
機械学習 「明示的にプログラムしなくても学習する能力をコンピュータに与えること」 つまり1から10までをプログラムしなくても、与えられたデータに基づいてコンピュータが学習し、賢くなっていくようにすることである。具体的には適切な分類、予測、レコメンド、異常検知を行う。また複数の選択肢から適切な選択を行わせるものもある。 学習の仕方による分類 教師あり学習 材料のデータと答えのデータを与えることで、正解率を高めていくものである。さまざまな要因のデータと、それに基づいて実際に発生した結果のデータがあって、要因から結果を分類/予測するケース。ここでは結果が教師データになる。 たとえばEメールの本文テキストがあって、それがスパムかどうか判断す …
続きを読む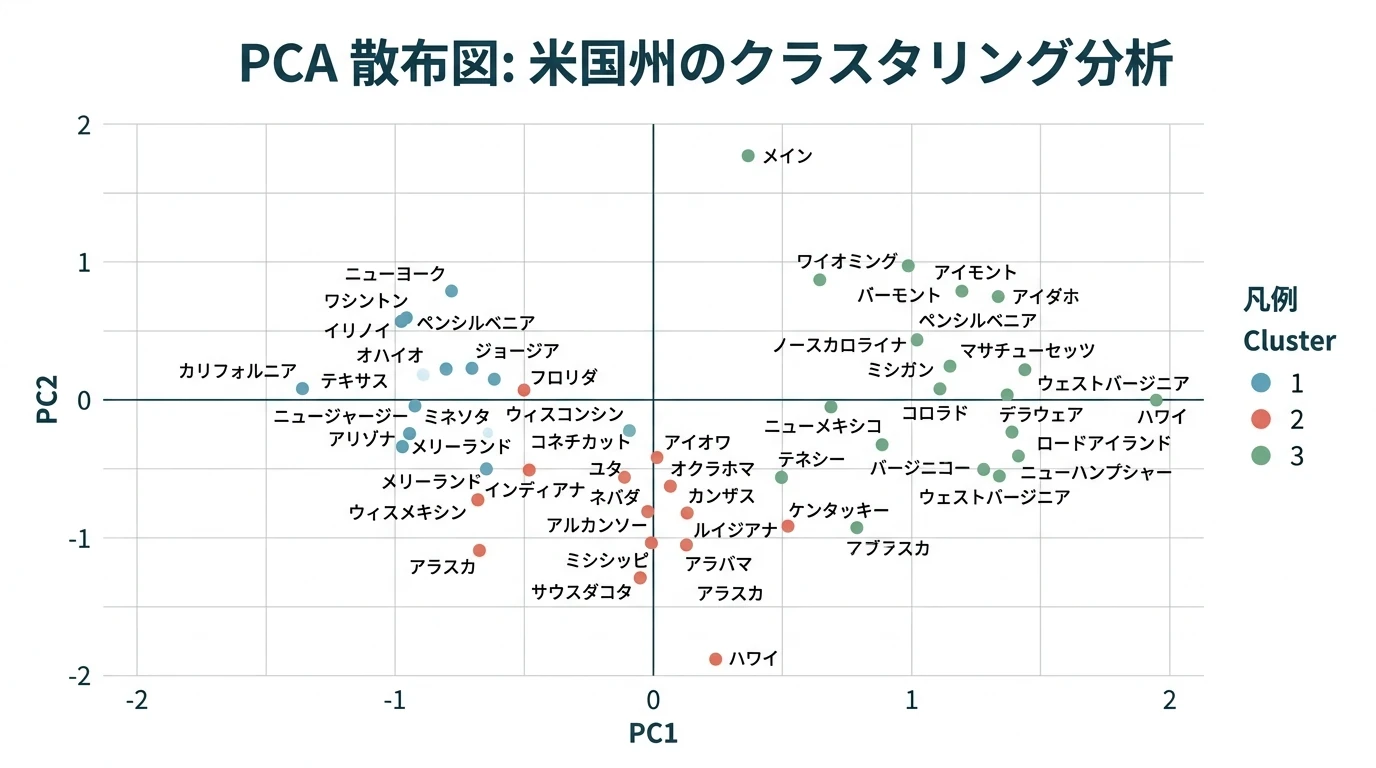
クラスター分析は 距離行列の生成(類似度行列ではない!) クラスタリングの実行 という流れになる。 それぞれのステップで、採用する 距離の種類 クラスタリングの方法 がチューニング変数となる。 この順に手順を見ていく。 行数、列数の多いビッグデータ向きのデータ形式であるMatrixパッケージに対応した距離行列についても説明する。 距離行列を生成する 類似度行列ではなく距離行列を作る。similarityではなくdistanceを作る。 直感的にはデータから距離の指標(どれだけ離れているか)ではなく類似度(どれだけ近いか)の指標を抽出し、そこからクラスタリングしたいケースが多いのだが、あくまで類似度指標に基づいた距離行列を生成するので …
続きを読む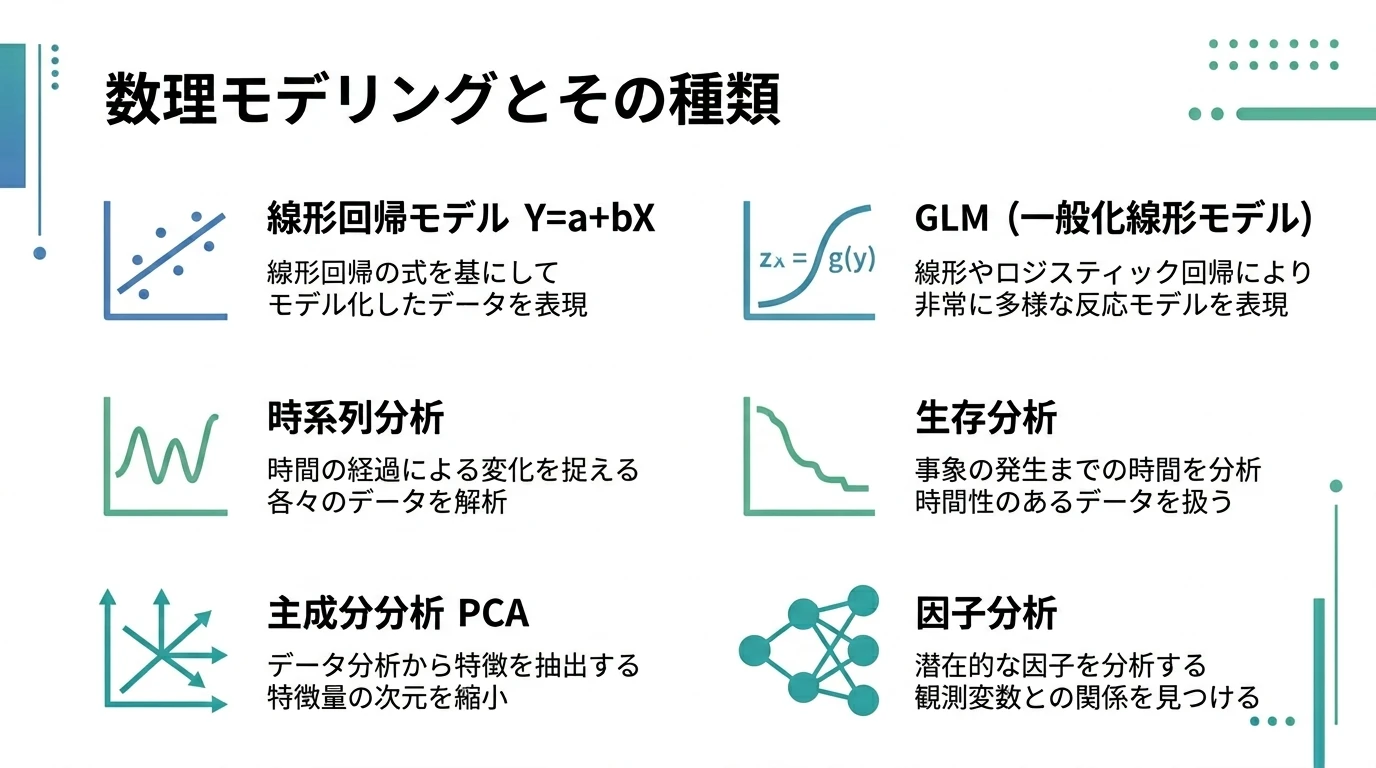
いわゆる回帰分析に代表される数理モデリングとその種類を説明していく。 数理モデリング 数理モデリングの考え方 因果関係を定量化 「Xという要因→Yという結果」という関係を $$Y=a+bX$$ で表す。 X=説明変数(独立変数) Y=被説明変数(従属変数、目的変数) いわゆる「回帰分析」である。 目的 因果関係とインパクトの大きさの特定 予測 モデリングの手続き モデル式の選択(単回帰、ロジット、…) 従属変数の特徴(分布の形状、ばらつき方)によって適切なモデルを選択する パラメータの推定 さまざまな推定法がある(最尤法、最小二乗法) そのモデルでいいか検証 あてはまりのよさ(fit) 決定係数 AIC 残差の評価(独立性、正規性、 …
続きを読む
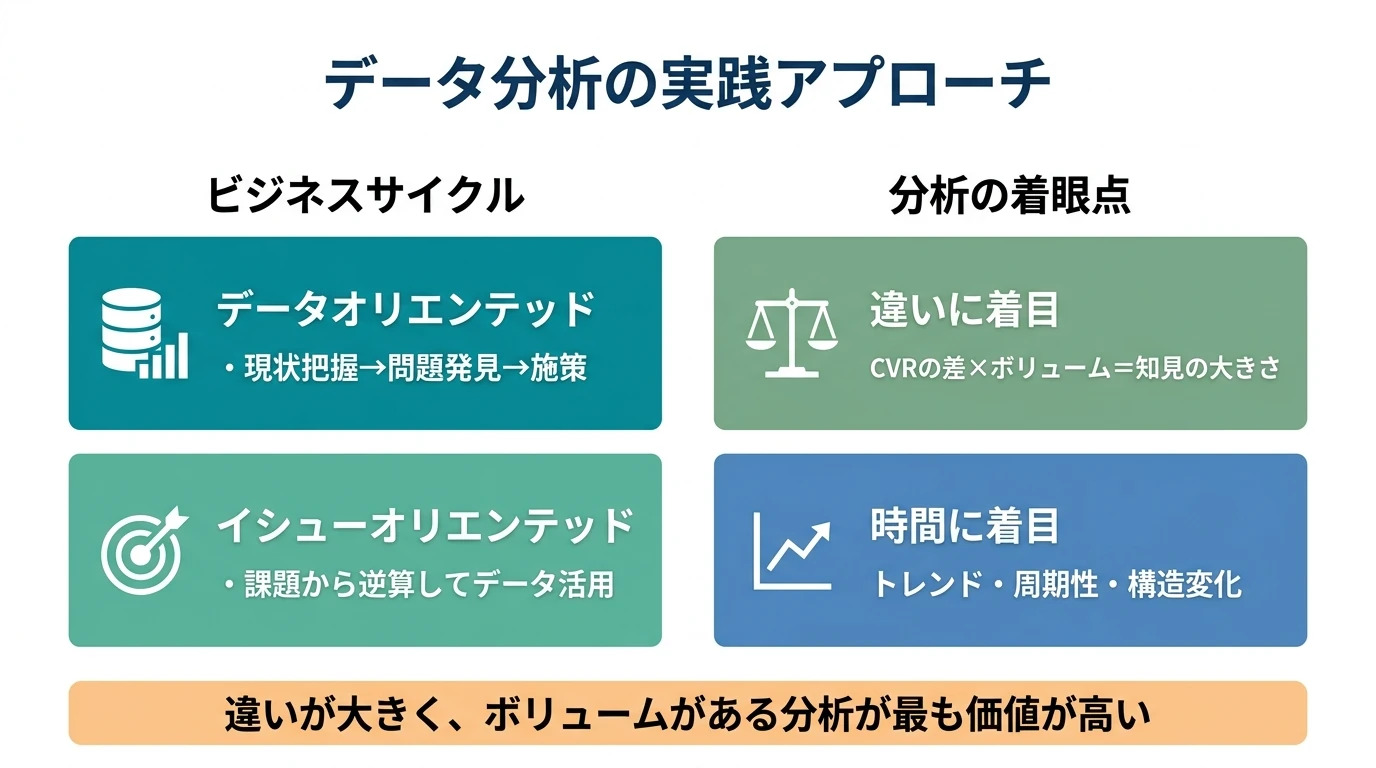
データ分析の考え方 データに基づいて意思決定をすることは、もはやビジネスの前提となった。 AIがデータ分析のワークフローを大きく変えつつある今だからこそ、その土台となる「考え方」を正しく理解しておくことが重要である。 データ分析がビジネスの課題を何でも解決してくれるのだろうか? データ分析には役割と守備範囲、正しい手法というものが決まっている。 間違った使い方をすると間違ったインサイトを導き出すことになる。 何でもデータ分析が解決してくれるわけではなく、データ分析の守備範囲とそうでない部分は峻別しなければならない。 データ分析を正しく理解して実務に役立てていくために実務上、最低限抑えておけばいいところをまとめていく。 そもそもデータ …
続きを読む