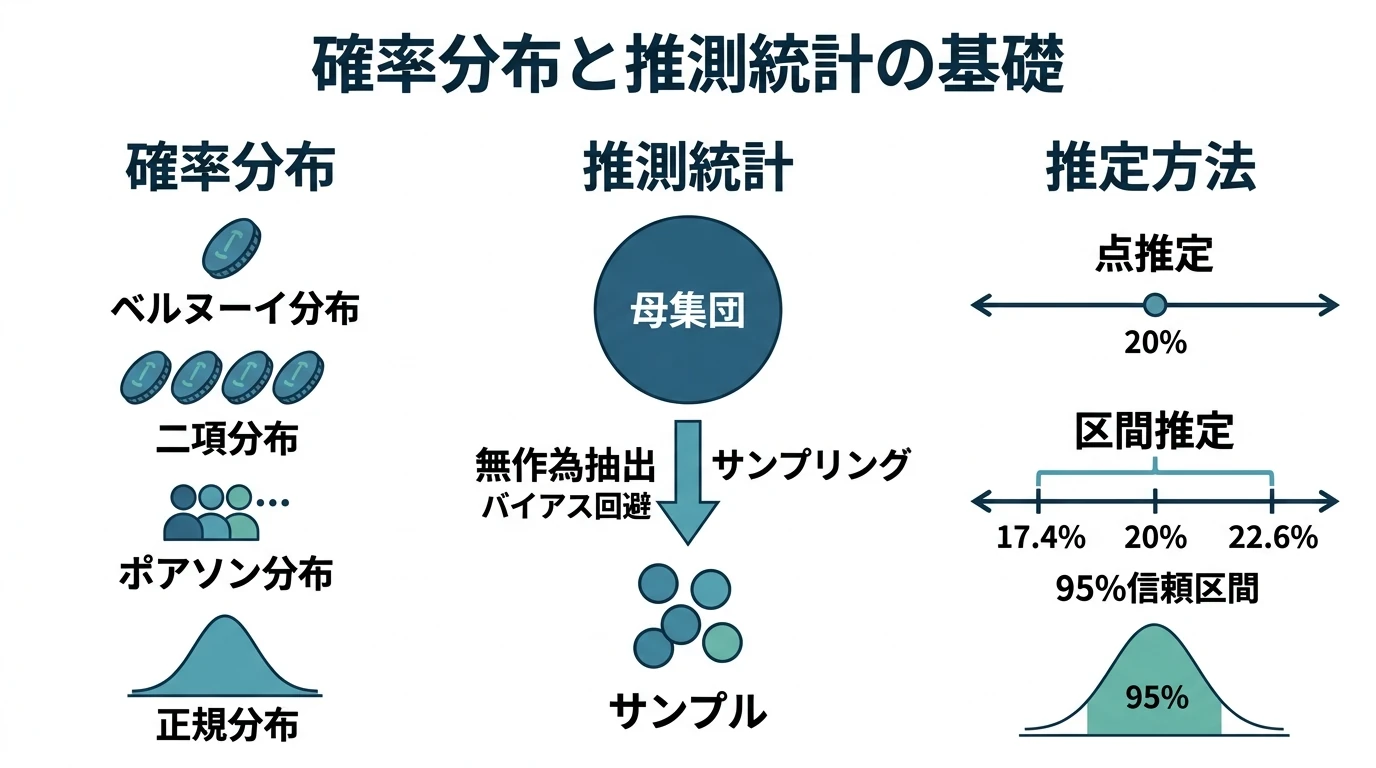
確率分布 これまで「分布」という言葉が何度も出てきたが、この「分布」とは確率分布のことを指している。ここでは具体的なさまざまな確率分布を紹介する。 まず確率分布の定義であるが、確率分布とは、確率変数の各々の値に対する、その生起しやすさをプロットしたものである。そして確率変数とは、確率的に取る値が変わる変数を指す。 発生する事象が確率的に変化するものを想像しよう。その生起しやすさを表すのが確率分布である。 厳密な議論は省略してどのような事象があてはまるか、分布に対するイメージがわかることを目的とする。 離散型確率分布 ベルヌーイ分布 1回の試行で表が出るか裏が出るか 一か八か 成功確率 $p$ の事象が1回の試行で成功するかどうか 期 …
続きを読む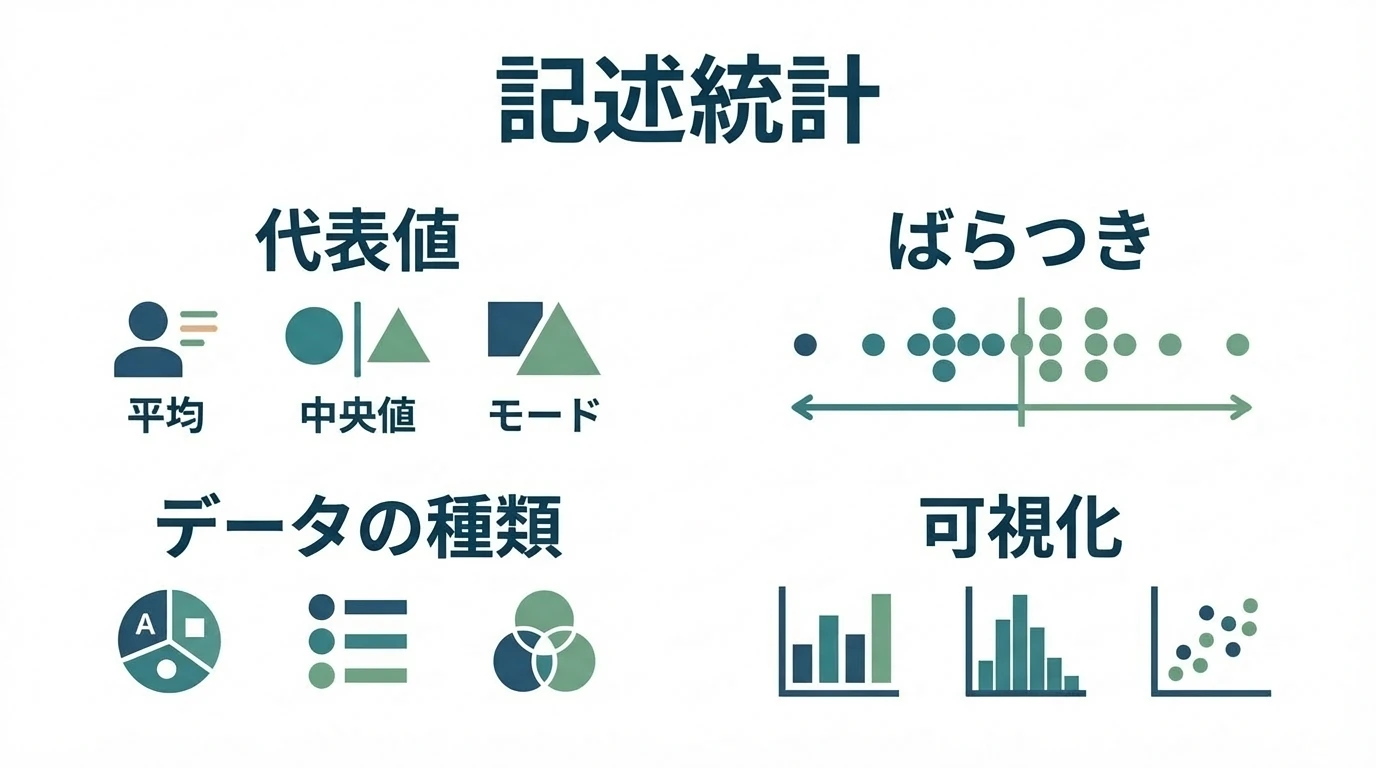
記述統計 統計の手法には記述統計と推測統計があると説明したが、ここでは記述統計の話。記述統計の考え方を通じて、より進んだデータの見方を学んでいく。 記述統計とは 記述統計とはすべてのデータを見て正しく全容を把握・認識するための方法論・作法。 全てのデータを見るのでデータマイニング的なアプローチ。 仮説ありきではないので、記述統計の方法だけではデータの組み合わせが膨大だと有効な知見を得るに至らないこともある。 後でどんな手法を使う際にも、それは推測統計や機械学習の手法を使う場合であっても、データを見るという観点ですべての基本の考え方になる。 データの種類 データは特徴によって分類される。 種類によってデータ加工方法から分析手法も変わっ …
続きを読む