目次
アクセスログデータの前処理
これまでの手順で取り込んだログデータはそのままでは分析に使いにくい。
今後の分析がやりやすいように、ある程度の前処理が必要になる。
ここでは前処理のポイントになるものを列挙する。
- 分析対象とするリクエスト行の抽出/削除
取り込んだままのログデータに不要な情報が含まれることがある場合、必要に応じてそれらを削除する。アクセスログファイルからのデータ抽出時にフィルタリングしていない場合、ここで削除する。- ボットの抽出/削除
- 画像の削除
- ユニークユーザとセッションの作成
- 疑似ユニークユーザ
- セッション
- 集計単位URLの指定
- URLの分割
- ダミーパラメータの除外
- URLごとのPV数を集計する際、同じページとして扱うURLを集約
- 分析に必要な変数を追加
- デバイス
スマートフォン、PC、タブレット - 流入元識別
広告、自然検索、直接流入、…- リファラを使う
- 流入元識別用のダミーパラメータを使う(広告のキャンペーンコードなど)
- その他分類(ページのトピックなど)
- コンバージョン
コンバージョンページへのアクセスをCV完了に - ランディングページ
セッションの開始ページがランディングページ - ページ閲覧時間
- デバイス
このように変数(特徴量)を追加することで、実用的な分析ができるようになる。
ユーザIDが会員情報などと紐付けられていれば、属性ごとの行動も把握できる。
疑似ユニークユーザとセッションの作成
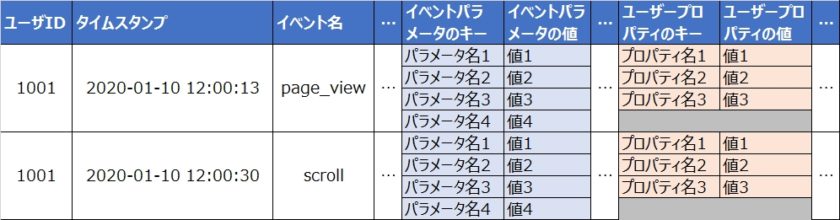
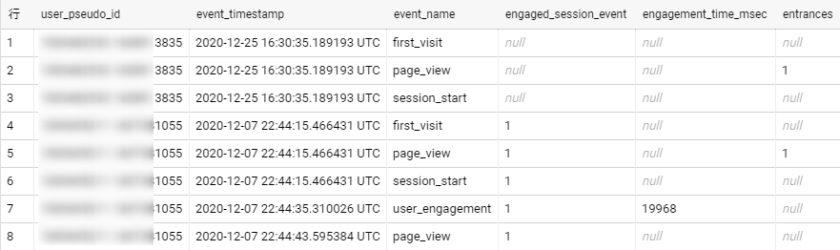
アクセスログでは1行が1ページビューである。一方でアクセス解析ではセッションやユニークユーザ単位での分析をすることも多く(今月トータルで○○セッション、うちPCは○○セッション。UU数は○○、…)、実現のためにはログにセッションIDやユーザIDをつける必要がある。
疑似ユニークユーザ
webサーバの設定でcookieを使ったトラッキングを行い、ユーザIDをログに出力している場合はユニークユーザの特定が可能。
デフォルトではそうなっていないため、webサーバのログにはユーザIDが残っていないことが多い。
その場合は便宜的に
IPアドレス+UserAgentの文字列(ブラウザ)
が同一のものをユニークユーザとしてみなす。
同時に同一IPアドレスかつ同一ブラウザの複数ユーザからのアクセスがあれば仕方ない。
企業からのアクセスやモバイルの場合は普通にその可能性があるが、目をつぶるしかない。
alter table log add column uid varchar(1000);
update log set uid = c_ip || cs_User_Agent;
単純にトラフィック元のIPアドレスにUserAgentの文字列をくっつけただけである。
UserAgentの文字列が長い場合はハッシュ化すればよい。
セッション
セッションの定義はあいまいだが、概念としては「同じユーザの1回の訪問(=一連のページビュー)」のこと。
あとはサーバや計測ツールの定義によって「1回の訪問」をどこからどこまでとするかが異なる。
セッションIDは
- Webサーバ自体がセッションIDをログ書き出す→CMSなどのプログラム側で設定することで可能
- サーバにそのようのような実装がない場合は機械的に「同じユーザ(ID)の最終PVから○分以内のページビューは同一セッションとしてカウントする」と扱うしかない。
標準的な定義では最後のページビューから30分以内のページビューを前のセッションに含め、
30分過ぎたページビューは新しいセッションとしてカウントすることが多い。
いずれにせよ前項のユニークユーザの識別ができていることが前提となる。
cookie単位でのIDがない場合はIPアドレスとブラウザ(UserAgent)の組み合わせでやるしかない。
ログから「最後のページビューから30分以内のページビュー」を識別するためには、
そのユーザの最後のページビューからの経過時間を新しい変数として追加する必要がある。
なおRDBでセッション分析や経過時間を扱う場合、ウィンドウ関数を使うことになる。オープンソースではMySQLやSQLiteはダメで、PostgreSQL(やその派生版RDB)でないと使えない。商用DBやデータ分析用のRDBならOK。
ウィンドウ関数の説明は長くなるので省略するが、詳細は以下などを参照。
http://lets.postgresql.jp/documents/technical/window_functions
前回のページビューの時刻をウィンドウ関数LAG()で取得し、
今回のページビューの時刻との差分をとれば前回のページビューからの経過時間が分かる。
drop table if exists log_ses;
select *, datetime - lag(datetime) over (partition by uid order by datetime) as interval into log_ses from log;
経過時間が30分以内のページビューは継続セッションフラグを立てる。
alter table log_ses add column continued boolean default false;
update log_ses set continued = true where interval < cast('00:30:00' as time);
各セッションの最初のページビューを抽出してセッションIDを付ける。
row_number() over()で連番を生成してセッションIDとする。
drop table if exists log_firstpv;
select uid, c_ip, cs_user_agent, datetime, row_number() over() as session_id into log_firstpv from log_ses where continued = false order by datetime;
集計単位URLの指定
同一コンテンツ同一URLの原則が守られているならいいが、実際にはそうでないことも多い。そこで集計したいURLの単位で
- URLごとのPV数を集計する際、同じページとして扱うURLを集約
- 末尾の「/」の有無を統一
- ダミーパラメータの除外
をする必要がある。
URLの集約
パラメータがなく、拡張子がなく、末尾に「/」の付いていないURLをすべて「/」付きに変換
-- 集約済みURLの列を追加
alter table log_ses add column aggregated_path varchar(10000) default null;
-- 本処理
update log_ses set aggregated_path = request_path || '/' where request_path not like '%?%' and request_path !~ '(\\.\\w{2,4}|/)$';
URLのコンポーネント分割
ダミーパラメータの除外など今後の処理を行うためにURLの文字列を
- (プロトコル+)ホスト名
- パス
- クエリ文字列
- ハッシュ
に分割するのがいい。
サーバログにはパスとクエリ文字列しか残らない(ホスト名とハッシュは入らない)が、JavaScriptを使った計測ツールのログではホスト名やハッシュが付くことがある。
サーバログのrequest_pathからパスとクエリ文字列を抽出する場合
-- パスとクエリ文字列の列を追加
alter table log_ses
add column path varchar(10000) default null;
add column query varchar(10000) default null;
-- 抽出
update log_ses set path = regexp_replace(request_path, '^(/[^?]*).*', '\\1');
update log_ses set query = regexp_replace(request_path, '^(/[^?]*)(.*)', '\\2');
URLの入ったログからパスとクエリ文字列を抽出する場合
URLの列名がrequest_urlの場合
-- URLのコンポーネントの列を追加
alter table log_ses
add column hostname varchar(10000) default null;
add column path varchar(10000) default null;
add column query varchar(10000) default null;
add column hash varchar(10000) default null;
-- 抽出
update log_ses set hostname = regexp_replace(request_url, '(^[a-z]+://)([^/]+)(/.*)', '\\2');
update log_ses set path = regexp_replace(request_url, '^([a-z]+://)([^/]+)(/[^?]*)(.*)', '\\3');
update log_ses set query = regexp_replace(request_url, '^([a-z]+://)([^/]+)(/[^?]*)([^#]*)(.*)', '\\4');
update log_ses set hash = regexp_replace(request_url, '^([a-z]+://)([^/]+)(/[^?]*)([^#]*)(.*)', '\\5');
以上のようにURLをコンポーネントに分割しておくと、後述のクエリ文字列に対する処理などがやりやすくなる。
ダミーパラメータの除外
ダミーパラメータ名がutm_***, _gaの場合
update log_ses set query = regexp_replace(query, '[?&](utm_\w+|_ga)(=[^&]*)?', '', 'g');
URLを分割してクエリ文字列のみ抽出しておくとまとめて置換できる。
分析に必要な変数を追加
デバイス、ブラウザを変数として追加
-- デバイス
alter table log add column device varchar(30);
--update log set device = NULL;
update log set device = 'Windows Phone' where cs_User_Agent like '%Windows%' and cs_User_Agent like '%Phone%';
update log set device = 'Android Phone' where cs_User_Agent like '%Android%' and cs_User_Agent like '%Mobile%';
update log set device = 'FirefoxOS Phone' where cs_User_Agent like '%Firefox%' and cs_User_Agent like '%Mobile%';
update log set device = 'BlackBerry Phone' where cs_User_Agent like '%BlackBerry%';
update log set device = 'Kindle' where cs_User_Agent like '%Kindle%' or cs_User_Agent like '%Silk%';
update log set device = 'Android Tablet' where cs_User_Agent like '%Android%' and cs_User_Agent not like '%Mobile%';
update log set device = 'Windows Tablet' where cs_User_Agent like '%Windows%' and cs_User_Agent like '%Touch%' and cs_User_Agent not like '%Tablet PC%';
update log set device = 'FirefoxOS Tablet' where cs_User_Agent like '%Firefox%' and cs_User_Agent like '%Tablet%';
update log set device = 'BlackBerry Tablet' where cs_User_Agent like '%PlayBook%';
update log set device = 'iPod' where cs_User_Agent like '%iPod%';
update log set device = 'iPhone' where cs_User_Agent like '%iPhone%';
update log set device = 'iPad' where cs_User_Agent like '%iPad%';
update log set device = 'Feature Phone' where cs_User_Agent like '%jig browser%' or cs_User_Agent like 'DoCoMo/%';
update log set device = 'Macintosh PC' where cs_User_Agent like '%Macintosh%' and device is null;
update log set device = 'Windows PC' where cs_User_Agent like '%Windows%' and device is null;
update log set device = 'Linux PC' where cs_User_Agent like '%X11; Linux%' and device is null;
update log set device = 'Bot' where cs_User_Agent like '%bot%' or cs_User_Agent like '%Bot%' or cs_User_Agent like '% http://%';
update log set device = 'Bot' where device is null; -- その他はボット扱いでいい。
-- 確認
select device, count(0) from log group by device;
select count(0) from log where device is null;
select cs_User_Agent, count(0) c from log where device is null group by cs_User_Agent order by c desc;
.output 'ua.txt'
select distinct cs_User_Agent from log where device is null order by cs_User_Agent;
.output stdout
alter table log add column os varchar(30);
update log set os = 'Windows Xp' where device like 'Windows%' and cs_User_Agent like '%Windows NT 5.1%';
update log set os = 'Windows Vista' where device like 'Windows%' and cs_User_Agent like '%Windows NT 6.0%';
update log set os = 'Windows 7' where device like 'Windows%' and cs_User_Agent like '%Windows NT 6.1%';
update log set os = 'Windows 8' where device like 'Windows%' and cs_User_Agent like '%Windows NT 6.2%';
update log set os = 'Windows 8.1' where device like 'Windows%' and cs_User_Agent like '%Windows NT 6.3%';
update log set os = 'Windows 10' where device like 'Windows%' and cs_User_Agent like '%Windows NT 10.0%';
update log set os = 'Mac OS X 10.0' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_0%';
update log set os = 'Mac OS X 10.1' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_1%';
update log set os = 'Mac OS X 10.2' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_2%';
update log set os = 'Mac OS X 10.3' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_3%';
update log set os = 'Mac OS X 10.4' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_4%';
update log set os = 'Mac OS X 10.5' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_5%';
update log set os = 'Mac OS X 10.6' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_6%';
update log set os = 'Mac OS X 10.7' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_7%';
update log set os = 'Mac OS X 10.8' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_8%';
update log set os = 'Mac OS X 10.9' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_9%';
update log set os = 'Mac OS X 10.10' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_10%';
update log set os = 'Mac OS X 10.11' where device = 'Macintosh PC' and cs_User_Agent like '% OS X 10_11%';
update log set os = 'Android 2.2' where cs_User_Agent like '% Android 2.2%';
update log set os = 'Android 2.3' where cs_User_Agent like '% Android 2.3%';
update log set os = 'Android 3.0' where cs_User_Agent like '% Android 3.0%';
update log set os = 'Android 3.1' where cs_User_Agent like '% Android 3.1%';
update log set os = 'Android 3.2' where cs_User_Agent like '% Android 3.2%';
update log set os = 'Android 4.0' where cs_User_Agent like '% Android 4.0%';
update log set os = 'Android 4.1' where cs_User_Agent like '% Android 4.1%';
update log set os = 'Android 4.2' where cs_User_Agent like '% Android 4.2%';
update log set os = 'Android 4.3' where cs_User_Agent like '% Android 4.3%';
update log set os = 'Android 4.4' where cs_User_Agent like '% Android 4.4%';
update log set os = 'Android 5.0' where cs_User_Agent like '% Android 5.0%';
update log set os = 'Android 5.1' where cs_User_Agent like '% Android 5.1%';
update log set os = 'Android 6.0' where cs_User_Agent like '% Android 6.0%';
update log set os = 'iOS 4' where (device = 'iPhone' or device = 'iPod' or device = 'iPad') and cs_User_Agent like '% OS 4_%';
update log set os = 'iOS 5' where (device = 'iPhone' or device = 'iPod' or device = 'iPad') and cs_User_Agent like '% OS 5_%';
update log set os = 'iOS 6' where (device = 'iPhone' or device = 'iPod' or device = 'iPad') and cs_User_Agent like '% OS 6%';
update log set os = 'iOS 7' where (device = 'iPhone' or device = 'iPod' or device = 'iPad') and cs_User_Agent like '% OS 7_%';
update log set os = 'iOS 8' where (device = 'iPhone' or device = 'iPod' or device = 'iPad') and cs_User_Agent like '% OS 8_%';
update log set os = 'iOS 9' where (device = 'iPhone' or device = 'iPod' or device = 'iPad') and cs_User_Agent like '% OS 9_%';
update log set os = 'linux' where device = 'Linux PC';
update log set os = 'BlackBerry' where device like 'BlackBerry%';
update log set os = 'FirefoxOS' where device like 'FirefoxOS%';
--select count(0) from log where os is null and device != 'Bot' and device != 'Feature Phone';
--select cs_User_Agent, count(0) c from log where os is null and device != 'Bot' and device != 'Feature Phone' group by cs_User_Agent order by c desc;
デバイスとOSごとのセッションを集計してCSVファイルに出力する。
copy (select device, os, count(0) n from log_ses where continued = false group by device, os order by device) to 'd:\devices.csv' (format csv);
流入元識別
リファラを使う
alter table log_ses add column source varchar(1000) default null;
update log_ses set source = 'google' where continued = false and referer like 'https://www.google.%';
update log_ses set source = 'yahoo' where continued = false and referer like 'https://search.yahoo.co.jp/%';
update log_ses set source = 'twitter' where continued = false and referer ~ '^https?://(twitter\.com|t\.co)/';
流入識別のダミーパラメータが付いている場合
広告のリンク先URLでパラメータを付けている場合など
たとえば以下のようなDDLで定義されるキャンペーンマスタがあり、
create table campaign (
campaign_code VARCHAR(100),
campaign_name VARCHAR(100)
);
キャンペーンを表すパラメータ名が「cid」の場合
UPDATE JOINを使ってキャンペーン名を結合する。
-- キャンペーンコードとキャンペーン名のカラムを作成
alter table log_ses
add column campaign_code varchar(10000) default null,
add column campaign_name varchar(100) default null;
-- リクエストパスからキャンペーンパラメータを抽出
update log_ses set campaign_code = regexp_replace(query, '.*[?&]cid=([^&]*).*', '\\1') where request_path ~ '[?&]cid=[^&]*';
-- キャンペーンマスタを参照してキャンペーンパラメータに対応したキャンペーン名を入れる
update log_tmp set campaign_name = campaign.campaign_name from campaign where log_ses.campaign_code = campaign.campaign_code and continued = false;
アクセス解析関連記事

アクセス解析 の記事一覧