-
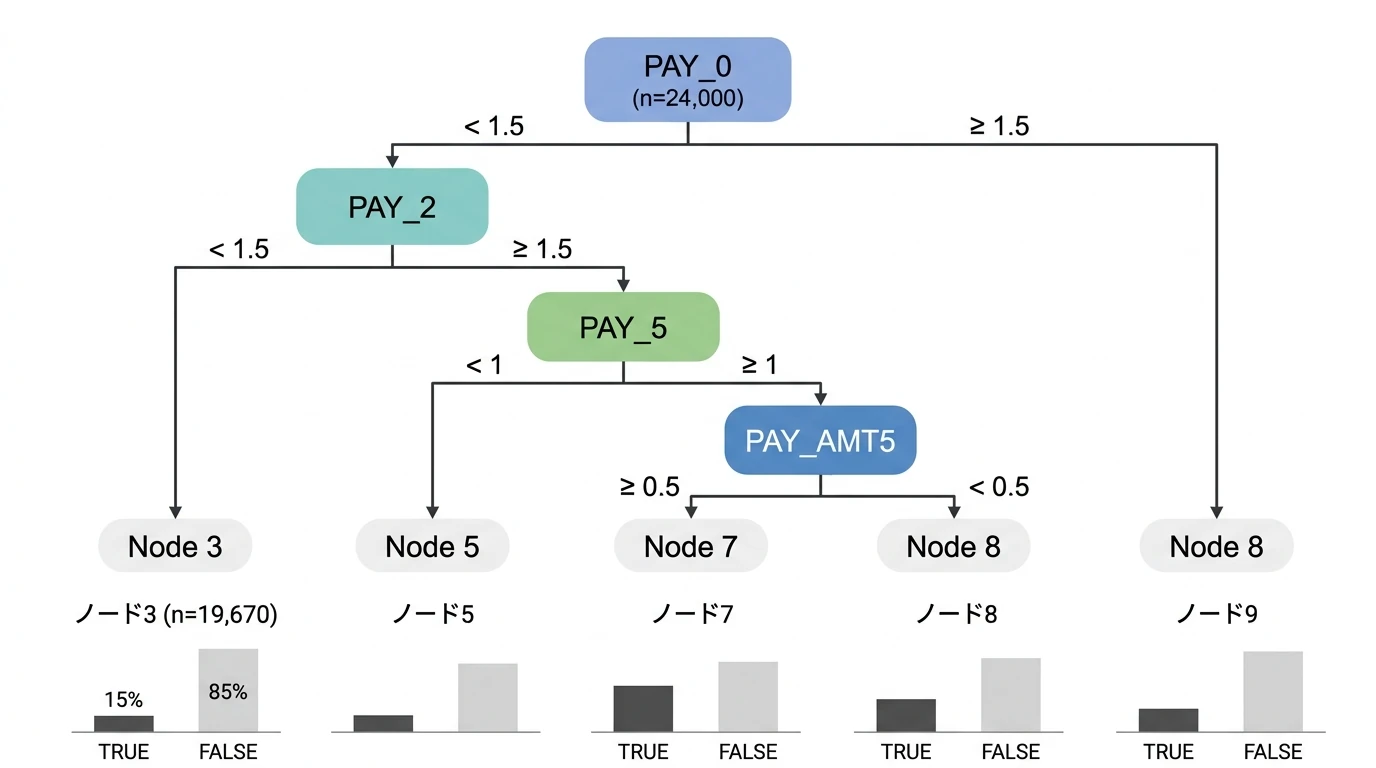
準備 決定木(decision tree)分析をする際、まず目的変数の種類とアルゴリズムを決定する。 アルゴリズム CART CHAID ID3 / C4.5 / C5.0 目的変数の型 目的変数の型によって扱いが変わる 質的変数(2値変数):分類木→目的変数が0/1, T/Fの場合はas.factor()でfactor型にデータ変換しておく 量的変数:回帰木 survivalオブジェクト (生起を表す2カラム) CARTはすべて対応、C4.5/C5.0は質的変数のみ ここではCARTアルゴリズムでツリーモデルを生成するrpartと、ランダムフォレストrangerを中心に説明する。 データセットと前処理 Default of …
続きを読む -

XGBoostは機械学習手法として 比較的簡単に扱える 目的変数や損失関数の自由度が高い(欠損値を扱える) 高精度の予測をできることが多い ドキュメントが豊富(日本語の記事も多い) ということで大変便利。 ただチューニングとアウトプットの解釈については解説が少ないので、このあたりについて説明する。 XGBoostとは? 勾配ブースティングのとある実装ライブラリ(C++で書かれた)。イメージ的にはランダムフォレストを賢くした(誤答への学習を重視する)アルゴリズム。RとPythonでライブラリがあるが、ここではRライブラリとしてのXGBoostについて説明する。 XGBoostのアルゴリズム自体の詳細な説明はこれらを参照。 …
続きを読む -

最近では機械学習の計算のためにLinuxマシンを構築しては消し、を繰り返すことが多い。サーバの構築と消去が柔軟に可能なことからもEC2やGCEなどクラウドのインスタンスをよく使うということも影響している。 この記事では一般的なサーバ構築の記事では紹介されていない、クラウドのインスタンスで意外と盲点になる点を中心に、機械学習の計算用サーバとして安定した運用をするために最低限必要な設定をまとめた。 GPUドライバ(CUDA、cuDNN)やコンテナランタイム(Docker/NVIDIA Container Toolkit)の設定は別途必要となる。 Linuxで最初にやっておくべき設定 Amazon EC2やGoogle Compute …
続きを読む -
機械学習 「明示的にプログラムしなくても学習する能力をコンピュータに与えること」 つまり1から10までをプログラムしなくても、与えられたデータに基づいてコンピュータが学習し、賢くなっていくようにすることである。具体的には適切な分類、予測、レコメンド、異常検知を行う。また複数の選択肢から適切な選択を行わせるものもある。 学習の仕方による分類 教師あり学習 材料のデータと答えのデータを与えることで、正解率を高めていくものである。さまざまな要因のデータと、それに基づいて実際に発生した結果のデータがあって、要因から結果を分類/予測するケース。ここでは結果が教師データになる。 たとえばEメールの本文テキストがあって、それがスパムかどうか判断す …
続きを読む -
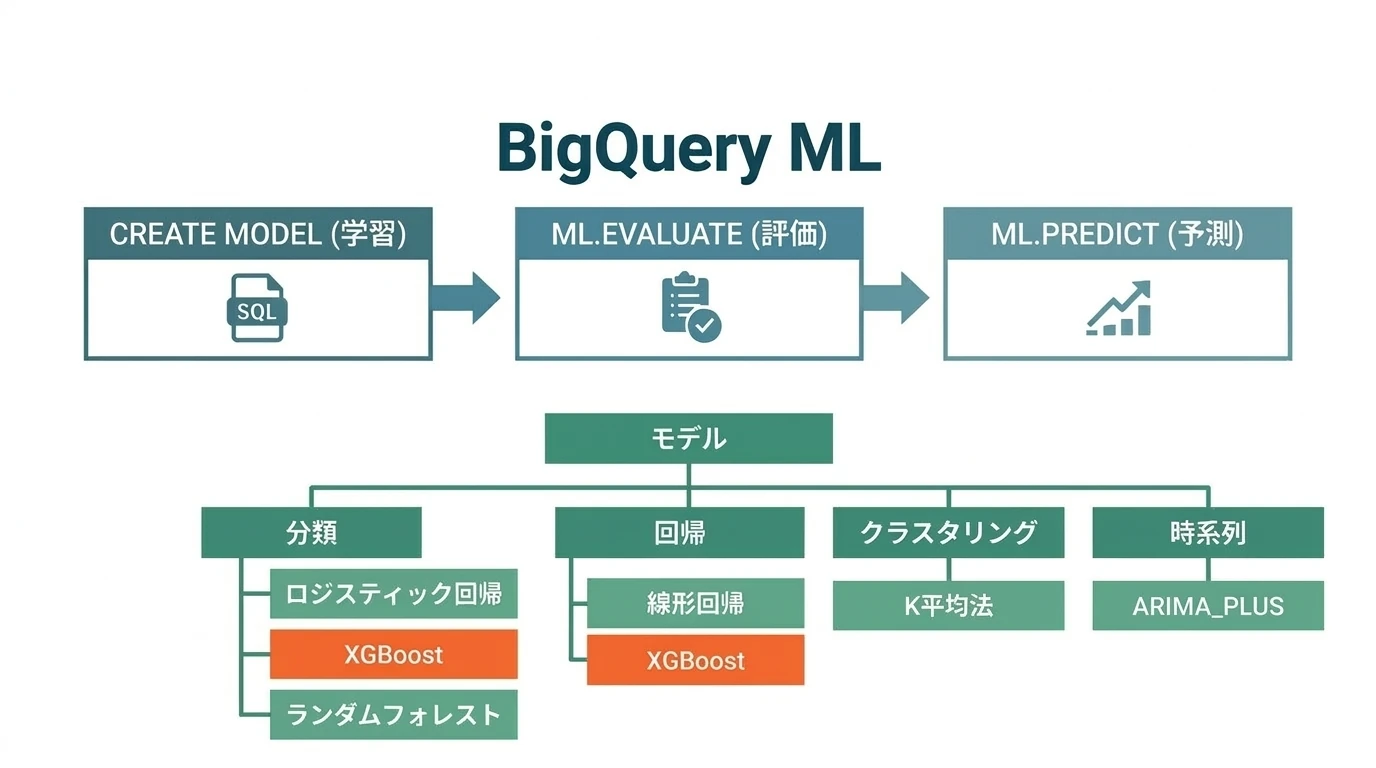
BigQuery MLは生成AI(Geminiなど)との連携やVertex AI統合など多様な機能を提供しているが、企業の日常業務で扱う構造化データ(売上、顧客、在庫など)の予測分析において、最もコストパフォーマンスが高く実用的な手法は依然として勾配ブースティング木(XGBoost系)である。この記事では、SQLだけで完結するMLパイプラインの構築方法を実例とともに解説する。 BigQuery ML(BQML)では以下のモデルが使える: 線形回帰 - 類似のリモートデータでトレーニングされたモデルを使用して、新しいデータの数値指標の値を予測する。ラベルは実数で、正の無限大、負の無限大、NaN(非数値)にはできない。 ロジスティック回 …
続きを読む -

Firebase公開データでユーザー継続予測を行う手順(BigQuery + BQML) Firebase Analyticsの公開データを使用して、ユーザーの1か月後継続を予測するための一連の分析手順である。生ログのフラット化から機械学習モデルの構築まで、BigQueryとBQMLだけで完結する手法を示す。 使うデータセット Firebaseのパブリックデータがfirebase-public-project.analytics_153293282.events_*にあるのでこれを使う。 20180612~20181003の114日分のデータ 基本集計(EDA) データの全体像を把握するため、まずイベントの発生傾向を確認する。どのよ …
続きを読む -
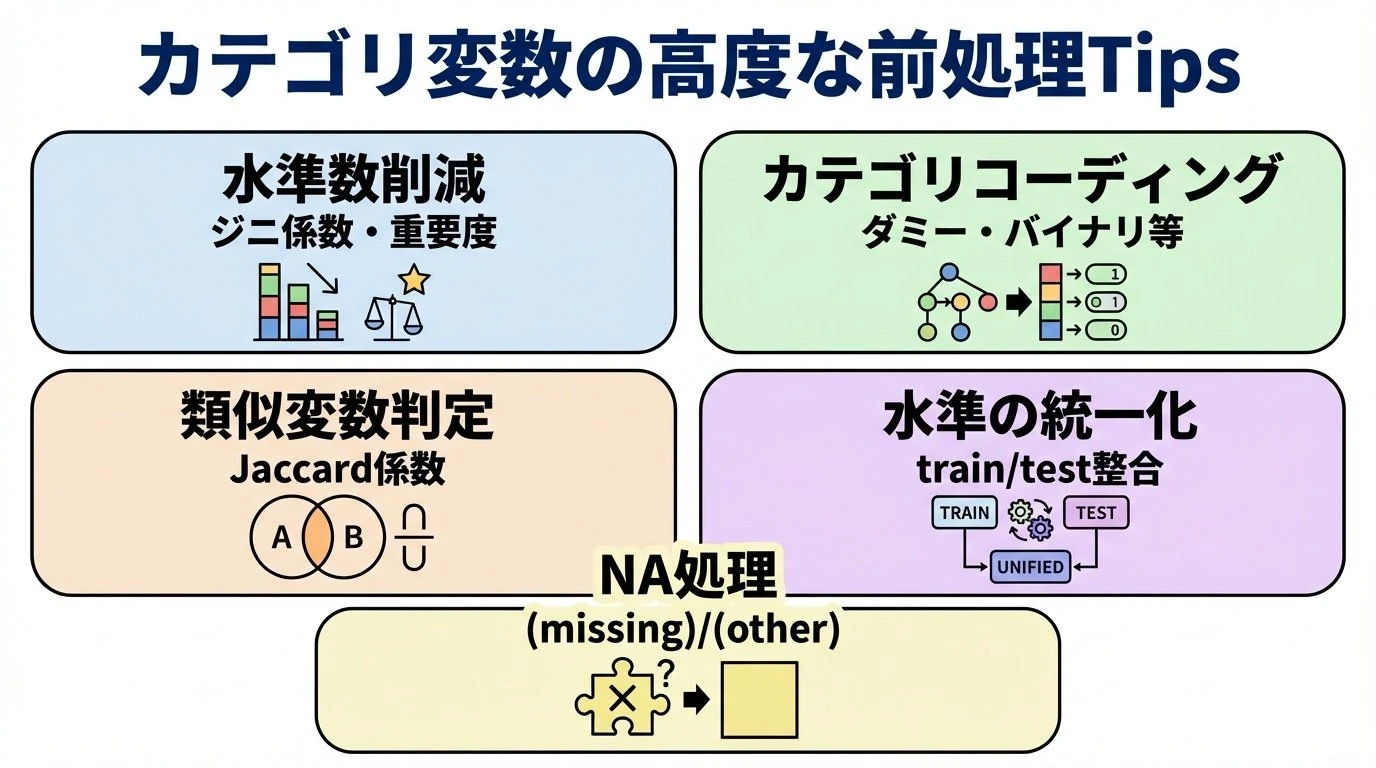
データの前処理において重要となるカテゴリ変数の扱い。高度なTipsを紹介する。 水準数を減らす 機械学習タスクの場合、水準数を削減することも重要。特にダミーコーディング(One-Hot Coding)では水準数がほぼカラム数になり、計算負荷の原因になるケースがある。 たとえば出現頻度がレアな水準はまとめて「その他」にするなどの方法があるが、目的変数に対する影響の大きい重要な水準は削除してはならない。精度を落とさぬよう、効率的に水準数を減らすことが重要になる。 水準の選び方としては、目的変数に対する情報量に着目するといい。関心対象のカテゴリ変数だけをダミーコーディングで説明変数にしたツリー系のモデルを作り、重要度上位N個の変数(水準) …
続きを読む