データ分析の目的、考え方、フレームワークと統計
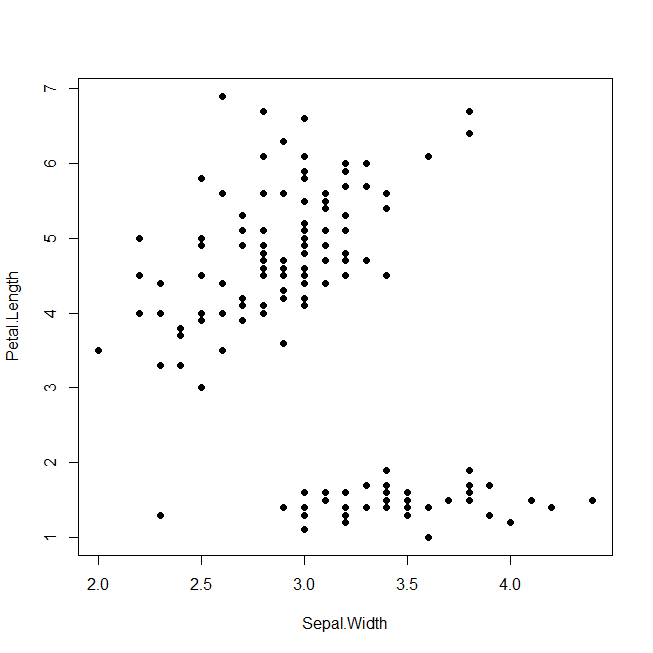
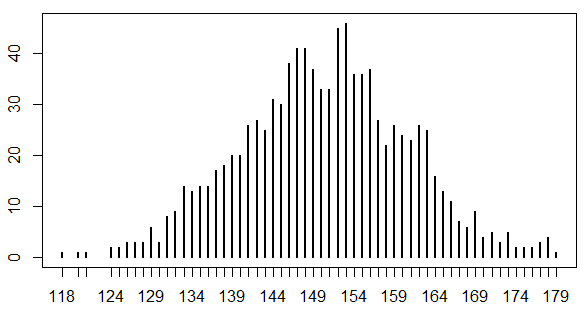
データ分析の考え方 昨今もてはやされている「データ分析」というキーワード。 これを読んでいる方々はデータ分析に対してどのようなイメージをお持ちだろうか? データ分析がビジネスの課題を何でも解決してくれるのだろうか? データ分析には役割と守備範囲、正しい手法というものが決まっている。 間違った使い方をすると間違ったインサイトを導き出すことになる。 何でもデータ分析が解決してくれるわけではなく、データ分析の守備範囲とそうでない部分は峻別しなければならない。 データ分析を正しく理解して実務に役立てていくために実務上、最低限抑えておけばいいところをまとめていく。 そもそもデータ分析とは何なのかを整理し…