比較のための統計解析手法~さまざまな仮説検定から分散分析、多重比較
概要
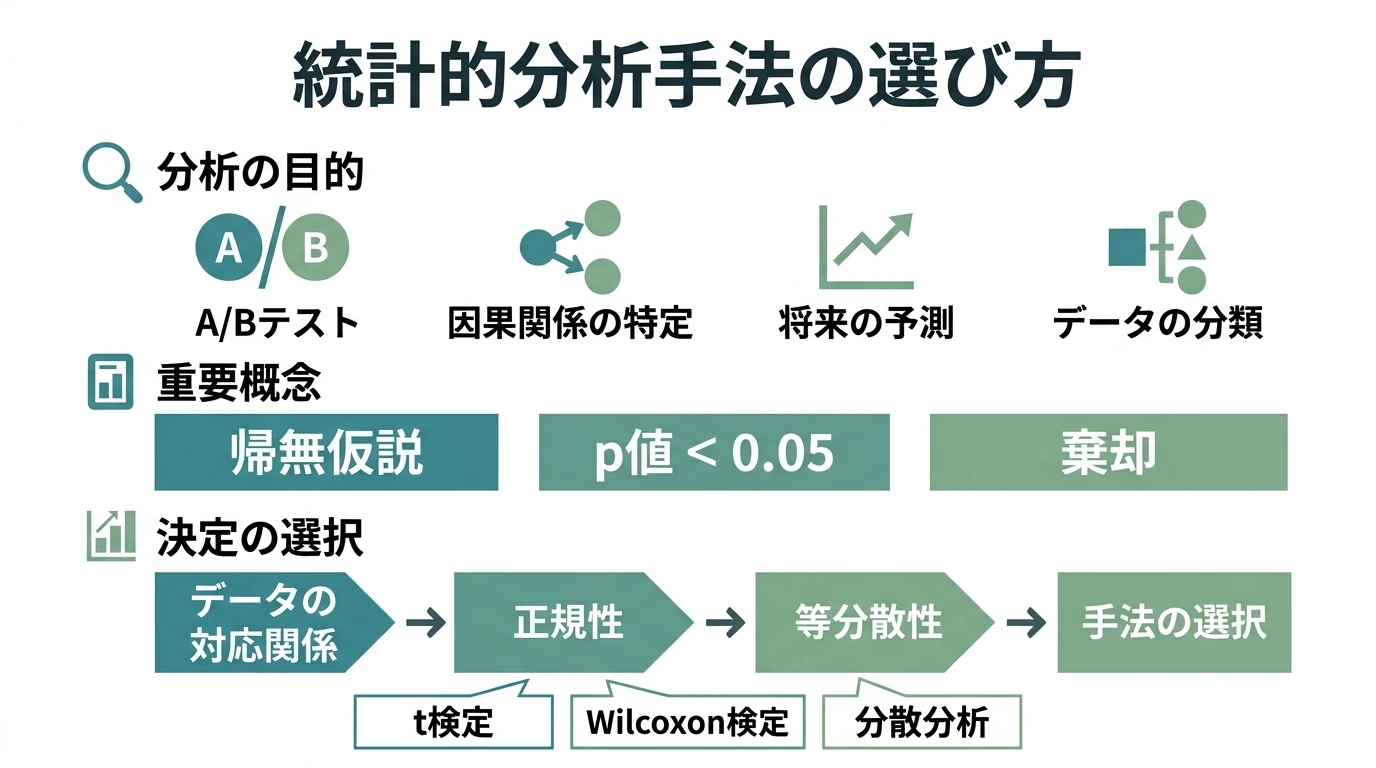
分析手法
目的とデータの性質に基づいて手法を選択
- 目的
- 違いがあるか知りたい=A/Bテスト
- (因果)関係を知りたい=何が効くかを知りたい
- 予測
- 分類
- 従属変数があって、それを分類するもの(クラス分類)
- 独立変数のみで、似ているものをまとめるもの(クラスタリング)
- レコメンド
- データの性質(手法の前提条件)
- 離散か連続か
- 正規性
- 等分散性
- 従属変数の分布の形状
http://readingmonkey.blog45.fc2.com/blog-entry-262.html
仮説検定
仮説検定とは?
基本的に比較するための方法 「A/Bテスト」→理論的に正確な手順がある。 ※比較する対象は2つ。3つ以上だと別の手法を用いることになる
仮説検定の考え方
「ある仮説が正しいと仮定したとき、この事象が発生するのは発生するのはあり得ないくらいレア。だからその仮説は間違っている」
- (例)「バナーAとバナーBのクリック率が同じと仮定したとき…」=帰無仮説
- 「あり得ない」=5%。この値をp値という
- 「間違っている」と判断すること=棄却する
帰無仮説の意味
- 仮説は間違っていることを前提に立てられる
- 「ある仮説が正しいと仮定したとき、この事象より極端な事象が発生するのは20%程度。レア度=20%ということで、そこまでレアではない」 このような場合には帰無仮説は棄却されない。だからといってその仮説は正しいのか?
- 厳密にはさまざまな帰無仮説が考えられるが、ほとんど同一性の検定。つまり「AとBが同じ」であることが帰無仮説として扱われる
対立仮説と片側検定/両側検定
帰無仮説:「バナーAとバナーBのクリック率が同じ」 では対立仮説は?
- 「バナーAのCTR>バナーBのCTR」
- 「バナーAのCTR<バナーBのCTR」
- 「バナーAのCTR≠バナーBのCTR」
実はいずれにも設定できる。それによって棄却域が変わってくる。
2種類の過誤
- 第1種の過誤=帰無仮説が実際には真であるのに棄却してしまう過誤(正常なメールをスパムと判定)
- 第2種の過誤=帰無仮説が実際には偽であるのに採用してしまう過誤(スパムメールを正常と判定)
手法あれこれ http://d.hatena.ne.jp/hoxo_m/20150217/p1 http://www.shiga-med.ac.jp/~koyama/stat/s-index.html
具体的な手法
前提条件
- 対応のある標本か、対応のない標本か(対応の有無)
- 標本の分布が正規分布に従うかどうか(正規性)
- Shapiro-Wilk test / Rでは
shapiro.test(){stats} - Anderson-Darling normality test / Rでは
ad.test(){nortest}など
- Shapiro-Wilk test / Rでは
- 各標本の分散が同一かどうか(等分散性)
- 正規分布であればF-test / Rでは
var.test(){stats}
- 正規分布であればF-test / Rでは
1標本で母集団の分布に対する検定
| 手法名 | 特徴 | Rの関数 |
|---|---|---|
| Student’s t-test for one sample | 母分散が未知の母平均に対する検定。母集団の正規性を仮定するが、サンプルサイズが十分大きい場合は中心極限定理により多少の非正規性にはロバスト。標本分散を使うのでt検定 | t.test(ベクトル, mu=母平均){stats} |
| One sample Kolmogorov-Smirnov test | ノンパラメトリック。標本が特定の分布に従うかどうかの検定。 | ks.test(ベクトル, 'p分布名', 分布のパラメータ...){stats} |
対応のある2標本の比較
| 手法名 | 正確な帰無仮説 | 前提条件 | Rの関数 |
|---|---|---|---|
| Student’s t-test for paired samples | 2群が同じ分布に従う(平均値が等しい) | 正規性:要 等分散性:要 | t.test(ベクトルA, ベクトルB, paired=T){stats} |
| Wilcoxon’s signed-rank test | 2群の代表値に差がない | 正規性:不要 等分散性:不要 | wilcox.test(ベクトルA, ベクトルB, paired=T){stats} |
対応のない2標本の比較
| 手法名 | 正確な帰無仮説 | 前提条件 | Rの関数 |
|---|---|---|---|
| Student’s t-test | 2群が同じ分布に従う(平均値が等しい) | 正規性:要 等分散性:要 | t.test(ベクトルA, ベクトルB, paired=F, var.equal = T){stats} |
| Welch’s t-test | 2群の平均値の差がない | 正規性:要 等分散性:不要 | t.test(ベクトルA, ベクトルB, paired=F, var.equal = F){stats} |
| Mann-Whitney’s U-test Wilcoxon’s rank-sum test | 2群が同じ分布に従う | 正規性:不要 分布形状がほぼ同じであることが望ましい(その場合、中央値の差の検定として解釈可能) | wilcox.test(ベクトルA, ベクトルB, paired=F){stats} |
| Brunner-Munzel test | 2群から一つずつ値を取り出したとき、どちらが大きい確率も等しい | 正規性:不要 等分散性:不要 | brunner.munzel.test(ベクトルA, ベクトルB){lawstat} |
※Brunner-Munzel testは小標本ではpermuted Brunner-Munzel testがいい
対応のない3以上の標本の比較
| 手法名 | 等分散性 | 目的 | Rの関数 |
|---|---|---|---|
| 一元配置分散分析(One-factor ANOVA) | 要 | 群自体に違いがあるか | aov(value, factor(group)){stats} |
| Kruskal-Wallis test | 不要 | 群自体に違いがあるか | kruskal.test(value, factor(group)){stats} |
| 多重比較 | その先の検定手法により異なる | 具体的にどの群とどの群に違いがあるか |
多重比較はRでは
pairwise.t.test(value, factor(group), p.adjust.method){stats}pairwise.wilcox.test(value, factor(group), p.adjust.method){stats}
p.adjust.methodは'holm', 'hochberg', 'hommel', 'bonferroni', 'BH', 'BY', 'fdr', 'none'から選ぶ
3群以上の標本の等分散性の検定
- Bartlett’s test / Rでは
bartlett.test(value ~ factor(group), data = x){stats} - Fligner-Killeen test / Rでは
fligner.test(value ~ factor(group), data = x){stats}
分割表(クロス集計表)
各群の頻度が同一の頻度分布に従うかどうかの検定
| 手法名 | サンプルサイズ | Rの関数 |
|---|---|---|
| Pearson’s Chi-squared test | 大 | chisq.test(分割表の行列){stats} |
| Fisher’s exact probability test | 小 | fisher.test(分割表の行列){stats} |