機械学習や分析時のカテゴリ変数の高度なあれこれ
概要
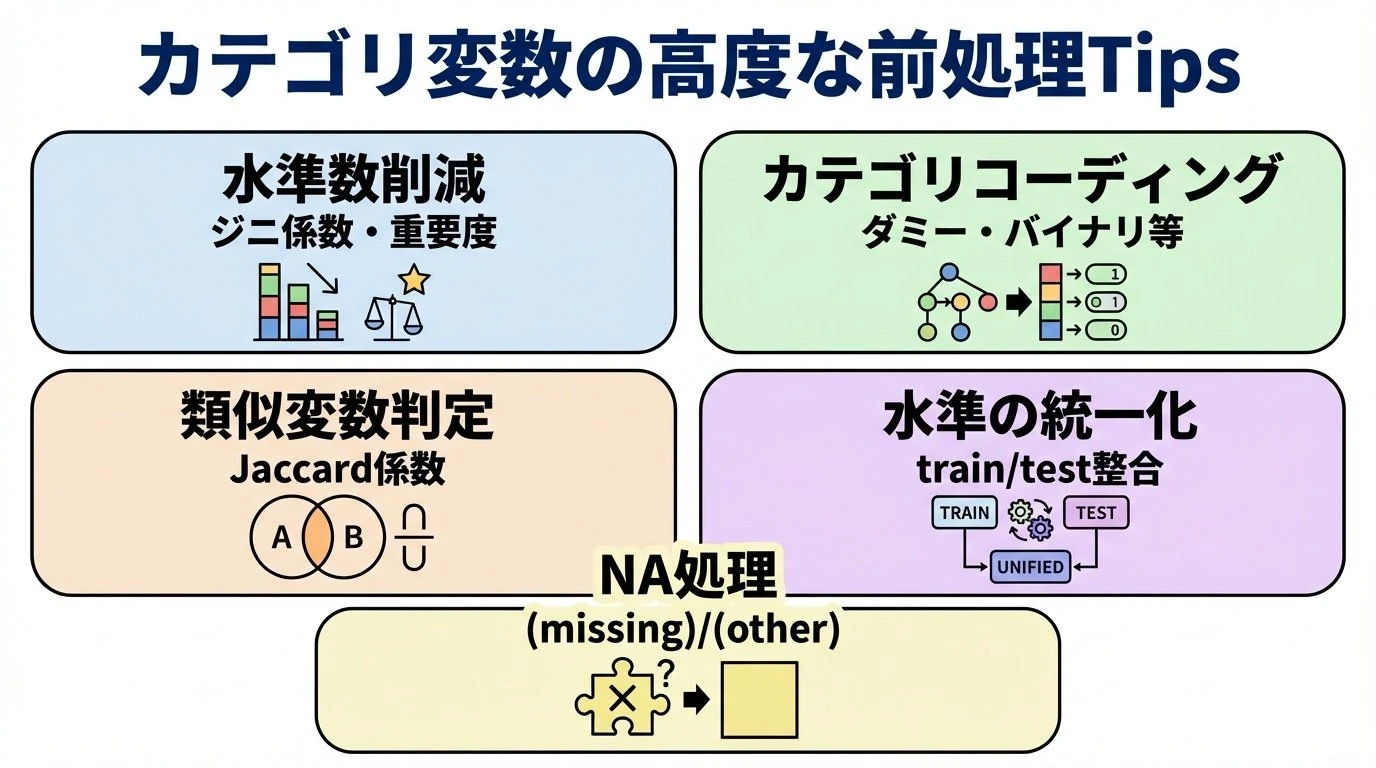
データの前処理において重要となるカテゴリ変数の扱い。高度なTipsを紹介する。
水準数を減らす
機械学習タスクの場合、水準数を削減することも重要。特にダミーコーディング(One-Hot Coding)では水準数がほぼカラム数になり、計算負荷の原因になるケースがある。
たとえば出現頻度がレアな水準はまとめて「その他」にするなどの方法があるが、目的変数に対する影響の大きい重要な水準は削除してはならない。精度を落とさぬよう、効率的に水準数を減らすことが重要になる。
水準の選び方としては、目的変数に対する情報量に着目するといい。関心対象のカテゴリ変数だけをダミーコーディングで説明変数にしたツリー系のモデルを作り、重要度上位N個の変数(水準)を採用する。下位の水準はまとめる。
同様の考え方で全水準のジニ係数を計算し、上位N個の水準を採用する方法もある。つまりCARTの考え方である。これならモデル構築が不要で計算が簡単である。
データはdata.tabletrain.dtで目的変数がy、関心対象のカテゴリ変数をx1とすると、x1の各水準のジニ係数は
2*sum(train.dt[, .(importance=abs(sum(y) - .N*train.dt[, (sum(y)/.N)])), by=x1][,importance])/train.dt[,.N]
つまり上位100水準は
remain_x1 <- train.dt[, .(importance=abs(sum(y) - .N*train.dt[, (sum(y)/.N)])), by=x1][order(-importance), as.character(x1)][1:100]
重要でない水準は(other)にまとめる。不要になった水準を削除するのを忘れずに。
train.dt[!is.na(x1) & !as.character(x1) %in% remain_x1, x1 := '(other)']
train.dt[,x1:=droplevels(x1)]
バイナリコーディングは便利
ダミーコーディング(One-Hot Coding)は前述のとおり列の数が多くなるが、情報量はそのままに列の数を減らせるのがバイナリコーディングである。バイナリコーディングでは個の水準を表現できる。機械学習、特にツリー系のアルゴリズムの場合には有効。
ただし使う場合はツリーの深さを深めに設定しておかないと一つのツリーでカテゴリ変数を説明しきれなくなる。また変数間の従属が強烈になるので、ロジスティック回帰などの説明変数間の独立を想定したモデルだと不向き。
以下の関数bin_encode()は1列のfactor型変数を複数列の0/1整数にする。
vecは対象のカテゴリ変数の列(ベクトル)- 戻り値がバイナリコーディング済み(0/1の整数)の行列。
labelはバイナリコーディングされた変数の列名のにつけるプレフィクス。
bin_encode <- function(vec, label){
mat <- matrix(
as.integer(intToBits(as.integer(vec))),
ncol = 32,
nrow = length(vec),
byrow = TRUE
)[, 1:ceiling(log(length(unique(vec)) + 1)/log(2))]
if (!is.matrix(mat)) mat <- as.matrix(mat)
colnames(mat) <- paste0(label, seq(ncol(mat)))
return(mat)
}
2列のカテゴリ変数がほぼ一致するかどうかを判定
説明変数の中でほぼ一致するカテゴリ変数が存在することがある。たとえば行動履歴データで、初回訪問地域とコンバージョン時の地域などである。このようなケースでは一方のカテゴリ変数を説明変数から除外するのが望ましい。除外するための基準として数値型変数であれば一般的な相関係数などの距離・類似度の指標を使えるが、カテゴリ変数の場合は使えない。 0/1変数の場合はJaccard係数などを使うことができるので、カテゴリ変数をダミーコーディングした変数つまりダミー変数のJaccard係数を計算し、それが1に近いもの(ほぼ位置する水準)が全水準の中でどれだけ存在するかに着目する。
- Jaccard係数を計算
- それが閾値を超える水準の数をカウント
- それが全水準に対してどの程度の比率かを見る
# Jaccard係数を計算する関数。水準数が多い場合を想定してsparse matrix(dgCMatrix)を使う。
require(Matrix)
jcdSparse <- function(X){
X <- as(X, "dgCMatrix")
X@x <- rep(1, length(X@x)) # 非ゼロ要素はすべて1に置換
vec_sum_col <- colSums(X)
AB <- crossprod(X)
sim <- AB / (vec_sum_col - t(AB - vec_sum_col)) # まとめて
sim <- as(sim, "dgCMatrix")
return(sim)
}
# Jaccard係数が閾値以上の水準数の全水準数に対する比率を計算する関数。
factors_almost_equal <- function(data, x, y, threshold=0.95) {
x <- deparse(substitute(x))
y <- deparse(substitute(y))
if (is.factor(data[[x]]) == FALSE) {
#stop(paste(x, 'is not a factor!'))
data[[x]] <- as.factor(as.character(data[[x]]))
}
if (is.factor(data[[y]]) == FALSE) {
#stop(paste(y, 'is not a factor!'))
data[[y]] <- as.factor(as.character(data[[y]]))
}
x_mat <- fac2sparse(data[[x]], drop=F)
y_mat <- fac2sparse(data[[y]], drop=F)
sim <- jcdSparse(t(rbind(x_mat, y_mat)))
sim <- tril(sim, -1) + triu(sim, 1)
ratio_gt_threshold <- sum(apply(sim, 2, max) > threshold) / nrow(sim)
#print(paste('Similarity between', x, 'and', y, ':', ratio_gt_threshold))
return(ratio_gt_threshold)
}
この戻り値が1に近いほどカテゴリ変数全体としての類似度が高いということになる。
複数のデータフレームのfactor型変数の水準を合わせる
複数のデータセット間で同じものを意味するカテゴリ変数なのに水準が異なる場合がある。たとえば自動車の車種はカテゴリ変数だが、データセットによって含まれる車種のセットは異なる場合がある。水準が一つでも異なれば、たとえば1個でも水準が追加されれば、同じラベル(車種名)であったとしても水準の番号が変わることになる。
機械学習では過去データを使ってモデルを構築し、未来のデータに当てはめて予測を行うタスクというのはよくある。そこでは未来のデータに含まれる車種は過去の車種に含まれないものが存在する。逆に過去のデータには含まれるが未来のデータに含まれない絶版車もある。つまり学習データ(過去データ)に含まれるカテゴリ変数の水準が予測データ(未来データ)の水準と合わない問題がしばしば発生する。これは予測だけでなく構築したモデルから追加学習する際に発生することもある。
つまり同じ列を持つデータフレームdf1で学習し、df2で追加学習し、df3に対して予測を行う。しかしdf1〜df3で同じカテゴリ変数なのに水準が異なるというケースである。水準の番号が変わればモデル行列の列構造が変わるため、そのままでは追加学習や予測を実行できない。
そこでこのようなケースでは**df1〜df3の間で全てのカテゴリ変数に対して水準を共通化**する必要がある。機械学習タスクでは意外と必要になる。
2つのカテゴリ変数の水準の和集合を取得する
以下の関数factor_arrange_all()は2個のデータフレームに共通した名前を持つすべてのfactor型の列に対して、水準を合わせたデータフレームを返す。df1のfactor列の水準を拡張し、df1のfactor列の水準とdf2のfactor列の水準を合わせた新しい水準にして返す関数である。
factor_arrange_all <- function(df1, df2) {
.col_factor <- intersect(
names(which(sapply(df1, is.factor))),
names(which(sapply(df2, is.factor)))
)
for (.col in .col_factor) {
new_level <- union(levels(df1[[.col]]), levels(df2[[.col]]))
new_level <- sort(new_level, na.last=F)
df1[[.col]] = factor(as.character(df1[[.col]]), levels=new_level, exclude=NULL)
}
return(df1)
}
モデル構築時点で予測データの水準を入手できない場合
上の方法では学習データの水準と予測データの水準の和集合になる。しかし実際には学習(モデル構築)時点では予測データの水準は入手できない。
- 学習時には学習データにおける水準を採用
- 予測時に、学習データに含まれない水準があった場合にはまとめて「その他」という水準に入れてしまう
- 学習データと予測データで水準数を合わせるため、学習データに「その他」の水準を追加する
水準を合わせつつ、未入手の水準の扱い問題を解消できる。 学習データにおいて上記水準数を減らすでやったような「その他」の水準を準備していない場合、以下のようにして「その他」水準を追加できる。
train.dt[,x1:=factor(x1, levels=c(levels(x1), '(other)'))]
train.df$x1 <- factor(train.df$x1, levels=c(levels(train.df$x1), '(other)'))
予測データに対して、学習データに含まれない水準を「その他」化する。
以下の関数factor_arrange_reduced()は2個のデータフレームに共通した名前を持つすべてのfactor型の列に対して、水準を合わせたデータフレームを返す。df1のfactor列の水準を削減し、df2のfactor列の水準に合わせた新しい水準にして返す関数である。
factor_arrange_reduced <- function(df1, df2) {
.col_factor <- intersect(
names(which(sapply(df1, is.factor))),
names(which(sapply(df2, is.factor)))
)
for (.col in .col_factor) {
new_level <- levels(df2[[.col]])
new_level <- sort(new_level)
df1[[.col]] = factor(as.character(df1[[.col]]), levels=new_level)
}
return(df1)
}
使い方
ただし予測時に毎回このデータが入ったtrain.dfを使うとメモリの無駄遣い(データ、つまり行は不要で水準さえ含まれればいい)なので、水準だけ抜き出した0行のテンプレートデータフレームを用意しておくといい。 モデル構築時にテンプレートを保存しておく
予測時
factor_template.df <- readRDS(file='factor_template.rds')
converted_predict.df <- factor_arrange_reduced(predict.df, factor_template.df)
カテゴリ変数とNA
NAの水準化
デフォルトではNAは水準ではない。ところがアンケート調査ではNAは「無回答」という意味のある一つの選択になる、回答者は無回答を選択したとみなすことができる。そのような場合にはNAは水準として設定すべきである。 3者択一式のアンケートの回答に無回答(NA)を加えた
{1,2,3,NA}
```r
という4水準があるとする。順序尺度として扱うのもありだが(その場合NAが厄介)、単純なfactor型(順序を持たないカテゴリ変数)として扱ってもいい。その場合は**ベース水準をNAにしておく**と便利である。
NAをベース水準にすると、水準1の回帰係数の意味は「無回答と比較した時の1の効果」ということになる。ベース水準は「○○と比較した時の」の「○○」になる。この○○が「無回答」のほうが各選択肢の意味を解釈しやすくなる(無回答の頻度にもよるが)。
以下の関数`factor_add_na()`でNAを水準として追加し、それをベース水準として設定する。`x`は水準化されていないNAを含むfactor型変数。`drop`が`TRUE`の場合、使用されていない水準が取り除かれる。
factor_add_na <- function(x, drop=T) { old_levels <- levels(x) newlevels <- c(NA, old_levels[!is.na(old_levels)]) f <- factor(x, levels = newlevels, exclude = NULL) if (drop==T) { f <- droplevels(f) } return(f) }
`factor()`関数の引数`exclude`で水準対象外にするラベルを指定できる。これがデフォルトではNAが採用されているので、NULLを指定することで水準対象外のラベルがなくなる。そして`factor()`関数の引数`levels`の先頭がベース水準になるので、そこにNAを持ってくる。
### カテゴリ変数におけるNAの意味
上記のようにNAを水準として設定することができるが、そもそもfactor型におけるNAは複数の意味を持つことがある。
既存のfactor型変数に対して、水準に含まれない値を追加代入するとNAに変換される。つまりfactor型におけるNAは欠測の場合もあれば**未知の値**を意味することがある。これらは全く意味が異なるわけで、カテゴリ変数におけるNAは欠損(missing)とその他(other)に分けて扱うべきである。
(other)が発生する前のデータを取り込んだ直後の段階で以下の処理を実行し、NAを消しておく。欠損値をすべて(missing)にする。
#.col_convert <- c(‘x1’, ‘x2’) # 適用する列を個別に指定 .col_convert <- which(sapply(train.dt, is.factor)) # すべてのfactor型の列に適用する train.dt[, (.col_convert):=lapply(.SD, function(x) ifelse(is.na(x),’(missing)’,x)), .SDcols=.col_convert]
.col_convert <- which(sapply(train.dt, is.factor)) # すべてのfactor型の列に適用する train.dt[, (.col_convert):=lapply(.SD, function(x) ifelse(is.na(x),’(other)’,x)), .SDcols=.col_convert]
とすればいい。
### まとめて実装した
学習時 `train.dt`が対象のdata.table
- `x1`はあらかじめGini係数に基づいて水準数を絞り込んでおく
- `x1`を含むすべてのfactor列のNAを(missing)と(other)に分け、水準化する
```r
# Gini係数上位100水準を抜き出しておく
remain_x1 <- train.dt[, .(importance=abs(sum(y) - .N*train.dt[, (sum(y)/.N)])), by=x1][order(-importance), as.character(x1)][1:100]
# 上位100水準に含まれればその値を採用し、含まれなければ(other)にする
train.dt[!is.na(x1) & !as.character(x1) %in% remain_x1, x1 := '(other)']
# 上の処理で不要になった水準を削除
train.dt[,x1:=droplevels(x1)]
# すべてのfactor型の列名を抽出
.col_convert <- which(sapply(train.dt, is.factor))
# factor列におけるNAを(missing)という値に変換
train.dt[, (.col_convert):=lapply(.SD, function(x) as.factor(ifelse(is.na(x), '(missing)', as.character(x)))), .SDcols=.col_convert]
# factor型の水準に(other)と(missing)を入れておく(上で追加されている場合は特になし)。ベース水準に(missing)を設定
train.dt[, (.col_convert):=lapply(.SD, function(x) factor(as.character(x), levels=sort(unique(c('(missing)', '(other)', levels(x)))))), .SDcols=.col_convert]
# テンプレートdata.tableとして保存
saveRDS(train.dt[0], file='factor_template.rds')
予測時 predict.dtが対象のdata.table
# 学習時に抽出した上位100水準に含まれればその値を採用し、含まれなければ(other)にする
predict.dt[!is.na(x1) & !x1 %in% remain_x1, x1 := '(other)']
# 上の処理で不要になった水準を削除
predict.dt[,x1:=droplevels(x1)]
# すべてのfactor型の列名を抽出
.col_convert <- which(sapply(predict.dt, is.factor))
# factor列におけるNAを(missing)という値に変換
predict.dt[, (.col_convert):=lapply(.SD, function(x) as.factor(ifelse(is.na(x), '(missing)', as.character(x)))), .SDcols=.col_convert]
# 学習データと列や水準を合わせるためにテンプレートを読み込む
factor_template.dt <- readRDS(file='factor_template.rds')
# 学習データにない列は削除
predict.dt <- predict.dt[,.SD, .SDcols=colnames(factor_template.dt)]
# factor型の水準を学習データに合わせる(ない場合はNA->(other)と変換する)
converted_predict.dt <- factor_arrange_reduced(predict.dt, factor_template.dt)
# factor型の水準に(other)と(missing)を入れておく(上で追加されている場合は特になし)。ベース水準に(missing)を設定
converted_predict.dt[, (.col_convert):=lapply(.SD, function(x) factor(ifelse(is.na(x),'(other)',as.character(x)), levels=sort(unique(c('(missing)', '(other)', levels(x)))))), .SDcols=.col_convert] # as.factor()だと値のない水準が値のない水準がdropされてしまうので、factor()でlevelsを指定する
Pythonでの実装例
import pandas as pd
# 水準数が膨大なカテゴリ変数から重要でない水準を削除
def preprop_reduce_levels(df, key, remain):
remain = list(map(str, remain))
categories = sorted(['(missing)', '(other)'] + remain)
dtype = pd.CategoricalDtype(categories=categories)
df[key] = (
df[key].astype('string')
.fillna('(missing)')
.apply(lambda x: x if x in remain else '(other)')
.astype(dtype)
)
return df
# 後で予測データと合わせることができるようにするための処理
def format_levels(df):
_cols = df.select_dtypes(include='category').columns
for _col in _cols:
existing_cats = list(df[_col].cat.categories)
new_cats = sorted(set(existing_cats + ['(missing)', '(other)']))
dtype = pd.CategoricalDtype(categories=new_cats)
df[_col] = (
df[_col].astype('string')
.fillna('(missing)')
.str.strip('][>')
.astype(dtype)
)
return df
# 学習データに合わせるための処理
def modify_levels_to_train_data(df_data, df_template):
# 学習データにない列は削除
df_data = df_data[df_template.columns]
# カテゴリの水準を学習データに合わせる
_cols = df_data.select_dtypes(include='category').columns
for _col in _cols:
dtype = pd.CategoricalDtype(
categories=list(df_template[_col].cat.categories)
)
try:
df_data[_col] = df_data[_col].astype(dtype)
except Exception as e:
logger.warn((_col, e))
df_data[_cols] = df_data[_cols].fillna('(other)')
return df_data
学習時
# remain_x1で指定した上位の水準に含まれればその値を採用し、含まれなければ(other)にする
train_df = preprop_reduce_levels(train_df, 'x1', remain_x1)
# NAを削除して(missing)と(other)を水準に追加
train_df = format_levels(train_df)
# カテゴリ水準テンプレートの保存
train_df.iloc[0:0].to_pickle('category_template.pkl', compression='zip')
予測時
# remain_x1で指定した上位の水準に含まれればその値を採用し、含まれなければ(other)にする
predict_df = preprop_reduce_levels(predict_df, 'x1', remain_x1)
# 学習データと列や水準を合わせるためにテンプレートを読み込む
category_template_df = pd.read_pickle('category_template.pkl', compression='zip')
# 列とカテゴリ変数の水準を学習データに合わせる
predict_df = modify_levels_to_train_data(predict_df, category_template_df)