-
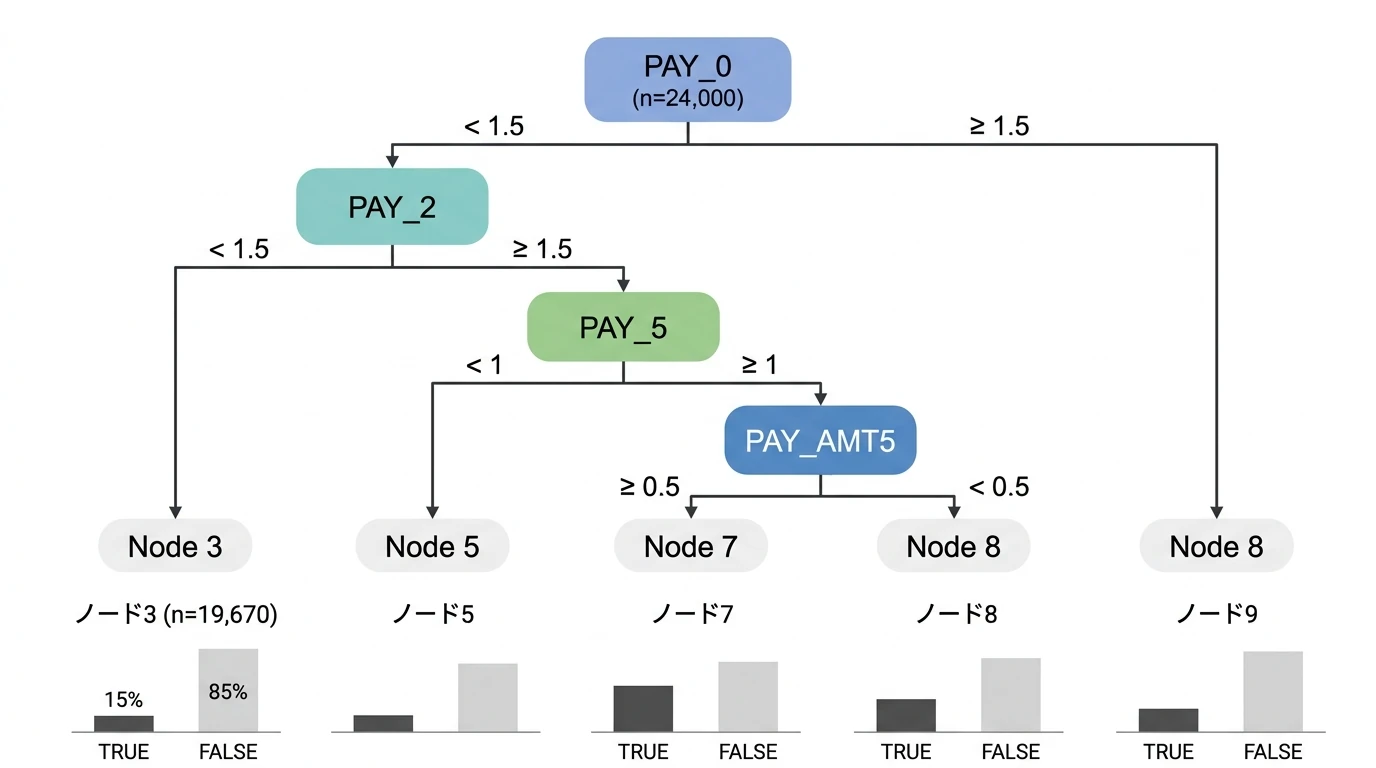
準備 決定木(decision tree)分析をする際、まず目的変数の種類とアルゴリズムを決定する。 アルゴリズム CART CHAID ID3 / C4.5 / C5.0 目的変数の型 目的変数の型によって扱いが変わる 質的変数(2値変数):分類木→目的変数が0/1, T/Fの場合はas.factor()でfactor型にデータ変換しておく 量的変数:回帰木 survivalオブジェクト (生起を表す2カラム) CARTはすべて対応、C4.5/C5.0は質的変数のみ ここではCARTアルゴリズムでツリーモデルを生成するrpartと、ランダムフォレストrangerを中心に説明する。 データセットと前処理 Default of …
続きを読む -

XGBoostは機械学習手法として 比較的簡単に扱える 目的変数や損失関数の自由度が高い(欠損値を扱える) 高精度の予測をできることが多い ドキュメントが豊富(日本語の記事も多い) ということで大変便利。 ただチューニングとアウトプットの解釈については解説が少ないので、このあたりについて説明する。 XGBoostとは? 勾配ブースティングのとある実装ライブラリ(C++で書かれた)。イメージ的にはランダムフォレストを賢くした(誤答への学習を重視する)アルゴリズム。RとPythonでライブラリがあるが、ここではRライブラリとしてのXGBoostについて説明する。 XGBoostのアルゴリズム自体の詳細な説明はこれらを参照。 …
続きを読む -
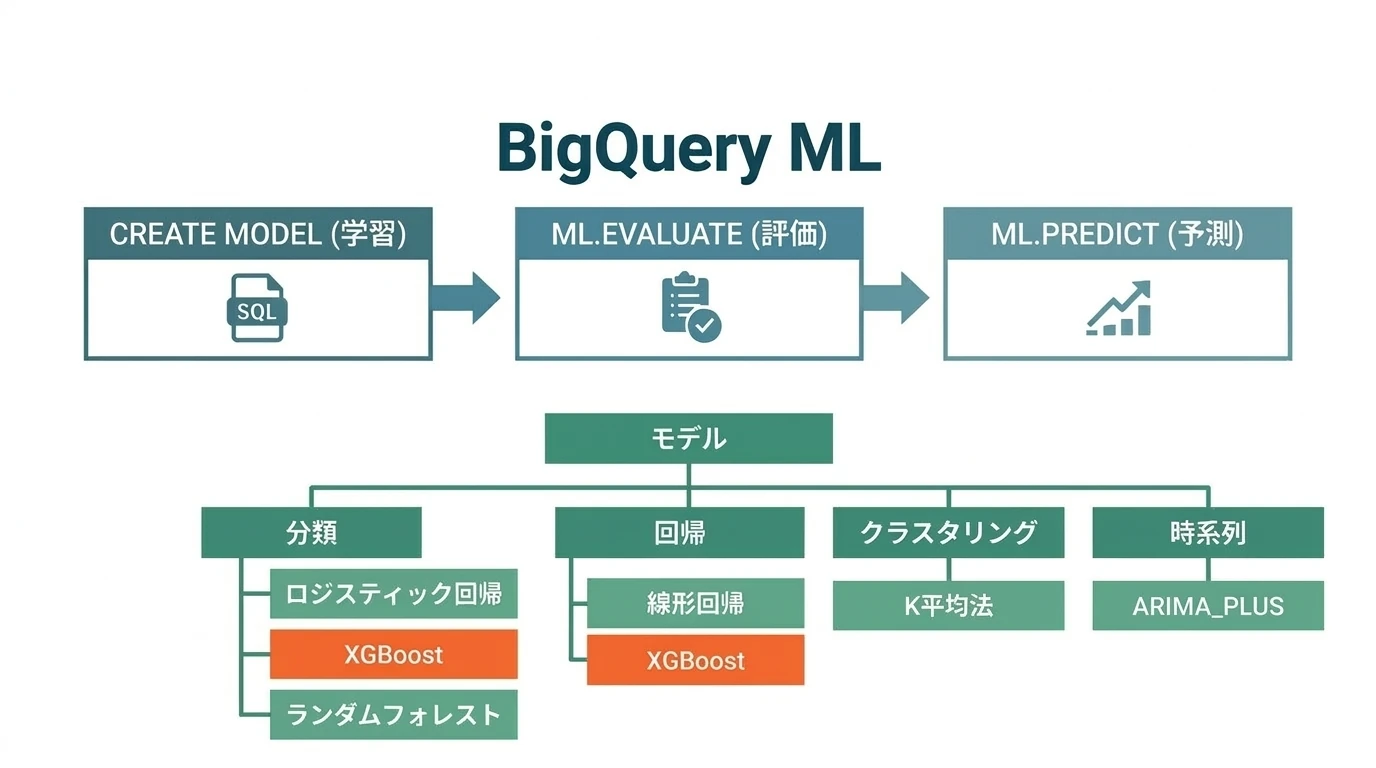
BigQuery MLは生成AI(Geminiなど)との連携やVertex AI統合など多様な機能を提供しているが、企業の日常業務で扱う構造化データ(売上、顧客、在庫など)の予測分析において、最もコストパフォーマンスが高く実用的な手法は依然として勾配ブースティング木(XGBoost系)である。この記事では、SQLだけで完結するMLパイプラインの構築方法を実例とともに解説する。 BigQuery ML(BQML)では以下のモデルが使える: 線形回帰 - 類似のリモートデータでトレーニングされたモデルを使用して、新しいデータの数値指標の値を予測する。ラベルは実数で、正の無限大、負の無限大、NaN(非数値)にはできない。 ロジスティック回 …
続きを読む -

Firebase公開データでユーザー継続予測を行う手順(BigQuery + BQML) Firebase Analyticsの公開データを使用して、ユーザーの1か月後継続を予測するための一連の分析手順である。生ログのフラット化から機械学習モデルの構築まで、BigQueryとBQMLだけで完結する手法を示す。 使うデータセット Firebaseのパブリックデータがfirebase-public-project.analytics_153293282.events_*にあるのでこれを使う。 20180612~20181003の114日分のデータ 基本集計(EDA) データの全体像を把握するため、まずイベントの発生傾向を確認する。どのよ …
続きを読む -
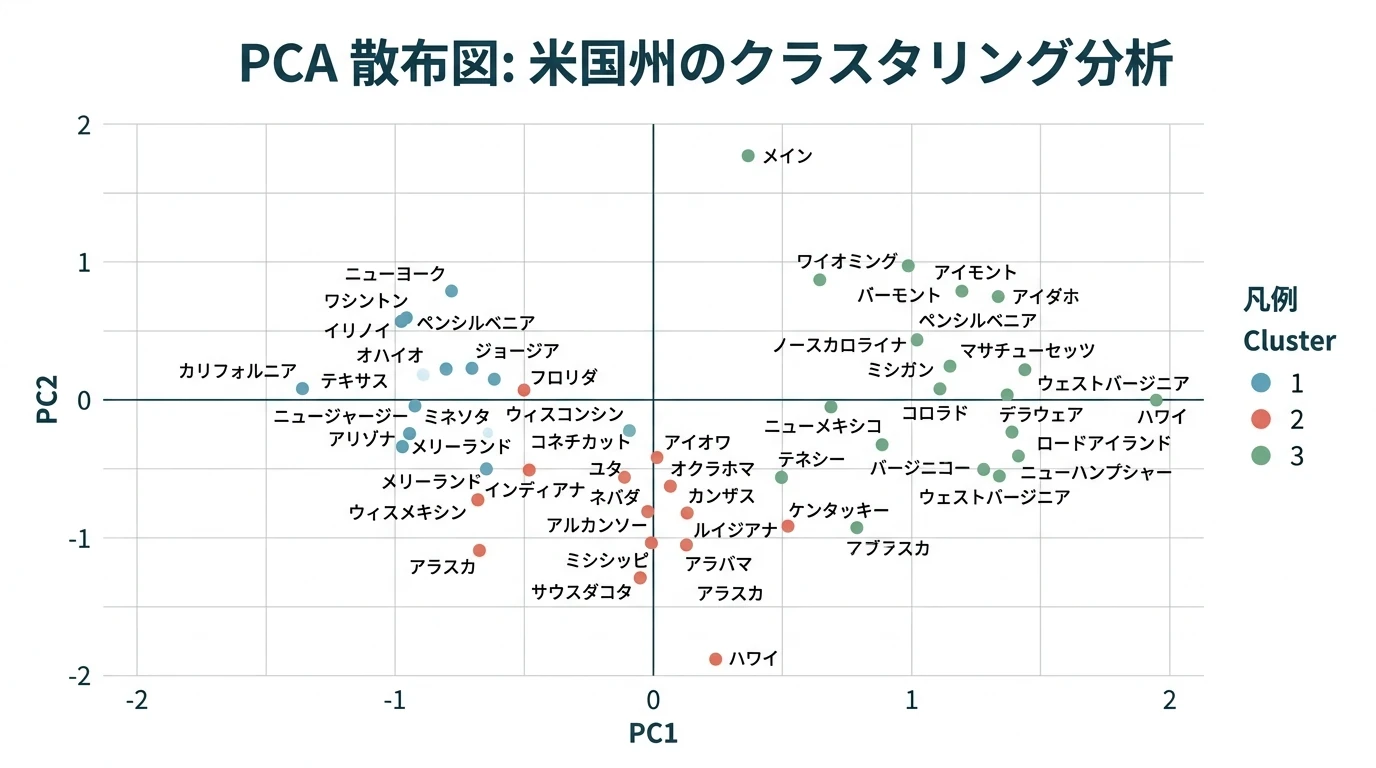
クラスター分析は 距離行列の生成(類似度行列ではない!) クラスタリングの実行 という流れになる。 それぞれのステップで、採用する 距離の種類 クラスタリングの方法 がチューニング変数となる。 この順に手順を見ていく。 行数、列数の多いビッグデータ向きのデータ形式であるMatrixパッケージに対応した距離行列についても説明する。 距離行列を生成する 類似度行列ではなく距離行列を作る。similarityではなくdistanceを作る。 直感的にはデータから距離の指標(どれだけ離れているか)ではなく類似度(どれだけ近いか)の指標を抽出し、そこからクラスタリングしたいケースが多いのだが、あくまで類似度指標に基づいた距離行列を生成するので …
続きを読む