
実際の事象におけるデータの分布と確率分布、一部のデータから全体を推測する考え方
概要
確率分布
これまで「分布」という言葉が何度も出てきたが、この「分布」とは確率分布のことを指している。ここでは具体的なさまざまな確率分布を紹介する。 まず確率分布の定義であるが、確率分布とは、確率変数の各々の値に対する、その生起しやすさをプロットしたものである。そして確率変数とは、確率的に取る値が変わる変数を指す。 発生する事象が確率的に変化するものを想像しよう。その生起しやすさを表すのが確率分布である。 厳密な議論は省略してどのような事象があてはまるか、分布に対するイメージがわかることを目的とする。
離散型確率分布
ベルヌーイ分布
- 1回の試行で表が出るか裏が出るか
- 一か八か
- 成功確率 $p$ の事象が1回の試行で成功するかどうか
- 期待値=$p$、分散=$p(1-p)$
期待値は確率分布の中心的位置を表す。 分散は平均からのバラつきの程度を数量的に表す。
二項分布
(例)平均して打率3割の選手が年間500打席でヒットを打つ回数の分布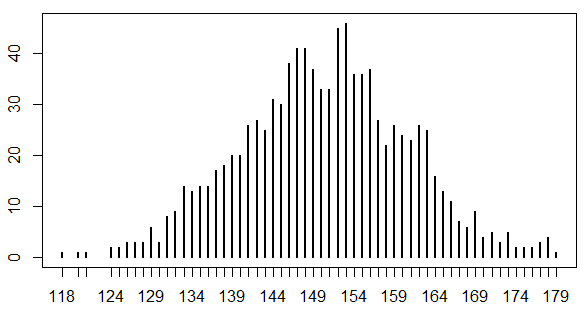
- $n$ 回やって何回成功するか
- 成功確率 $p$ の事象が $n$ 回の試行で成功する回数
- この分布を$Bin(n, p)$と表記
- 期待値=$np$、分散=$np(1-p)$
ポアソン分布
(例)あるサッカーリーグの1試合における得点の分布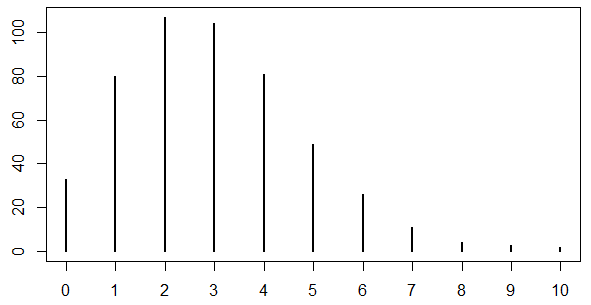
- レアな事象が発生する回数(カウントデータ)
(例)クリック数、1日に受け取るメールの件数 - 二項分布との関係
- 二項分布で $n$ →大、$p$ →小、$np$=一定($\lambda$)のときに該当
- $n$ が変化する事象には不適(インプレッション数が大きく変動する場合だとNG)
- この分布を$Po(\lambda)$と表記
- 期待値=分散=$\lambda$
負の二項分布
(例)あるwebサイトのページごとの1日のPV数の分布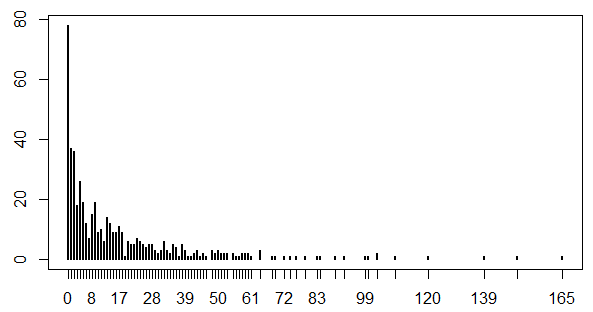
- ポアソン分布と似ているが分散が大きい
- 0が多い
- 大きな外れ値がある
- ゼロが多い、分散が大きいカウントデータに適用
- 成功確率 $p$ の事象が $k$ 回成功するまでに何回失敗するか
連続型確率分布
正規分布
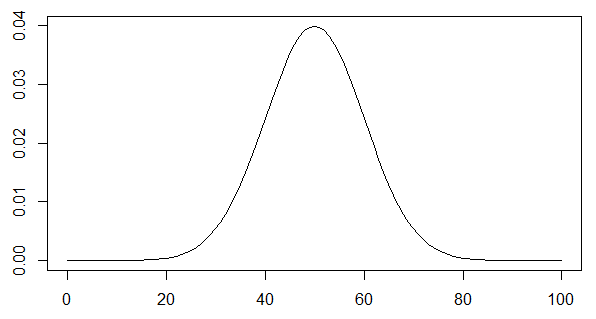
- 分布の王様。理論上いろいろ便利
- 期待値 $\mu$、分散 $\sigma^2$ の正規分布を$N(\mu, \sigma^2)$と表記
指数分布
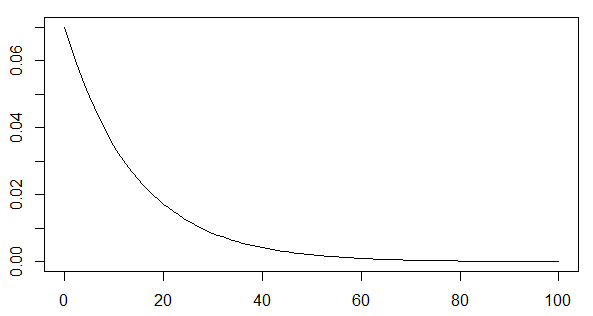
(例)メールを受信する間隔
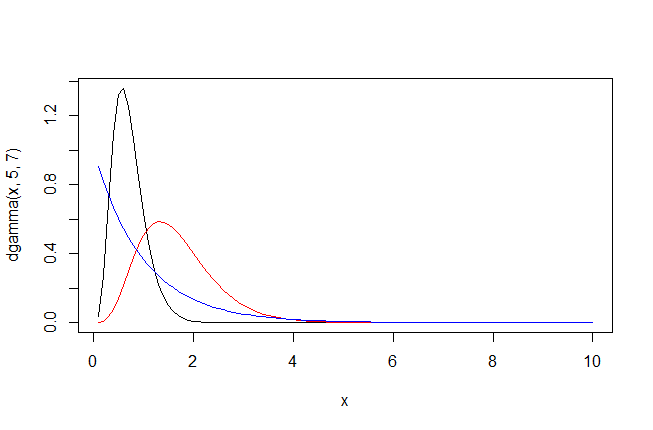
ガンマ分布
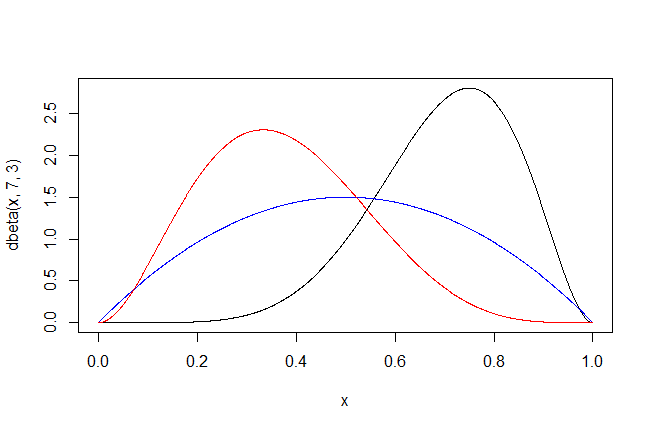
ベータ分布
正規分布
中心極限定理があるため、二項分布やポアソン分布を正規分布で近似することもある。
- 二項分布: $np > 5$ かつ $n(1-p) > 5$ の場合、$Bin(n, p) \rightarrow N(np, np(1-p))$で近似
- ポアソン分布: $\lambda > 10$ の場合、$Po(\lambda) \rightarrow N(\lambda, \lambda)$で近似
中心極限定理
- 正規分布でない分布であったとしても
- 平均 $\mu$ と分散 $\sigma^2$ が存在すれば
- そこからの( $n$ 個抽出した)標本の平均は正規分布$N(\mu, \frac{\sigma^2}{n})$に従う
本来は正規分布でない分布に従うものも平均をとれば正規分布に従うという便利な性質。 これがあるため、中心極限定理が適用可能かどうか吟味せずに何でもかんでも正規分布を仮定する風潮がある。
- データが正規分布に従うことを分析手法が前提としている
- データの分布が正規分布でない
- 平均とは違うもの(式変形しても平均値の定数倍になっていない変数)を見ている
場合、分析手法の選択においても間違いを生じることになる。
Box-Cox変換
平方根をとる、対数変換をかけるなどして、正規分布でないデータを正規分布にあてはまるように変換する。なお、Box-Cox変換は $x > 0$ のデータにのみ適用可能である。 $\lambda \neq 0$ のとき $\frac{x^\lambda-1}{\lambda}$、$\lambda = 0$ のとき $\log(x)$
推測統計
「一部のデータから全体を推測する」お作法 選挙の開票予測、視聴率などそもそも全数データなど取れない場合や、 全数データだと計算しきれない、時間がかかりすぎる場合なども (こちらはコンピュータリソースを割けば何とかなる場合もあるが) 一部のデータに基づいて分析する。 「母集団があって、そこから一部を抽出して、その結果から母集団を推測する」という考え方
- 「一部」=サンプル
- 「母集団を推測する」=母集団の分布や、それを特徴付けるパラメータを推測する
正しく推測するためには、偏りのない抽出(ランダムサンプリング)が必要
データソース、サンプルにかかわる問題
サンプルの偏り
「一部」の抽出に何らかのメカニズムがある場合、サンプルが偏る。バイアスが発生する。
たとえばアンケート調査において、アンケートに回答した人だけを分析対象にするケースを考えよう。アンケートに回答する時点で何らかの志向性がある(関心が高い、時間に余裕がある等)という点で、回答者のみを対象にした分析は母集団を正しく代表しない可能性がある。これは「無回答バイアス」と呼ばれる。
かつてサードパーティDMP(データマネジメントプラットフォーム)が広告ターゲティングに活用されていた時代には、DMPが提供する年収情報の信頼性が問題になることがあった。たとえば、あるDMPの年収データのソースが実は懸賞サイトの登録情報であり、「高年収ターゲティング」で配信した広告が実際にはポイント目的で登録した層に届いていた、といった事例が報告されていた。データソースの素性を知らずにサードパーティデータを鵜呑みにすることの危険性を示す好例である。
インターネット視聴率調査(どのサイトをどのくらいの人数が見ているかを第三者が計測するデータ)にも同様の問題がある。かつてはAlexa Internet(2022年にサービス終了)が代表的な存在であったが、これらの調査はブラウザにツールバーやアプリをインストールした調査パネルの行動履歴をもとに推計するものであった。現在のSimilarWebやヴァリューズ(Dockpit等)のようなサービスでも、調査パネルへの参加は自己選択によるものであり、全インターネットユーザからのランダム抽出ではない。パネル参加者がどのような属性に偏っているかを常に意識する必要がある。
サードパーティデータを利用する際は、その取得方法を確認し、サンプルの偏りを想定することが望ましい。 偏って抽出した調査を行うことで間違った誘導が可能になる。 インターネットのおかげで調査自体は簡単になっているが、同時にバイアスが発生しやすくなっているので気を付ける必要がある。
誤差
日常でよく「誤差」という言葉が使われるが、 厳密に誤差と言われるものには以下の3種類がある。
- 測定誤差:測定方法に起因する誤差。たとえば解析ツールの性質によって生じるもの(ビーコン型であればタグの読み込みのタイミング)
- 計算誤差:コンピュータの計算時に生じる誤差。丸め誤差など。float型(浮動小数点型)の計算では計算誤差が発生する。
- 標本誤差:サンプリングによって生じる誤差。たとえば日本人全員から10人選んで身長の平均値を取る。それを何回か繰り返したら毎回変わる。その違いが「日本人の身長の平均値」の標本誤差。
ランダムに抽出された標本に基づく分析においては、正確に標本誤差を見積もることができる。 その意味でもランダムサンプリングは重要。 計算誤差と標本誤差はあらかじめ想定される範囲が決まっているが、 測定誤差は測定方法によって異なるので測定方法を確認しておく必要がある。
- どのようなメカニズムによる誤差が想定されるか
- 偏りの原因になっていないか
推定
点推定と区間推定
比率データの推定を例にとって、点推定と区間推定の違いを説明する。
ある調査で「視聴率が20%」と報じられたとする。このとき、真の視聴率は「ちょうど20%」なのか、「20%前後のどこかに収まっている」のか。
実際には、サンプル調査から得られた値にはサンプリングに伴う不確実性があり、真の値はある幅をもった区間のなかに収まっていると考えるのが自然である。このようにある程度の幅をもって推測することを区間推定という。サンプルサイズが大きいと、この区間は狭くなる。
これに対して点推定は特定の値を一点で推定すること。しかし実際にその値であることなどほとんどない。
比率データの二項推定の例
比率データは二項分布に従い、正規近似が可能である。 $$Bin(n, p) \rightarrow N(np, np(1-p))$$
手順
- 成功回数 $x \sim B(n, p) \approx N(np, np(1-p))$の $p$ を推定する
- $p$ の推定量を $x/n$ とすると、$x/n \sim N(p, \frac{p(1-p)}{n})$
- いま、$n$ 件のサンプルのうち $x$ 件が成功だったとする。例として $x=180, n=900$ とする。
- $x/n$ の標本平均は0.2なので、$p$ の推定値は0.2。
- $p$ の分散 $\frac{p(1-p)}{n}$ の推定値は$\frac{0.2 \times (1-0.2)}{900} = $ 0.0001778で、 $p$ の標準誤差※は$ \sqrt{0.0001778} = 0.0133$
- $p$ の95%信頼区間は $0.2 \pm 0.0133 \times 1.96$、つまり $0.174$ から $0.226$ の間となる。
※サンプリングに伴う標本平均のばらつき(標準偏差)を標準誤差という。 (標本のばらつきが標準偏差、標本平均のばらつきが標準誤差)
精度とサンプルサイズ
$p$の信頼区間の幅を1/2にするには$p$の分散を1/4にする、そのためにはサンプルサイズを4倍にする必要がある。