
Rのdata.tableはデータフレームを高速に扱えるように改良した形式だが、この機能を提供するdata.tableパッケージには添え字を使ったdata.tableの処理機能だけでなく、さまざまな関数が実装されている。
中にはdata.table以外の形式にも使える関数もあり、
dt[,col1:=関数()]
の形式で使えるdata.table用の関数にも一般的に知られていない便利なものが数多くある。
特に高速化を意識しているものが多く、知っていると処理時間を短縮できる。
data.tableはdplyrとセットで使われることも多いが、dplyr自体はdata.tableの高速仕様にのっとったものではない(tibble形式)ため、正直遅い。
集計など同じアウトプットは出せるが、処理速度に断然違いがあるので、実はdata.tableパッケージを使いこなすのがオススメ(コード自体はdplyrに準拠したほうが読みやすいが)
data.tableのマニュアルの全関数を精査し、一般的に使えそうなもののみをピックアップしてまとめた。
目次
ファイル入出力
ファイルを読み込んでdata.tableを生成するfread()関数
data.tableだけでなくデータフレームもCSVファイルに出力できるfwrite()関数
dt1 <- fread('data.csv')
fwrite(dt1, file='data.csv')
参照で値が書き換わる対策
setDT()などの時に参照で書き換わってしまうため、退避させたいときにcopy()を使う
dt1 <- data.table(x1=1:3, y1=4:6)
dt2 <- dt1
dt3 <- copy(dt1)
setDF(dt1)
class(dt2)
'data.frame'
class(dt3)
'data.table', 'data.frame'
dt2の参照がdt1なのであり、dt1を書き換えるとdt2も書き換わってしまう。
そこでcopy()関数を使ってdt3を生成しておくと、元のdata.tableとして保持されている。
特殊な構文
%を使った構文や.SDなどのシンボル
絞り込み条件
文字列比較(data.table以外のデータ形式でも使える)
値が指定した集合(ベクトル)に含まれるかどうかの判定。文字列では%in%でなく%chin%を使うと高速。
%like%を使うと正規表現マッチが使える。stringr::str_match()などより構文上使いやすい。
dt1[col1 %chin% c('Jan', 'Feb'),]
dt1[col1 %like% '^(Jan|Feb)',]
数値比較(data.table以外のデータ形式でも使える)
%between%が特徴的。以下の例ではcol1 >=2 & col1 <= 5と同じ。
dt1[col1 %between% c(2,5),]
dt1[col1 %in% 2:5,]
特殊なシンボル
.SD.BY.N.I.GRP
日時
Rの日時処理では時間がかかることが多いが、それを高速化した拡張形式を提供している。
data.tableの中以外でも使えるのでおすすめ。
高速なDate形式: IDate形式
DateはIDate形式にしておくと高速に扱える。以下のようにDateとして認識できる文字列をそのまま引数にしてもいい。
as.IDate("2001-01-01")
as.IDate("20010101", format="%Y%m%d")
高速なTime形式: ITime形式
時刻はITime形式にしておくと高速に扱える。ただし日付情報は保持していない(日内の時刻)のでタイムスタンプとしてはIDateとセットで使う必要がある。
as.ITime("10:45")
as.ITime("104522", format="%H%M%S")
IDateとITimeを合わせた日時形式はないので、日時にするには
as.POSIXct("2001-01-01") + as.ITime("10:45")
でPOSIXct型にできる。
時系列
data.tableをxts形式と相互変換できる。
xts -> data.table
as.data.table.xts(xts1)
data.table -> xts
as.xts.data.table(dt1)
縦横変換
data.tableに対するdcast()/melt()は以下の関数を使うと高速になる。
dcast.data.table()melt.data.table()
使い方は{reshape2}パッケージのdcast()/melt()と同じ。
ランキング系
順位
frank(vec1, na.last=TRUE, ties.method=c("average","first", "random", "max", "min", "dense"))
これはdata.table以外のデータでも高速に使えるので活用するといい。
data.tableの順位は直感的に
dt1をcol1で昇順、col2で降順に並べた順位
frankv(dt1, col1, -col2, na.last=TRUE, ties.method=c("average","first", "random", "max", "min", "dense"))
na.last=TでNAは最後の順位にまとめられる。na.last=FでNAは最初の順位にまとめられる。ties.methodで同順位の扱いを指定できる。
ソート
fsort(vec1, decreasingDecreasing =FALSE, na.last=TRUE)
data.table以外のデータでも高速に使えるので活用するといい。
最初と最後
first()last()
グルーピング
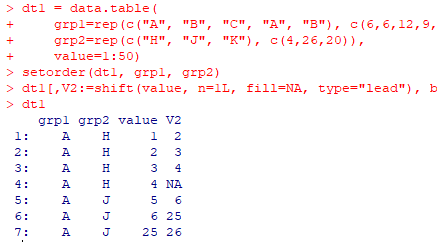
dt1 = data.table(
grp1=rep(c("A", "B", "C", "A", "B"), c(6,6,12,9,17)),
grp2=rep(c("H", "J", "K"), c(15,15,20)),
value=1:50)
グループID
dt1[,group_id := rleidv(.(grp1, grp2))]
グループ内の行ID
dt1[,row_id := rowidv(.(grp1, grp2))]
前後を取得
dt1[,shift(value, n=1L, fill=NA, type=c("lag", "lead", "shift")), by=.(grp1, grp2)]
並べ替え
列の並べ替え
setcolorder(dt1, neworder=c('col2','col1','col3'))
行の並べ替え
setorder(dt1, col2)
転置
transpose(dt1)
行方向に連結
L1 <- list(dt1, dt2)
dt3 <- rbindlist(L1)
文字列の分割
文字列のフィールドを区切り文字を指定して分割し、個別のフィールドとして代入する時に使う。
dt2 = data.table(x=c("A/B", "A", "B"), y=1:3)
dt2[, c("c1", "c2") := tstrsplit(x, "/", fixed=TRUE)]
dt2
x y c1 c2
1: A/B 1 A B
2: A 2 A <NA>
3: B 3 B <NA>
高度な集計
frollmean(x, n, fill=NA, algo=c("fast", "exact"), align=c("right","left", "center"), na.rm=FALSE, hasNA=NA, adaptive=FALSE,verbose=getOption("datatable.verbose"))
frollmean()frollsum()
ROLLUP, CUBE, and GROUPING SETS
rollup(x, j, by, .SDcols, id = FALSE, ...)
cube(x, j, by, .SDcols, id = FALSE, ...)
groupingsets(x, j, by, sets, .SDcols, id = FALSE, jj, ...)
システム
data.tableは実はマルチスレッドを前提として動作している。
マルチスレッドの設定状況
getDTthreads()
スレッド数を指定
setDTthreads(3)
現存するdata.tableのサイズなど一覧を取得
tables()
データの加工や分析で使うRの使い方 の記事一覧



