
LLMの性質を知る──初心者のための大規模言語モデル解説 生成AIの技術を実際に使いこなすには、その中核にあるLLMすなわち大規模言語モデルの性質を正しく理解することが不可欠である。本記事では、LLMとは何か、どう使えばうまくいくのか、そしてどんな落とし穴があるのかを、初心者の方にもわかりやすく解説していく。 LLMとは何か AI・生成AI・LLMの関係 まず、大きな枠組みから整理する。 AIとは、人間のように考えたり判断したりするコンピュータプログラムのことである。人間の知能を真似て、データから学習し、問題を解決する仕組み全般を指す。厳密な定義があるわけではないので、「コンピュータが賢くふるまう技術」くらいのイメージでいい。 AI …
続きを読む
DSPy オプティマイザ 統合リファレンス DSPyオプティマイザとは DSPyにおけるオプティマイザ(旧称:Teleprompter)は、DSPyプログラムのパラメータを自動的に調整し、指定したメトリクスを最大化するアルゴリズムである。従来、LLMアプリケーションの品質向上はプロンプトの手動チューニングに依存していたが、オプティマイザはこのプロセスをデータ駆動で自動化する——いわばLLMプログラムのための「コンパイラ」に相当する。 最適化対象となる3種のパラメータ DSPyプログラムが持つ最適化可能なパラメータは以下の3種類であり、それぞれを専門とするカテゴリのオプティマイザが存在する。 Few-Shotデモ(デモンストレーション …
続きを読む
生成AIの嘘を減らすプロンプト手法集 AIが事実と異なる情報を生成してしまう現象は「ハルシネーション」と呼ばれ、AIを活用するうえで常に意識すべきリスクのひとつである。本稿では、このハルシネーションのリスクを低減するための実践的なプロンプト手法を、カテゴリ別に整理して紹介する。各手法にはチャットUIですぐに使えるプロンプト例を付した。 なお、いずれの手法もリスクを「低減」するものであり、完全に防止するものではない点に留意されたい。重要な情報は必ず人間が一次ソースで確認すること。また、手法の効果はモデルや状況によって異なる。
- 情報源・根拠を求める手法 1-1. 出典・ソースの明記を要求 AIに対して、回答に含まれる情報の出典や根 …
続きを読む
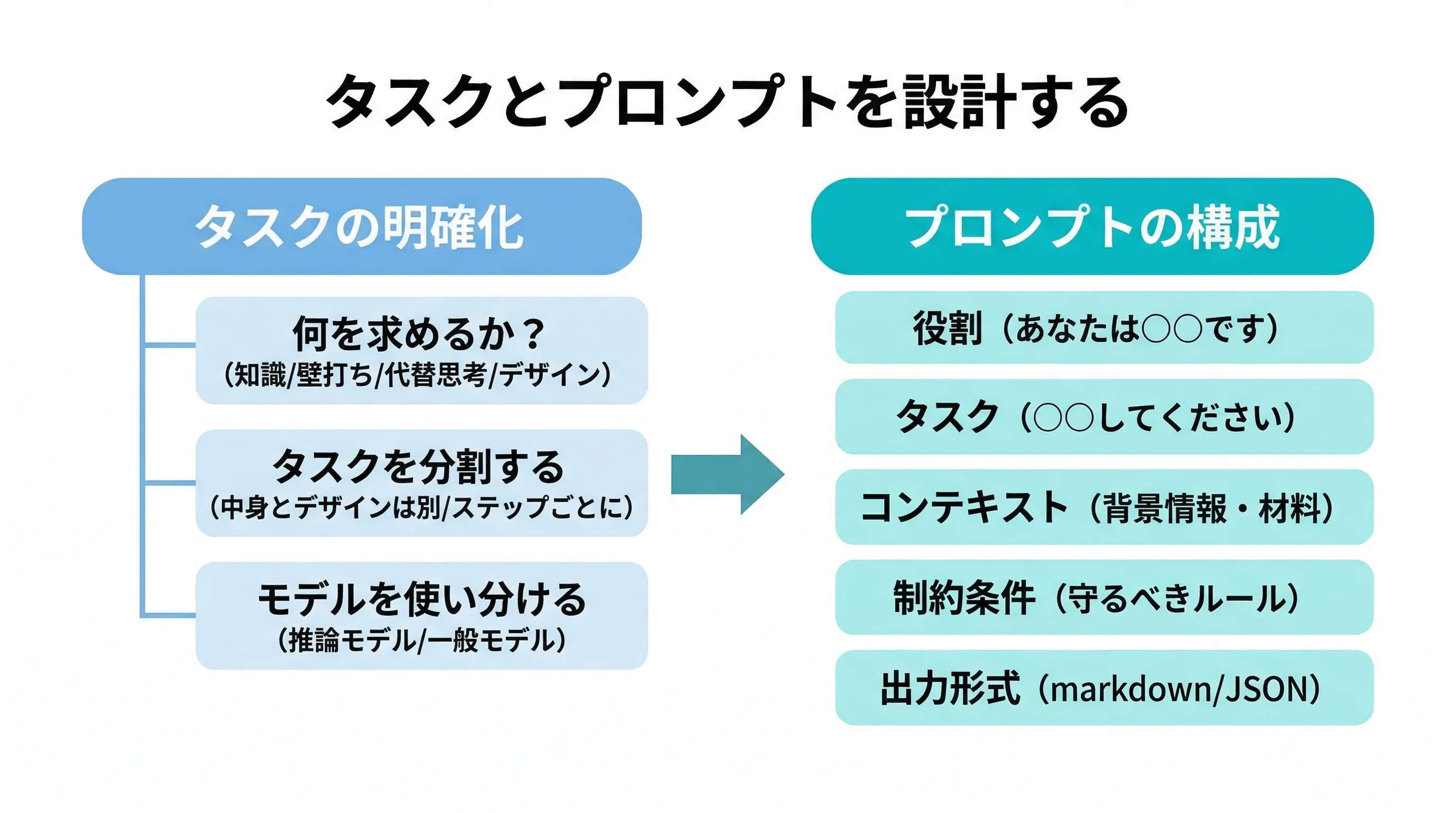
LLMタスク分類ツリー LLM(大規模言語モデル)に依頼できるタスクを体系的に分類したガイドだ。タスクの性質ごとに章を分け、それぞれの難易度・必要な推論レベル・推奨モデル・注意点・具体例を示している。自分がやりたいことがどのカテゴリに属するかを把握することで、最適なモデル選びやプロンプト設計に役立てることができる。 なぜこの分類が重要か LLMを使いこなすうえで、タスクの性質を正確に把握することはモデル選択・プロンプト設計・ツール組み合わせのすべてに影響する、基礎的な判断である。 コストと品質のトレードオフという観点では、フォーマット変換のような軽量タスクに最高性能モデルを充てるのはコストの無駄であり、逆に多段階推論が必要な論理パズ …
続きを読む