-
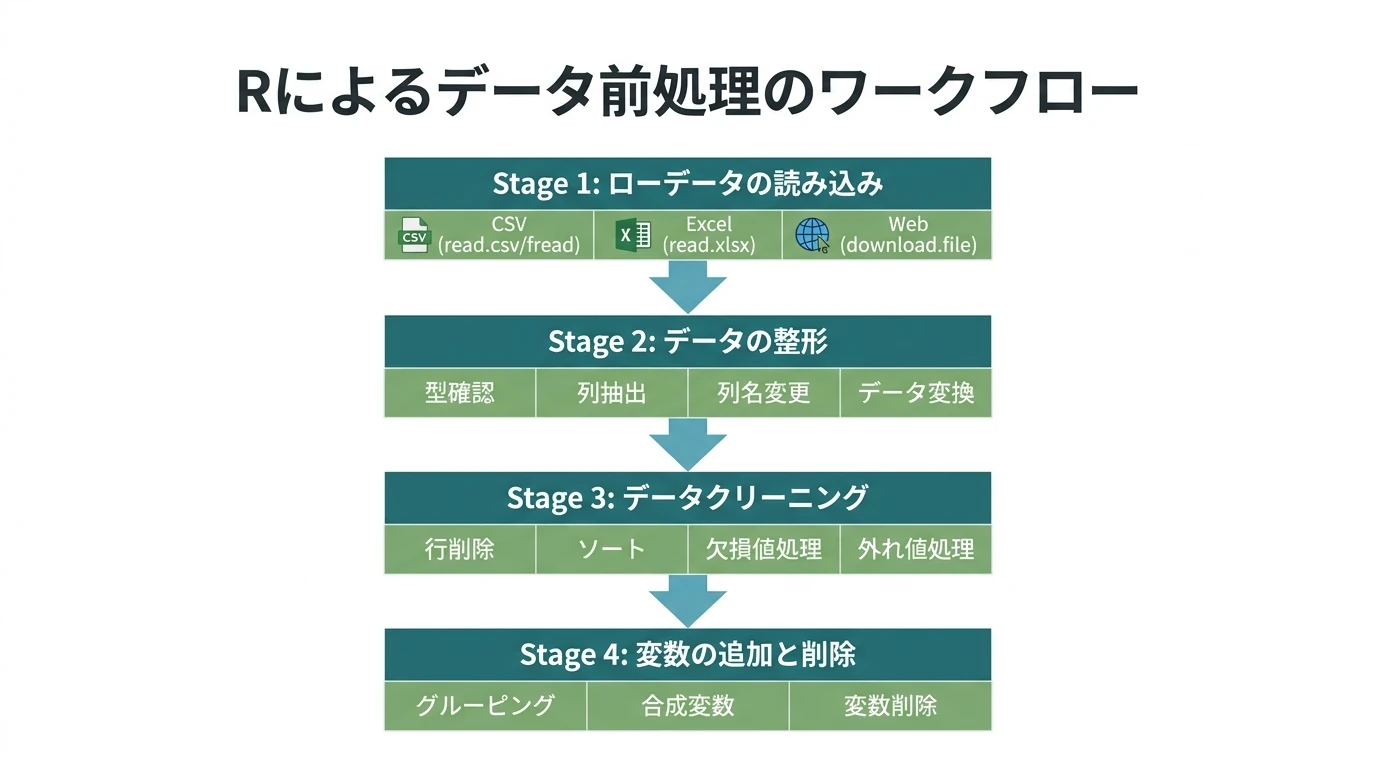
Rを使ったデータ前処理の方法を解説する。 データフレーム形式だけでなく、大きなデータを扱うのに高速なdata.tableを使ったデータの前処理の方法も解説する。 まず一般的にデータの前処理の手順は以下のようなものである。 ローデータの読み込み データの整形(分析用データセットの生成。データの持つ情報は保持) データの型確認 必要な(分析対象とする)列の抽出 列名の変更 データ変換 データの型変換 日時データの生成 因子データの生成(ordered) データクリーニング(正しく分析できるように必要に応じて情報を一部削る) 行の削除(抽出) 行の並べ替え(ソート) 標準化(scale) 欠損値処理 外れ値処理 結合 変数の追加と削除 変 …
続きを読む -
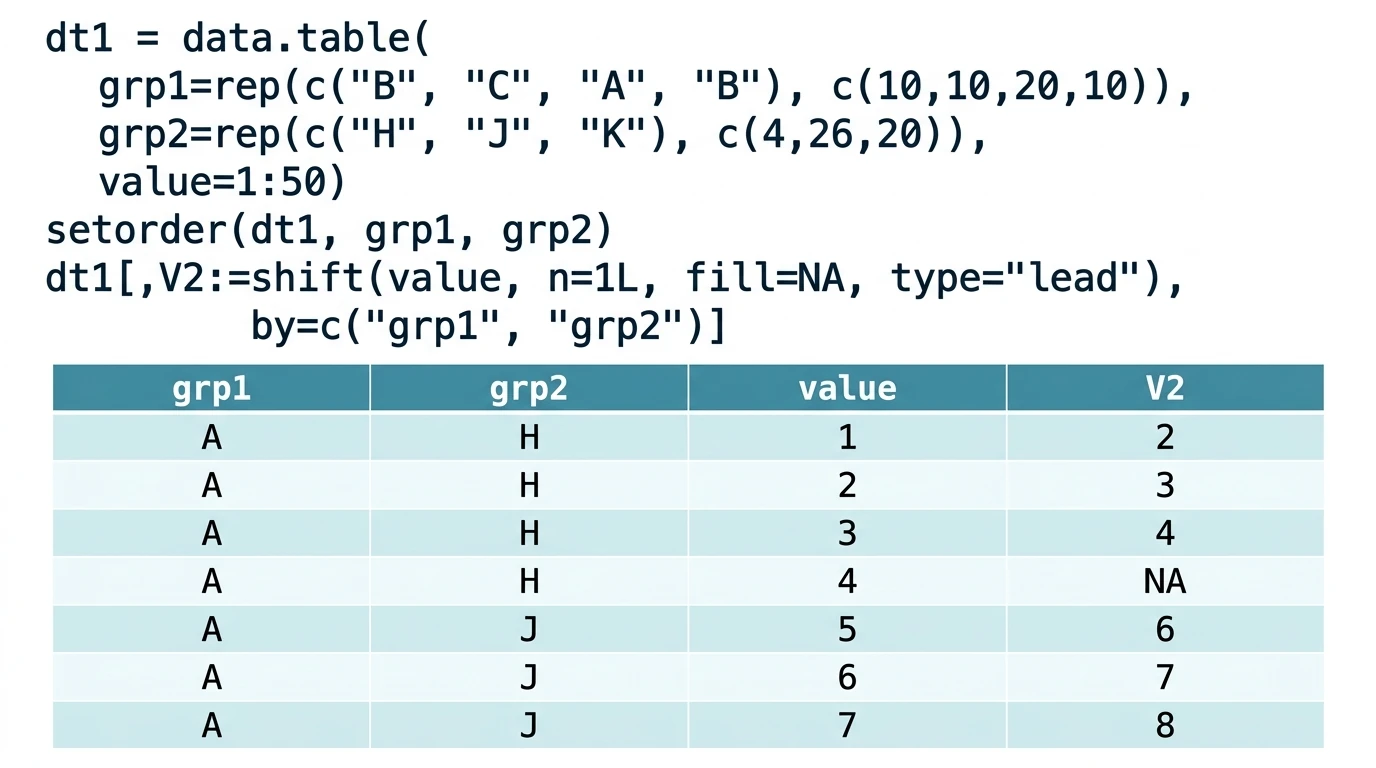
Rのdata.tableはデータフレームを高速に扱えるように改良した形式だが、この機能を提供するdata.tableパッケージには添え字を使ったdata.tableの処理機能だけでなく、さまざまな関数が実装されている。 中にはdata.table以外の形式にも使える関数もあり、 dt[,col1:=関数()] の形式で使えるdata.table用の関数にも一般的に知られていない便利なものが数多くある。 特に高速化を意識しているものが多く、知っていると処理時間を短縮できる。 data.tableはdplyrとセットで使われることも多いが、dplyr自体はdata.tableの高速仕様にのっとったものではない(tibble形式)ため、 …
続きを読む