
Rで時系列分析の簡単なまとめ
概要
時系列のアプローチ
- 単系列
- ざっと見る
- 定常性の確認
- ARIMA/SARIMAモデルをあてはめる
- 複数系列の関係→VAR(ベクトル自己回帰)モデル
- その他の変数がある(時系列+回帰)→状態空間モデル
- (単なるラグ変数回帰→目的変数自体の時系列性が反映されない)
ライブラリ{forecast}を使う
以下、データはy.tsとする
時系列のデータ形式
時系列データにはいくつかの形式がある。
- ts: Rの基本の時系列オブジェクト。ほとんどの時系列ライブラリはこの形式の時系列データを扱う
- xts: データフレームとtsの間に位置づけられる、時系列データを便利に扱えるようにした形式
- zoo: データフレームとxtsの間の形式
われわれが一般的に扱うデータ形式はデータフレームで、時系列データも元はCSVやデータベースなどからデータフレームの形式で与えられることが多い。たとえば日付を表す列と値の列がそれぞれ存在したり、1枚のデータフレームに複数列(つまり複数の時系列変数)が収まっていたりする。一方でtsは単系列で日付データではなくサイクルの周期を属性として持つなど、データフレームとは形式が大きく異なり、そのままでは扱いにくい。zooは直接知らなくてもいい。
xts = ts+カレンダー機能+複数系列
データフレームをxtsに変換する
read.zoo()を使う
データフレームx.dfをxts形式のx.xtsに変換
as.xts(read.zoo(x.df))
x.dfに日時形式の列(Date, POSIXct)が含まれていればその列が時を表すindexになる。時を表すカラムは
as.xts(read.zoo(x.df, index.column = 2))
などのように番号や列名でも指定できる。
data.tableを使う
日時を表す列(Date, POSIXct)を含むdata.table形式であればas.xts.data.table()で直接xtsに変換できる。
as.xts.data.table(x.dt)
xtsオブジェクトからtsオブジェクトを生成する
var1.ts <- ts(x.xts[,'var1'], freq=7)
ざっと見る
コレログラム
acf(y.ts)
トレンド成分、季節成分を抽出してプロット
x.stl <- stl(y.ts,s.window="periodic")
plot(x.stl)
定常性の確認
- ADF検定
- KPSS検定
定常になるまで階差を取る
ARMA/ARIMA/SARIMAモデル
パラメータを以下の通りとする SARIMA(p,d,q)(P,D,Q)
- p: p for AR(p)(自己回帰部分の次数)
- q: q for MA(q)(移動平均部分の次数)
- d: diff(d階の階差モデル)
- P: P for AR(P) of seasonal part(季節成分の自己回帰部分の次数)
- Q: Q for MA(q) of seasonal part(季節成分の移動平均部分の次数)
- D: diff of seasonal part(季節成分の階差の階数)
次数を指定して推定
arima()を使う
ARIMA
model1 <- arima(y.ts, order=c(p,d,q))
SARIMA
12期間周期の季節成分
model1 <- arima(y.ts, order=c(p,d,q), seasonal=list(order=c(P,D,Q), period=12))
次数も自動で算出
auto.arima()を使う
model1 <- auto.arima(
y.ts,
ic = 'aic', # モデル選択で使う情報量基準。'aic', 'aicc', 'bic'から選択
trace = T, # 計算履歴を表示。デフォルトでFALSE
stepwise = F, # FALSEで総当たり、TRUE(デフォルト)でstepwise(高速)
approximation = F,
d = 1, # 指定するとN階の階差、デフォルトで自動計算
start.p = 0, # AR(p)の次数の計算スタート
start.q = 0, # MA(q)の次数の計算スタート
start.P = 0, # 季節部分のAR(P)の次数の計算スタート
start.Q = 0, # 季節部分のMA(Q)の次数の計算スタート
seasonal = T, # FALSEでARIMA(デフォルト)、TRUEでSARIMA
xreg=x.xts # 回帰要素を入れることもできる。形式はxtsで指定
)
時系列に従う乱数の生成
arima.sim()を使う
ts.sim <- arima.sim(n=乱数の数, model=list(order=c(p,d,q), ar=c(ARの係数), ma=c(MAの係数)), sd=sqrt(1))
予測値
50%信頼区間、95%信頼区間も一緒に50期間先までプロット
x_ts.pred <- forecast(model1, level = c(50, 95), h = 50)
プロット
plot(x_ts.pred)
参考
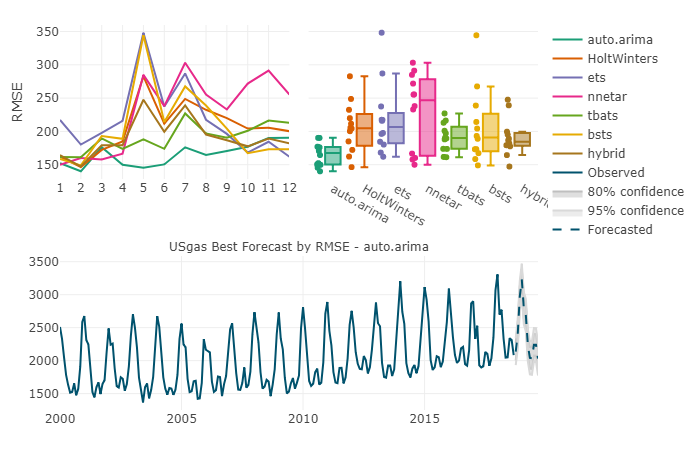
TSstudioを使って
時系列分析の便利なライブラリTSstudio 時系列を可視化するのに便利なチャートをplotlyできれいに出力してくれるし、いろいろな時系列モデルを一気に作って比較することもできる。 生成できる時系列モデルは以下のとおり
- auto.arima (forecast package)、回帰成分も指定可能
- Bayesian Structural Time Series (bsts package) 、回帰成分は指定不可
- ets (forecast package)
- hybrid timse series model (forecastHybrid package) 、回帰成分も指定可能
- Neural Network Time Series (forecast package) 、回帰成分も指定可能
- tbats (forecast package)
- Holt Winters (stats package)
多変量時系列(VAR:ベクトル自己回帰モデル)
ライブラリ{vars}を使う
# データの読み込み
## Excelからカンマ付きフォーマットされた数値をクリップボード経由で読み込む例
traffic <- read.table("clipboard", header=T)
traffic <- sapply(traffic, function(x) as.integer(gsub(',', '', x)))
require(vars)
# 1. 最初に次数を決める
VARselect(traffic, lag.max=5)
# 2. モデルを推定する
traffic.var = VAR(traffic, p=4)
summary(traffic.var)
plot(traffic.var)
# 残差間の相関は小さいほうがいい
# 3. 解釈:インパルス応答推定(時間を経ると影響がどのようになるか)
traffic.irf = irf(traffic.var, n.ahead=4, ci=.95)
plot(traffic.irf)
# 4. 予測
predict(traffic.var, n.ahead=4, ci=0.95, dumvar=NULL)
状態空間モデル
時系列+外生変数(要因となる変数=回帰の説明変数)
ライブラリ{bsts}が使いやすいし、正規分布以外(ロジスティック分布、ポアソン分布)にも適用できる。
状態空間モデルを扱うライブラリは他に{dlm}, {KFAS}もあるが、モデルの指定などがやりにくい。KFASはパラメータの推定の手順が難しい
時系列の成分を
- ローカルモデル
- 周期成分
- 自己回帰部分
- 回帰部分
- 日次データにおける休日効果
に分け、それぞれの変数があるかどうかを検討する。
基本的なモデルの作り方
- データフレーム
df - 目的の時系列の列名が
sales
という場合
list() |>
AddXXXXX(y=df$sales, その他パラメータ) |> # 成分を指定1
AddXXXXX(y=df$sales, その他パラメータ) |> # 成分を指定2
:
-> bsts_model_spec
bsts_model <- bsts(formula=sales ~ 回帰部分の説明変数, state.specification=bsts_model_spec, niter=10000, data=df)
たとえば
list() |>
AddLocalLevel(y=df$sales) |> # ローカルレベルモデル
AddSeasonal(nseasons=4, y=df$sales) |> # 季節成分
AddAutoAr(y=df$sales) -> bsts_model_spec # 自己回帰部分(次数は自動で算出)
bsts_model <- bsts(formula=sales ~ spend + spend_lag1q + spend_lag2q + spend_lag3q, state.specification=bsts_model_spec, niter=10000, data=x)
回帰部分の説明変数欠損値が含まれているとエラーになる。
成分の指定
- ローカルモデル
AddLocalLevel(y): ローカルレベルモデル(傾きゼロ=トレンドなし)AddLocalLinearTrend(y): ローカル線系トレンドモデル(トレンドあり)AddSemiLocalLinearTrend(y)(旧AddGeneralizedLocalLinearTrend(y)): レベルが【ランダムウォーク】+【AR1過程に従う傾き】
- 周期成分
AddSeasonal(y, nseasons=4, season.duration=3): 通常の各季節のフラグ付け(この例では月次データで1シーズン3か月×4シーズンある場合)AddTrig(y, period=12, frequencies=1:3): 季節成分を三角関数で表す(この例では12か月で1区切り、12か月で1サイクル、2サイクル、3サイクル)→https://rdrr.io/cran/bsts/man/add.trig.html
- 自己回帰部分
AddAutoAr(y): 次数自動AddAr(y, lags=1): 次数指定(この例では1次の自己回帰)
日次データ(yが日付情報付きxtsデータ)の場合、休日効果と月効果を簡単に指定できる。
- 休日効果
AddRegressionHoliday(y, holiday.list): 固定の休日効果AddHierarchicalRegressionHoliday(y, holiday.list): 分布に従う(ランダムな要素を含む)休日効果AddRandomWalkHoliday(y, holiday): 祝日がランダムウォーク系列に従う。祝日の系列は複数設定でき(祝日の系列と日曜の系列など)、それぞれの系列がランダムウォークに従う
- 月効果
AddMonthlyAnnualCycle(y)
複数の種類の休日がある場合の扱い(祝日、日曜、土曜)
AddRandomWalkHoliday()の場合
list() |>
AddRandomWalkHoliday(y, 祝日系列) |>
AddRandomWalkHoliday(y, 日曜系列) |>
AddRandomWalkHoliday(y, 土曜系列) |>
:
AddRegressionHoliday(), AddHierarchicalRegressionHoliday()の場合
list() |>
AddRegressionHoliday(y, list(祝日系列, 日曜系列, 土曜系列)) |>
:
となる。 休日オブジェクトは
FixedDateHoliday()NthWeekdayInMonthHoliday()LastWeekdayInMonthHoliday()NamedHoliday()DateRangeHoliday()
https://www.rdocumentation.org/packages/bsts/versions/0.8.0/topics/holiday の関数で生成できる。
回帰部分
回帰係数がランダムウォークに従う場合
list() |>
AddDynamicRegression(y ~ 説明変数) |>
:
回帰係数が固定の場合、
bsts(..., formula=y ~ 説明変数)
で指定する。
分布の指定
時系列変数の分布は正規分布以外も指定できる。
bsts(..., family = "logit")
- family
- “gaussian”: 正規分布
- “logit”: ロジットモデル
- “poisson”: ポアソン分布
- “student”: t分布
アウトプット
bstsオブジェクト
モデルの評価
プロット
burn_value <- SuggestBurn(0.1, bsts_model2)
plot(bsts_model, 'state', burn=burn_value)
plot(bsts_model, 'coef', burn=burn_value)
plot(bsts_model, 'seasonal', burn=burn_value)
plot(bsts_model, 'components', burn=burn_value)
plot(bsts_model, 'residuals', burn=burn_value)
plot(bsts_model, 'predictors', burn=burn_value)
plot(bsts_model, 'size', burn=burn_value)
plot(bsts_model, 'dynamic', burn=burn_value)
plot(bsts_model, 'prediction.errors', burn=burn_value)
plot(bsts_model, 'forecast.distribution', burn=burn_value)
colMeans(bsts_model$coefficients[burn_value:10000,]) |> sort(dec=T)
summary(bsts_model, burn=burn_value)
複数のモデルの比較
CompareBstsModels(list(bsts_model1, bsts_model2))
CompareBstsModels(list(`Model 5`=bsts_model5, `Model 6`=bsts_model6, `Model 7`=bsts_model7, `Model 8`=bsts_model8))
各成分の平均
# bsts_model1$state.contributions [1,,1] |> names
trend = colMeans(bsts_model$state.contributions[burn_value:10000,'trend',])
seasonal = colMeans(bsts_model$state.contributions[burn_value:10000,'seasonal.4.1',])
ar1 = colMeans(bsts_model$state.contributions[burn_value:10000,'Ar1',])
reg = colMeans(bsts_model$state.contributions[burn_value:10000,'regression',])
total = trend+seasonal+ar1+reg
apply(cbind(trend, seasonal, ar1, reg), mean, MARGIN=2)/mean(total)
lapply(c(trend, seasonal, ar1, reg), mean)/mean(total)
予測
predict(bsts_model, horizon = 4, newdata = new_data, burn = burn_value, quantiles = c(.025, .975)) |> plot
参考
bsts
- https://ill-identified.hatenablog.com/entry/2017/09/08/001002
- https://tjo.hatenablog.com/entry/2017/03/07/190000
- https://www.unofficialgoogledatascience.com/2017/07/fitting-bayesian-structural-time-series.html
KFAS
- https://ill-identified.hatenablog.com/entry/2017/09/24/215620
- https://logics-of-blue.com/how-to-use-kfas/
- https://www.jstage.jst.go.jp/article/seitai/66/2/66_361/_pdf
- https://elsur.jpn.org/ck/
係数まで算出するとなるとコーディングが面倒
補足: fable/tsibbleエコシステム
forecastパッケージの開発者Rob Hyndmanらは、{fable}と{tsibble}を中心とした新しい時系列エコシステムをforecastの後継として開発している。forecastを新規に使うことは依然として妥当だが、tsibble形式(tidyな時系列データ)やfableによるモデリングについても知っておくとよい。