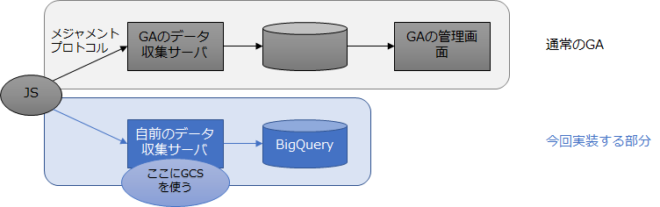
サーバログ型アクセス解析の特徴、ログの構造と取得方法、ユーザID
今では誰もが簡単にアクセス解析をできるようになった。 Googleアナリティクスという無料のツールがあり、そのタグをHTMLファイルに記入することできれいな分析結果の画面が手に入る。有料だがAdobe Analyticsを導入しているサイトも多い。 最近は分析というと、こういったツールの画面を見ることが中心になってしまっている。 ところがそこに出てくるのはGoogleやAdobeによって加工・集計された数字だ。Googlebotなどの検索ロボットのアクセスも除外されてしまう。実は裏側にはログがあって、それを加工・集計して見たいアウトプット(媒体ごと流入数一覧、コンバージョンを生んだランディング…