
GCPのIAMポリシー

概要
GCPのIAMポリシー(権限設定)
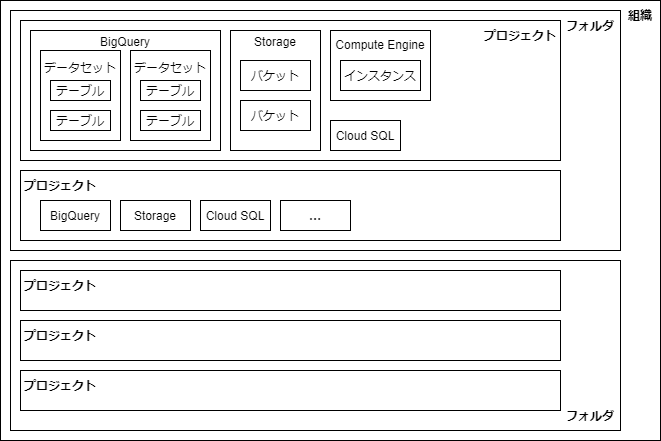
GCPにおける階層と言葉の定義
- 組織
- (フォルダ)
- プロジェクト
- 各種リソース
- Cloud Storage
- BigQuery
- Compute Engine
:
アカウント
アカウントには2種類
ユーザーアカウント
- Googleのログイン画面からログインできるアカウント
- 人間ユーザ。異動や退職とともにアカウントがなくなるケースも想定する必要がある
- 一部のGoogleアカウントではアカウント単位のコストが発生することも想定する(つまり有限個しか発行できない)
- Googleアカウントである必要がある→認証はメールアドレスとパスワードで行う
- Gmail
- Workspace
- Cloud Identity
サービスアカウント
- システムがGCPにアクセスする際に使うアカウント
- Googleのログイン画面からログインすることはない
- 異動や退職で使えなくなるケースはない
- メールアドレス形式
service-account-name@project-id.iam.gserviceaccount.com - 認証は主にJSONの鍵ファイルを使って行う
- アカウントごとのコストは発生しないので実質無限個発行できると考えていい
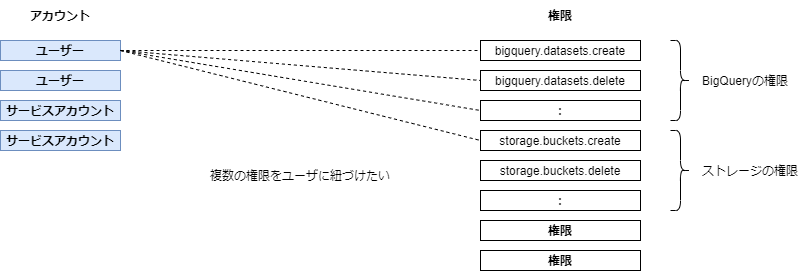
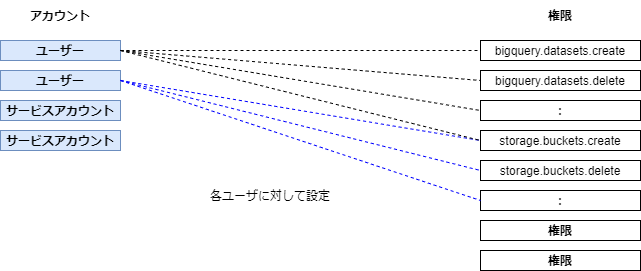
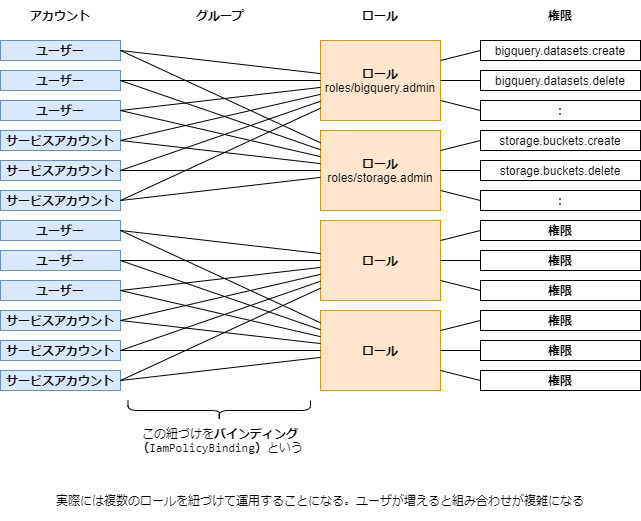
アカウントと権限の紐付けのパターン
出てくる言葉
- アカウント
- グループ
- ロール
- 権限
目的:アカウントと権限を紐づけること。その間のハブとしてグループやロールがあると考えればいい
アカウントと権限がある
ロール
直接アカウントと権限を紐づけるのではなく、ロールを介して設定する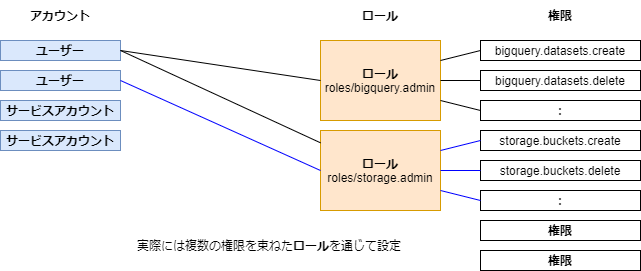
roles/storage.objectViewer
付随する権限
resourcemanager.projects.getresourcemanager.projects.liststorage.objects.getstorage.objects.list
Cloud Storageでファイル一覧を表示してダウンロードするには複数の権限を設定する必要がある。それを「オブジェクト閲覧者」という一般的な役割単位で束ねたものをロールという。 GCPには事前定義ロールが用意されている。これ以外に柔軟にユーザ定義ロールを設定することも可能。 ※基本ロールは使わない(実運用には粒度が荒すぎる) つまりロールというのは、GCP内の細かい権限体系を使いやすい単位のちょうどいい粒度にまとめたものである。
グループ
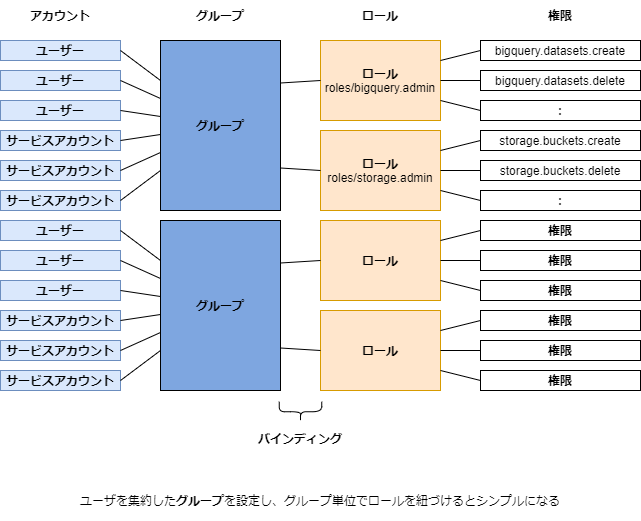
その他の言葉の定義
- ユーザやグループなど、ロールを付与する対象を今ではプリンシパルという。古いドキュメントでは「メンバー」と言われているものもあるが同じ意味
- ロールとプリンシパルの紐づけをバインディング(IamPolicyBinding)という
ロールの階層
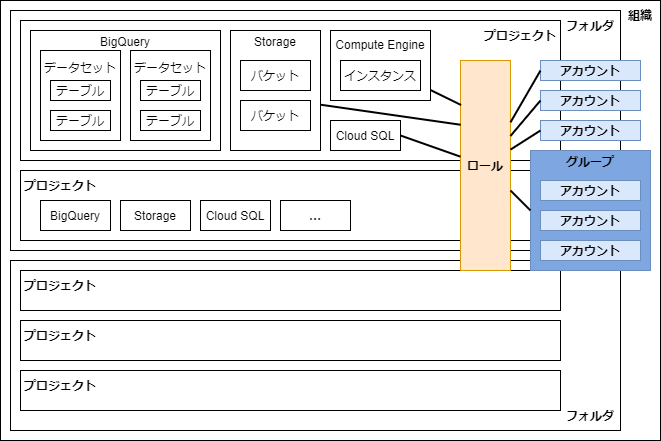
- リソース単位
- プロジェクト単位
- 組織単位
の順に大きくなる
- 多くのリソースはプロジェクト単位で設定する
- データを扱うものはもっと細かい単位で設定可能
- BigQueryではデータセット、テーブル、ビュー単位
- Storageではバケット単位
で設定できる。つまり特定のデータセットやバケットに限定したアクセス権を設定できる(そうでないと使えない)
- それ以外では、Compute Engineでインスタンス単位の設定が可能
継承がある
- 組織単位で設定したロールの権限はその配下のプロジェクトすべてに適用される
- プロジェクト単位で設定したBigQueryのロールの権限はその配下のデータセットすべてに適用される
- プロジェクト単位で設定したストレージのロールの権限はその配下のバケットすべてに適用される
具体的な話は後述する
BigQuery
計算権限とストレージ(データアクセス)権限のセットで考える https://techblog.zozo.com/entry/bigquerys-permission-from-architectural-perspective (例)計算権限はあるがデータアクセス権がない場合、
SELECT CURRENT_DATE();
のようなデータを使わないクエリは実行できるが、データは参照できない(FROM ...できない)。
計算系の権限をまとめたロール
- BigQueryジョブユーザー
roles/bigquery.jobUser - BigQueryユーザー
roles/bigquery.user
ジョブユーザーはジョブ(クエリ実行、インポート/エクスポート)を実行するだけの権限。ただしインポート/エクスポートは一般的にストレージを使うため、ストレージ側の権限は別途必要。
ユーザーはそれに加えてデータセットの表示、保存済みクエリの参照権限などがある。
バッチなどのシステムでは、あらかじめ使うテーブルが決まっているので、データセット一覧を取得できる必要はない。しかし人間が分析目的などで使う場合はデータセット名がわからないと使えない。その違いがある。したがってプログラムが使う場合は「ジョブユーザー」で、人間が使う場合は「ユーザー」と考えておけば基本的にOK
ただしBigQueryユーザーではユーザが自由にデータセットを作成できてしまう、データセットが勝手に乱立する問題点がある
→そこでカスタムロールを設定する。「BigQueryユーザー」(roles/bigquery.user)からデータセット作成権限(datasets.create)のみを取り除いたロールを作ることがある。
権限を設定する階層
- BigQueryジョブユーザーはプロジェクト単位で設定する
- BigQueryユーザーはプロジェクト単位、データセット単位で設定できる。違いは以下
- プロジェクト単位で設定した場合、プロジェクト内の全データセットの一覧表示できる
- データセット単位で設定した場合、アクセス権を付与したデータセットのみ一覧表示できる
データアクセス権限をまとめたロール
- データ閲覧者
roles/bigquery.dataViewer
データセット情報、テーブル、ビュー、機械学習モデルの取得 - データ編集者
roles/bigquery.dataEditor
それに加えてテーブルの作成、削除ができる。データセットは作成のみできる - データオーナー
roles/bigquery.dataOwner
それに加えてデータセットの変更(共有設定を含む)ができる。
権限を設定する階層(粒度) これらの権限は
- テーブル/ビュー
- データセット
- プロジェクト
- 組織
各階層で設定できる。GCP管理画面上の設定個所は
- 組織またはプロジェクト(内のすべてのデータセット)にアクセス権限を設定する場合はIAM設定画面
- データセットに対するアクセス権限を設定する場合はデータセット画面の「共有データセット」
- テーブルやビューに対してアクセス権限を設定する場合はテーブル画面の「テーブルを共有」
またテーブルやビューの行や列単位でのアクセス権限を設定することも可能。GCP管理画面上の設定個所は
- 列単位でアクセス権限を設定する場合はテーブルのスキーマ画面の列の「ポリシータグ」
- 行単位でアクセス権限を設定する場合はテーブルのスキーマ画面の「行アクセス ポリシー」
データアクセス権限だけでなくBigQueryユーザーのロールを含めて、
- プロジェクトで権限設定する場合は
gcloudコマンド- Cloud Resource Manager API
- データセットやテーブルで権限設定する場合は
bqコマンド- BigQuery API
を使う。
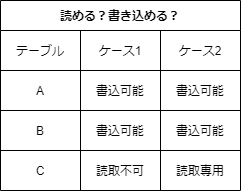
複数の階層で権限設定が重複した場合、より強いものが優先される。
(例)以下の2ケースでテーブルA,B,Cは読める?書き込める?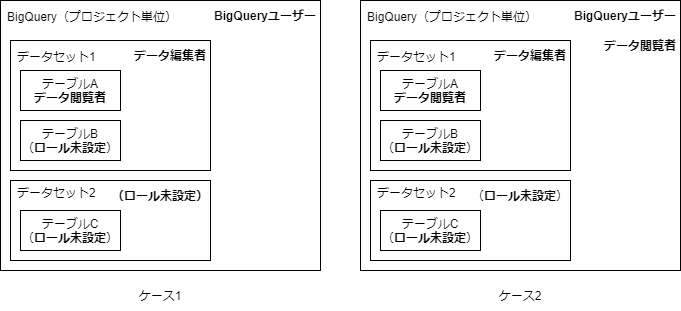
その他のBigQueryに関する権限
- 計算スロットの予約
- BI Engine
- ML(機械学習モデル)
などいろいろあるが、まずは基本のデータに対するアクセス権設定は押さえておこう。
Cloud Storage
BigQueryのような計算権限はなく、データアクセス権のみを考えればいい。
Storage Transferを使用する場合はその権限は別途設定する。
ストレージにはレガシーACLとIAMという2種類の権限設定方法がある。どちらも使えるが、レガシーは過去の設定との互換性のために残っているだけなので、今後はIAMのみを使って設定する。レガシーACLのロールは「ストレージ レガシー ***」roles/storage.legacy***という名前になっているので、それ以外のロールを使おう。
通常使うロール
- ストレージのオブジェクト閲覧者
roles/storage.objectViewer
ファイルの読み取り専用 - ストレージのオブジェクト作成者
roles/storage.objectCreator
ファイルの作成が可能。ファイルの削除や上書きはできない - ストレージのオブジェクト管理者
roles/storage.objectAdmin
ファイルの削除や上書きができる - ストレージ管理者
roles/storage.admin
バケットの作成削除ができる
いずれもプロジェクト単位、バケット単位いずれでも設定可能。プロジェクト単位の設定とバケット単位の設定が重複したらより強い権限が適用される。