-
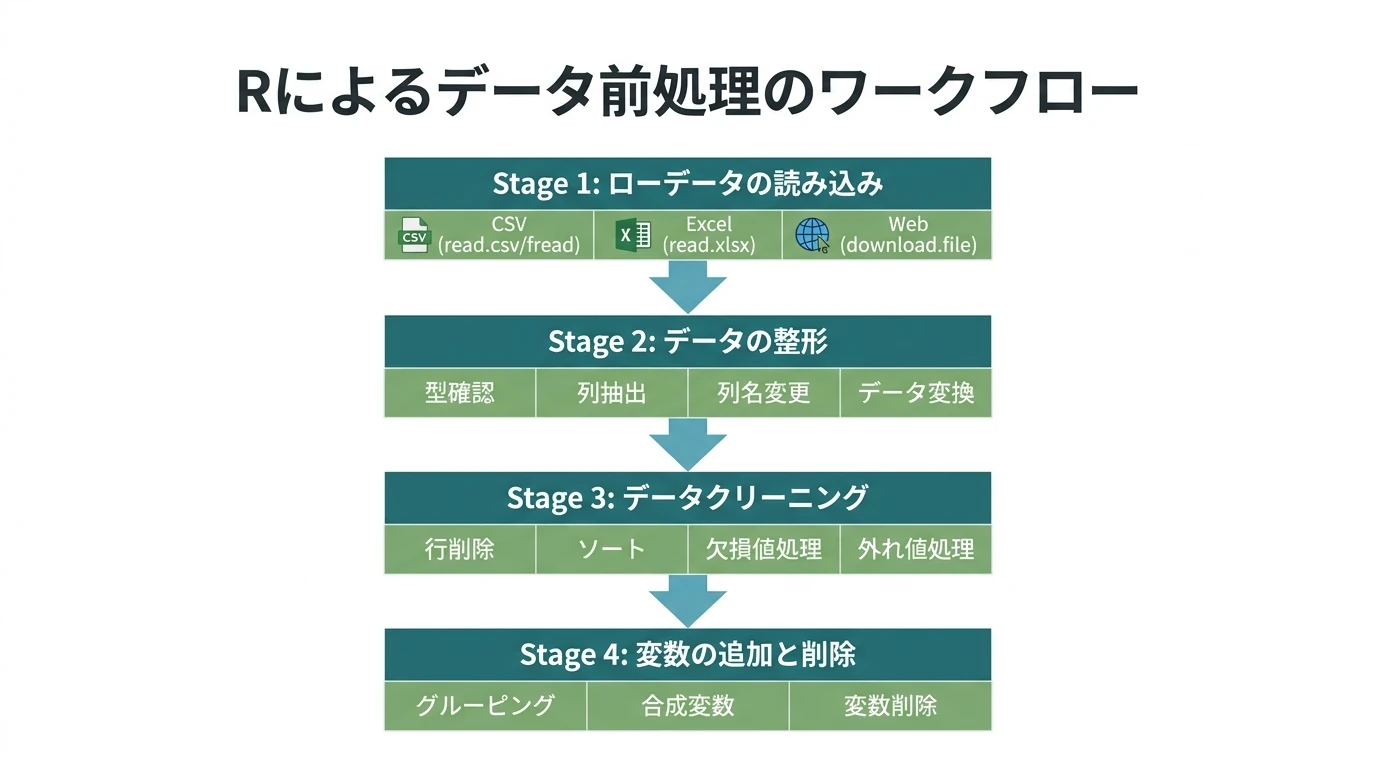
Rを使ったデータ前処理の方法を解説する。 データフレーム形式だけでなく、大きなデータを扱うのに高速なdata.tableを使ったデータの前処理の方法も解説する。 まず一般的にデータの前処理の手順は以下のようなものである。 ローデータの読み込み データの整形(分析用データセットの生成。データの持つ情報は保持) データの型確認 必要な(分析対象とする)列の抽出 列名の変更 データ変換 データの型変換 日時データの生成 因子データの生成(ordered) データクリーニング(正しく分析できるように必要に応じて情報を一部削る) 行の削除(抽出) 行の並べ替え(ソート) 標準化(scale) 欠損値処理 外れ値処理 結合 変数の追加と削除 変 …
続きを読む -
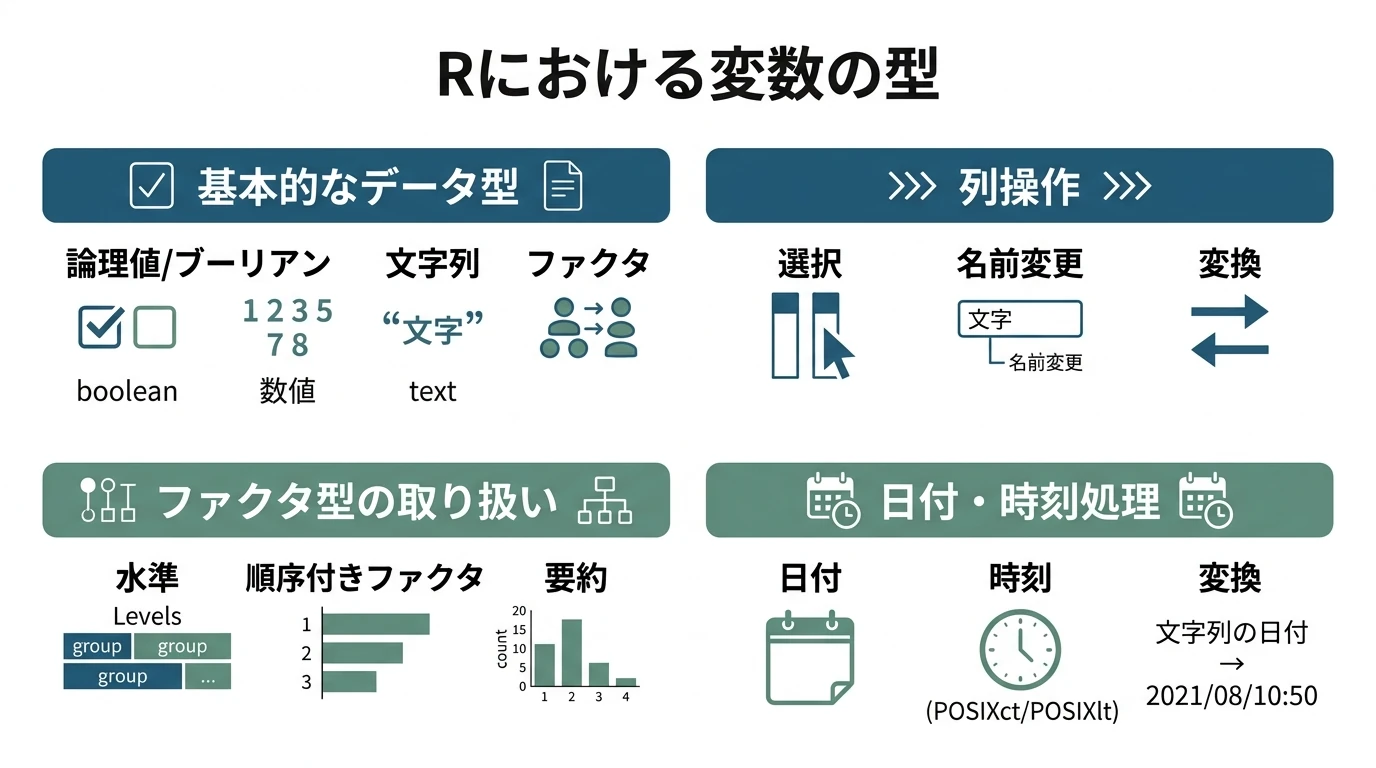
ローデータから分析対象とする変数のみ抽出し(個人情報など、保持すべきでない変数を削除するなど)、情報を失わない範囲で分析するためのデータセットを作る。分析プロジェクトにおけるローデータと同じ量の情報を持つ、整形された(扱いやすい)データセットを作るのである。 この後のデータクレンジング以降で、データの加工方法を変更するなどで手戻りが発生することもある。その際ローデータの読み込みまで戻るのは大変なので、ローデータを同じ情報を持つ、整形された状態のデータを作っておくのが重要である。データクレンジングで手戻りが発生しても、ここで整形したデータセットまで戻ればいい。 dtplyrについて 本記事ではdata.table(例:fread()で …
続きを読む -
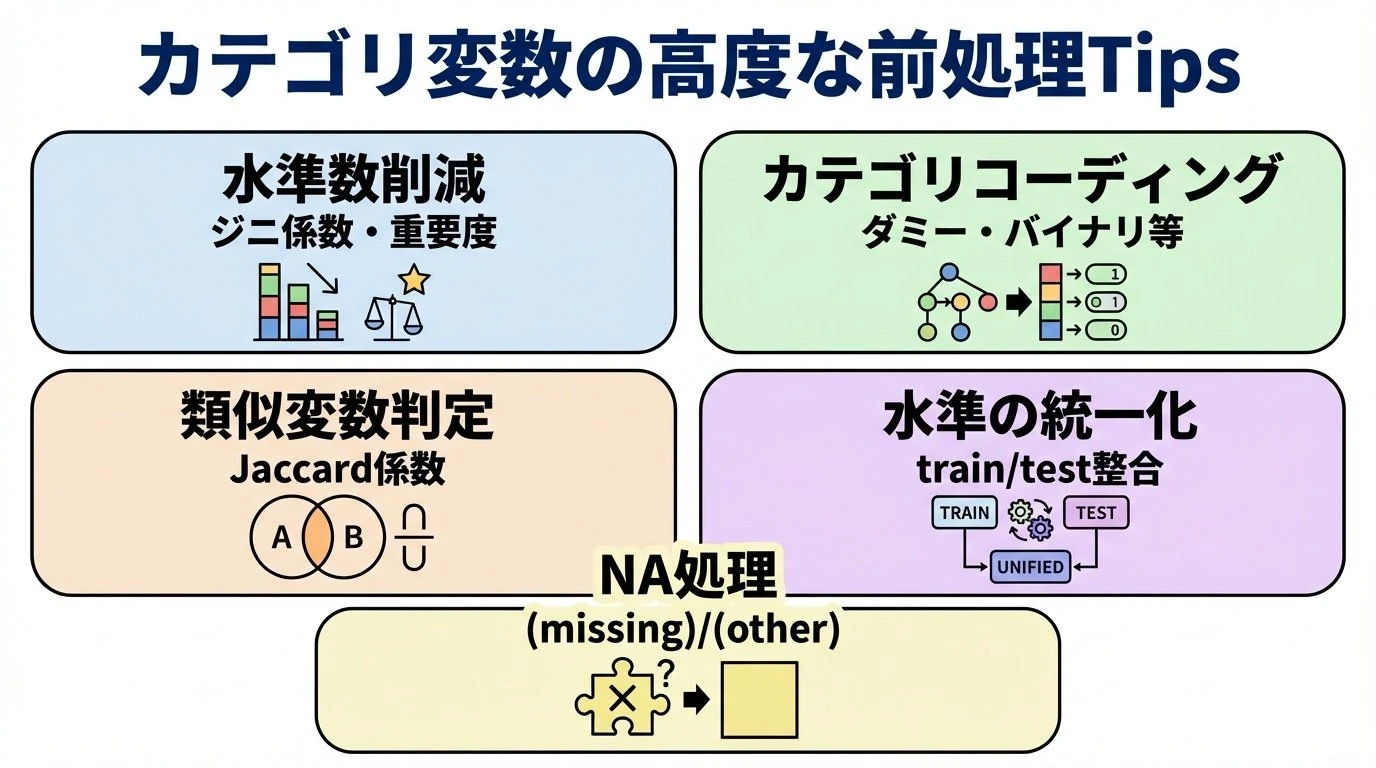
データの前処理において重要となるカテゴリ変数の扱い。高度なTipsを紹介する。 水準数を減らす 機械学習タスクの場合、水準数を削減することも重要。特にダミーコーディング(One-Hot Coding)では水準数がほぼカラム数になり、計算負荷の原因になるケースがある。 たとえば出現頻度がレアな水準はまとめて「その他」にするなどの方法があるが、目的変数に対する影響の大きい重要な水準は削除してはならない。精度を落とさぬよう、効率的に水準数を減らすことが重要になる。 水準の選び方としては、目的変数に対する情報量に着目するといい。関心対象のカテゴリ変数だけをダミーコーディングで説明変数にしたツリー系のモデルを作り、重要度上位N個の変数(水準) …
続きを読む