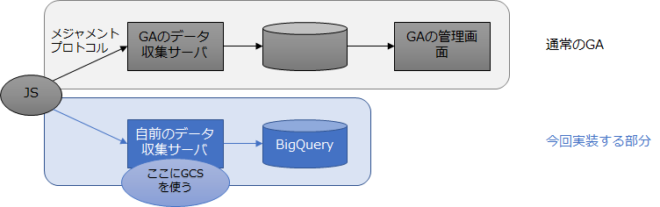
Googleアナリティクスで収集しているデータ(メジャメントプロトコル)をBigQueryに送り、集計・可視化できるようにする。無料版のGAにも対応し、しかもサーバレスでシンプルに実装できる。
本来BigQueryを使ったウェブ行動の詳細分析はGA360を使うべきなのだが、限りなく低コストでこんなことができるという参考程度で紹介する。
通常無料版のGoogleアナリティクスではできないログベースの行動分析をするのに使ったり、有料版であったとしてもGAはどのようなトラフィックを除外して集計しているのか、Googlebotなどのクローラがどんな動きをしているのかなどを検証するのに使うといいかもしれない。
原理はGoogleアナリティクスのJavaScriptがGoogleの計測サーバに送っているパケットを自前のサーバに送ってログ化するというシンプルなものである。
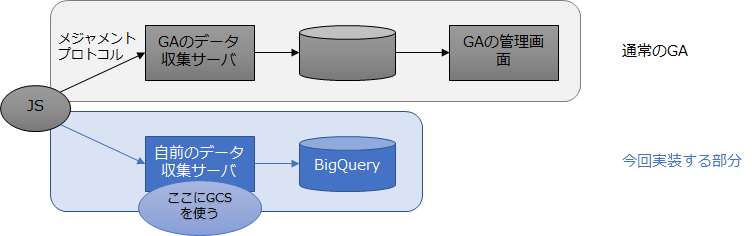
従来はデータ収集用のサーバを構築する必要があったが、Google Cloud Storageを使うことでサーバをわざわざ立ち上げなくても不要ログ収集ができる。
Google Cloud Storageは単にストレージだけでなく、インターネットにコンテンツを配信する簡単なCDNとして使うことができるうえ、設定によってログを出力することができる。そこでGCS上にwebビーコンつまりは空のGIF画像を設置しておいて、そこにオーディエンスがwebアクセスするようにすれば、そのアクセスログを生成できるのである。ビーコンへのリクエストにはPOSTはできないがGET(URLのクエリ文字列の形式)でさまざまなデータを送ることはできる。そのURLに付いたクエリ文字列がIPアドレスなどとともにそのままログに残る。
データ収集サーバの実装がストレージの設定だけで実現できる。データのサイズは空のGIF画像であるうえ、GCSにはキャッシュ機能がありキャッシュヒットは転送料金が無料であるということで、コストも知れている。
目次
Google Cloud Storageの設定
ビーコンを配置するバケットとログを格納するバケットを用意
- ビーコンを配置するバケット:
axpp - ログを格納するバケット:
log_axpp
Google Cloud Storageのコンソールを開いてまずビーコンを配置するバケットを作成する。
アクセスする頻度が高いが世界中からアクセスされるわけではないのでRegionalでいい。リージョンは日本で使うならasia-northeast1がいいが、ここではテストのため安いus-west1にしている。
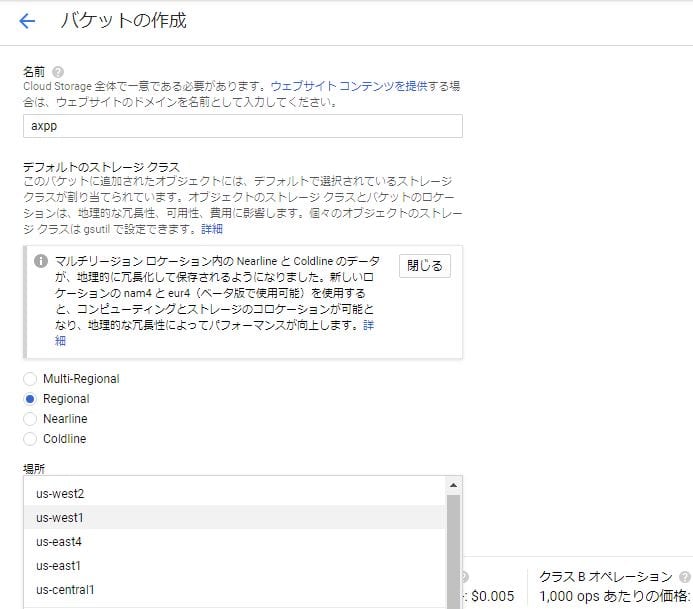
一般ウェブ公開するための権限を付与する。
作成したバケットの画面のメニューから「権限」を選択し、権限設定画面で「メンバーを追加」をクリックする。
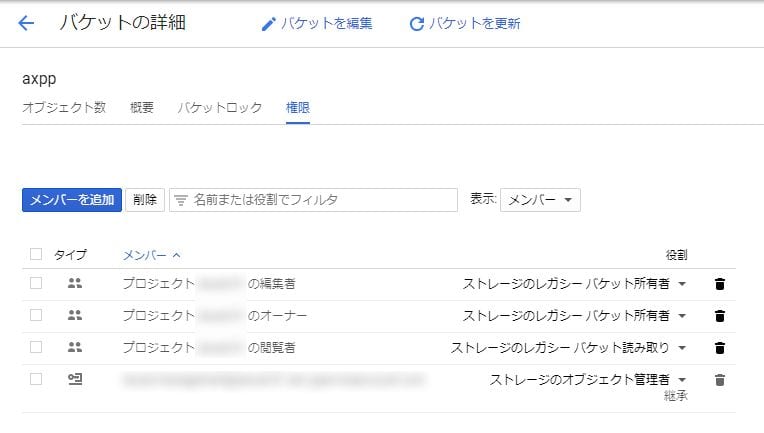
「allUser」と入力し、「役割を選択」から
ストレージ>ストレージ オブジェクト閲覧者
を指定する。
戻った画面がこのようになる。
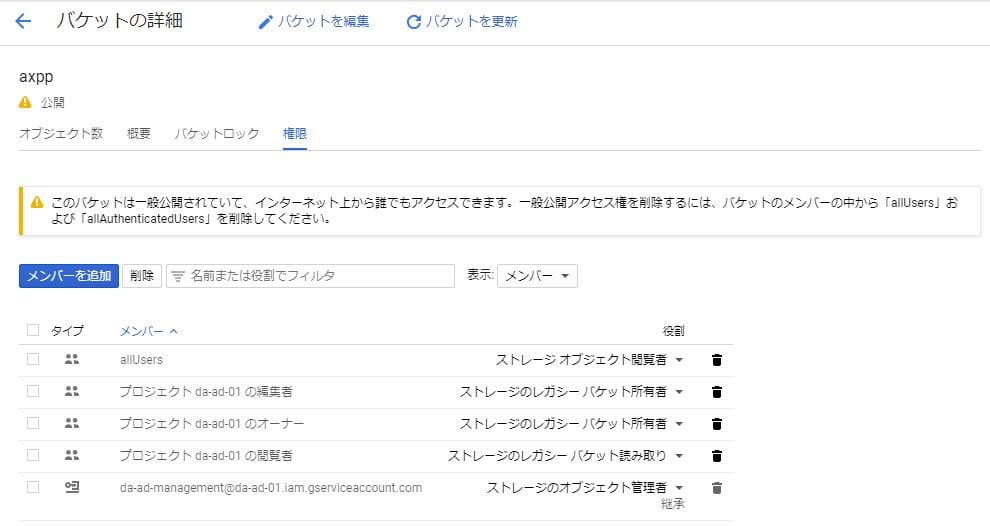
ビーコンをweb一般公開する
ビーコンを設置する。1×1の空GIF(スペーサー)を準備し、今作ったバケットにアップロードする。
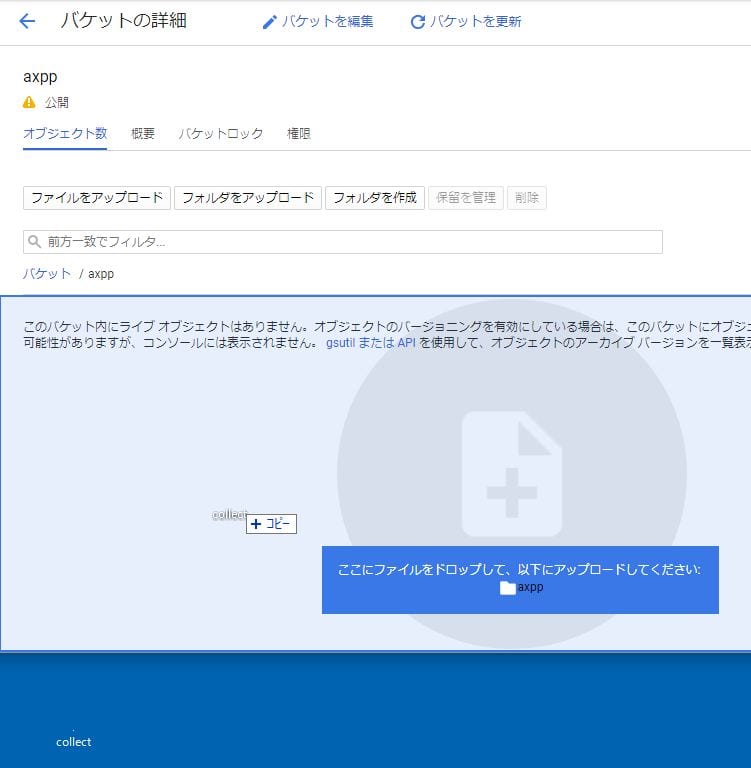
MIME設定でこのファイルが画像ファイルであることを指定する。
アップロードした空GIFファイルの右のケバブのアイコンをクリックし、「メタデータを編集」
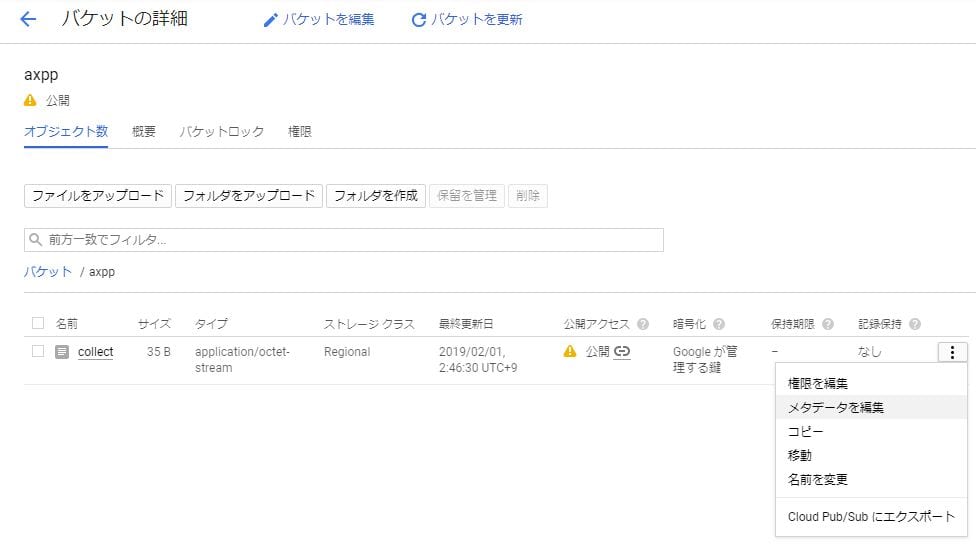
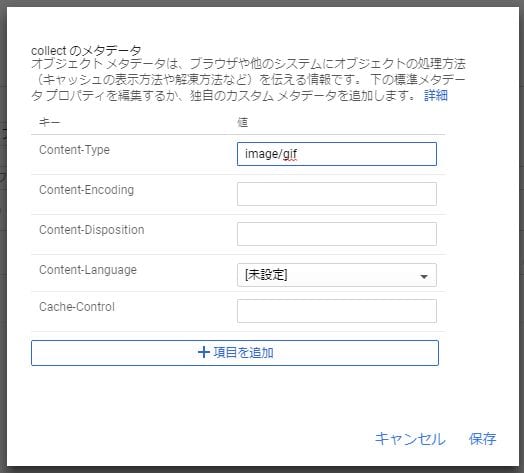
Content-Typeに
image/gif
を指定する。
上記の設定の場合、webで「https://storage.googleapis.com/axpp/collect」にアクセスすると空GIFにアクセスされる。バケット名やビーコンファイル名を変えるとこのURLも変わる。
ビーコンへのアクセスをログに出力する設定
ログファイルを格納するバケットを作成する。バケットの作り方は先と同じで、権限設定が異なる。
cloud-storage-analytics@google.com
に
ストレージ>ストレージのオブジェクト作成者
を指定する。
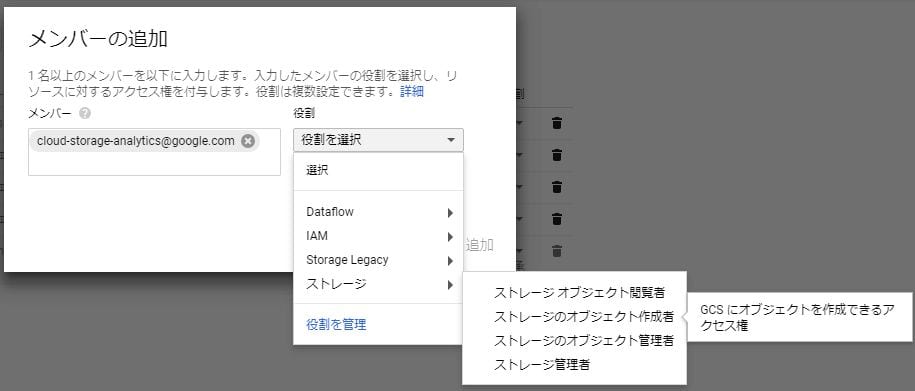
必要なバケットを作成したらこのようになる。
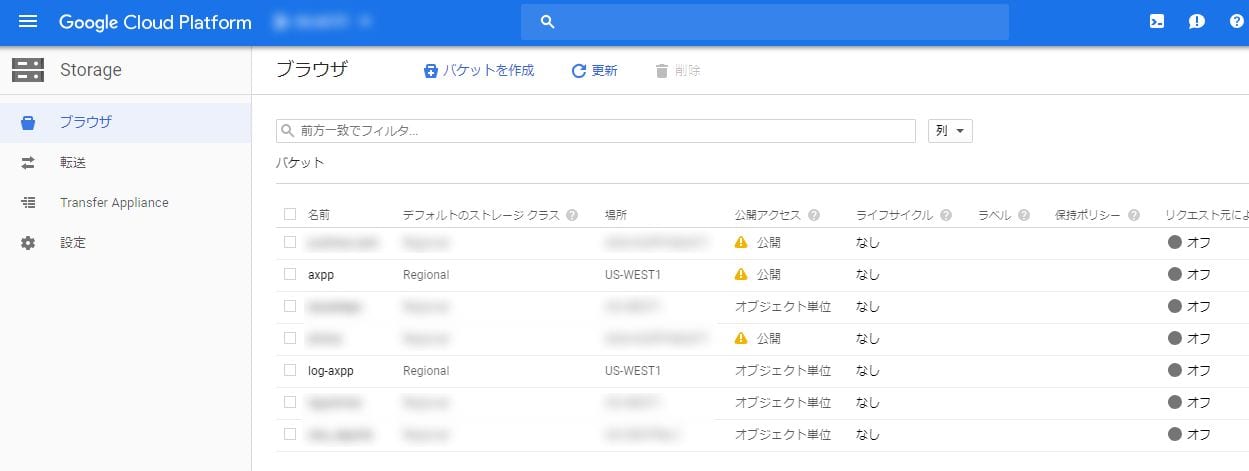
次にファイルへのアクセスをログに出力する設定を行う。こちらはこれまでと異なりコマンドラインでの設定が必要となる。GCPの管理画面上でのCloud Shellでも可能なので、管理画面右上(青いヘッダ部分)のターミナルのアイコンをクリックすると画面下に黒背景のターミナルが立ち上がる。
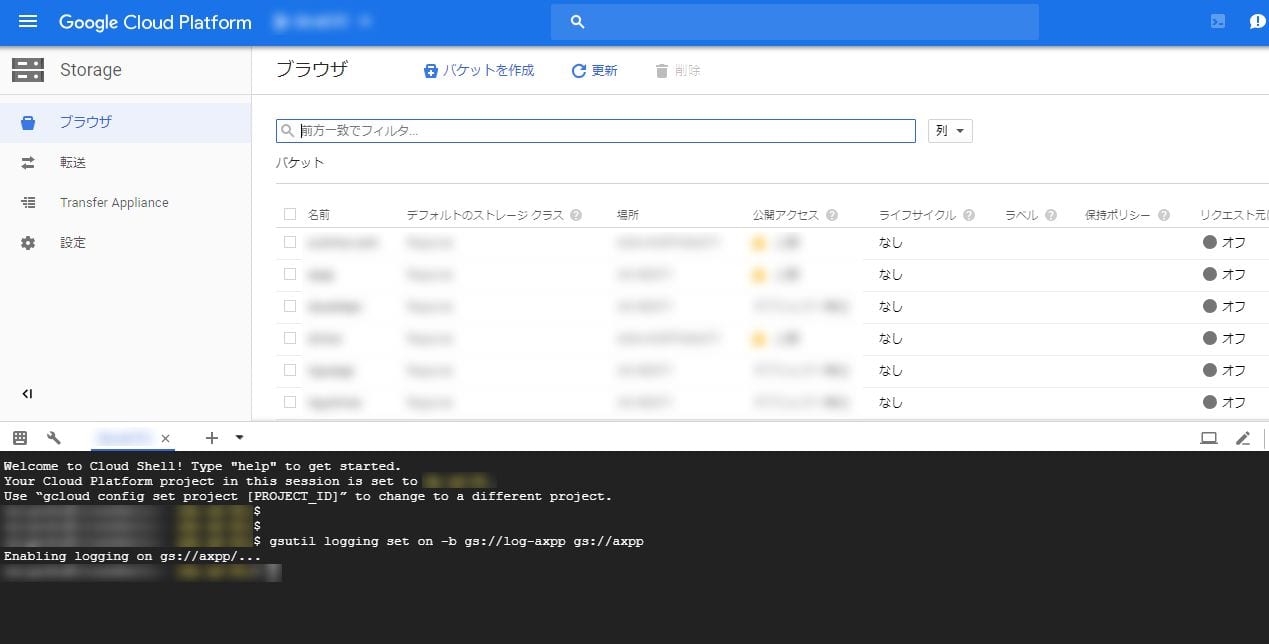
そこで
gsutil logging set on -b gs://log-axpp gs://axpp
を実行する。バケットの名前はそれぞれ自分が作ったものを指定する。
このあたりの設定の詳細は以下を参照。
https://cloud.google.com/storage/docs/access-logs
GTMの設定
GAのデータ収集サーバに送るパケットを上のビーコンに送る設定を行う。
GTMでGoogleアナリティクスの設定を行っている前提で、GTM上での設定を説明する。
customTaskという機能を使う。これはGAがデータ収集サーバにパケットを送るときに、パケットを送る直前に任意の動作を指定するものになる。その「任意の動作」として自前ビーコンにパケットを送る動作を指定するわけである。
GTMでは変数のJavaScript変数としてcustomTaskの内容を定義する。customTaskの機能を使っていない場合は新たにJavaScript変数を作成する。clientIdの取得などですでにcustomTaskを使っている場合、その記述の下に記入する。
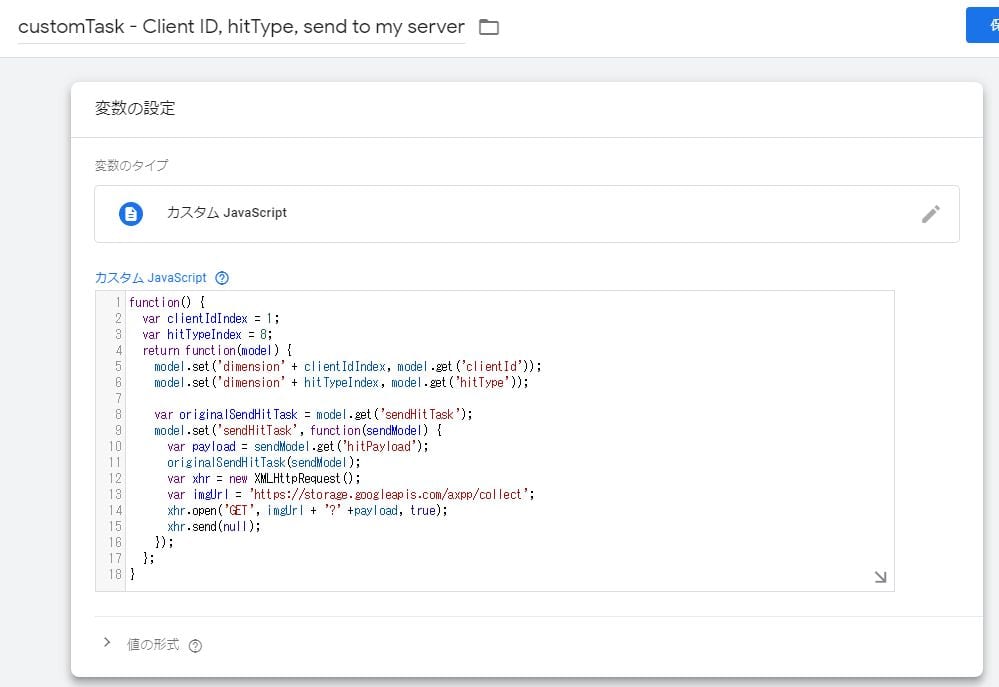
以下のようにコードを入れる。customTask変数の新規作成の場合は「// 元々...」の行がない。
function() {
var clientIdIndex = 1; // 元々customTaskにある記述はそのまま残す
var hitTypeIndex = 8; // 元々customTaskにある記述はそのまま残す
return function(model) {
model.set('dimension' + clientIdIndex, model.get('clientId')); // 元々customTaskにある記述
model.set('dimension' + hitTypeIndex, model.get('hitType')); // 元々customTaskにある記述
var originalSendHitTask = model.get('sendHitTask');
model.set('sendHitTask', function(sendModel) {
var payload = sendModel.get('hitPayload');
originalSendHitTask(sendModel);
var xhr = new XMLHttpRequest();
var imgUrl = 'https://storage.googleapis.com/axpp/collect';
xhr.open('GET', imgUrl + '?' +payload, true);
xhr.send(null);
});
};
}
ここで重要なのがcustomTaskで登録するということ。Googleアナリティクスタグのフィールド設定で直接sendHitTaskを指定できるが、これを使うとうまくいかない。実はoriginalSendHitTask()を使う場合はそのようにしないと正しく動作しない問題がある(上級者向け)。
'https://storage.googleapis.com/axpp/collect'の部分でビーコンのURLを指定する。HTTPSにするのを忘れないこと。
変数の設定後、GoogleアナリティクスのフィールドでcustomTaskとして登録する。
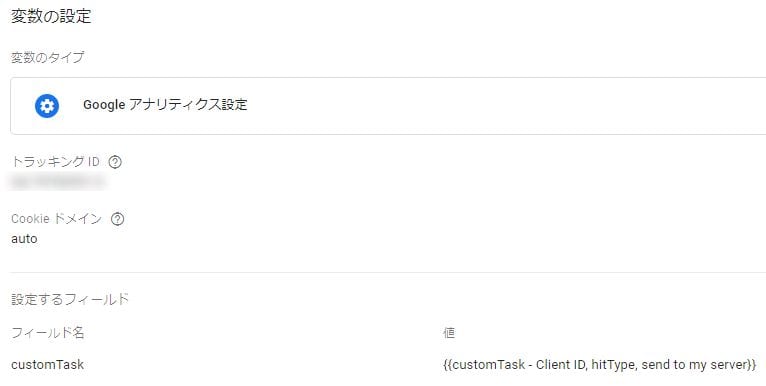
動作検証はパケットを確認する。ブラウザの開発者ツールで「collect」を含むパケットを探す。GAのデータ収集サーバに送られるパケット(メジャメントプロトコル)は以下のようなものだが、
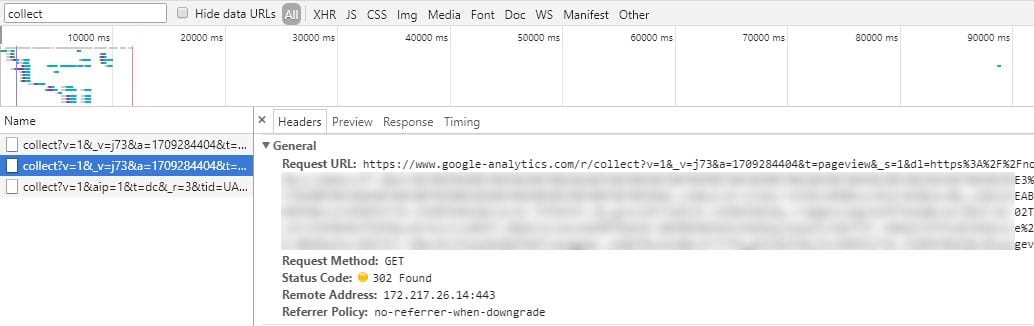
リクエストURLは「https://www.google-analytics.com/r/collect」になっている。
今度は自前ビーコンへのパケットだが、クエリ文字列が同じでホスト名とパスが上で作ったものになる。
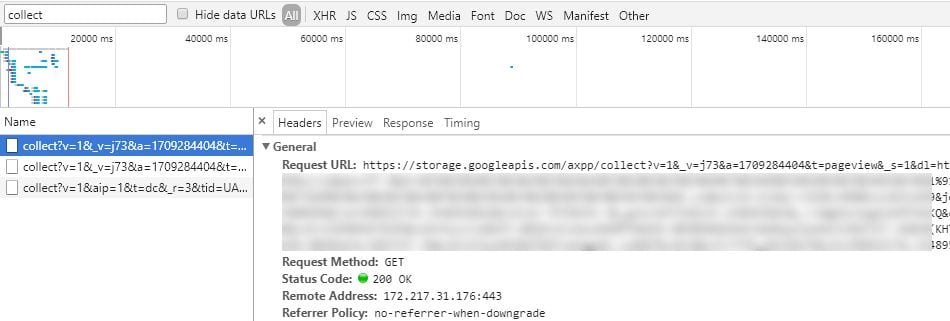
今回は「https://storage.googleapis.com/axpp/collect」である。
これで正常に動作していることになる。
BigQuery
ログデータのBigQueryへのインポート
ログがたまったらBigQueryに取り込む。ログファイルがたまると以下のようになるので、
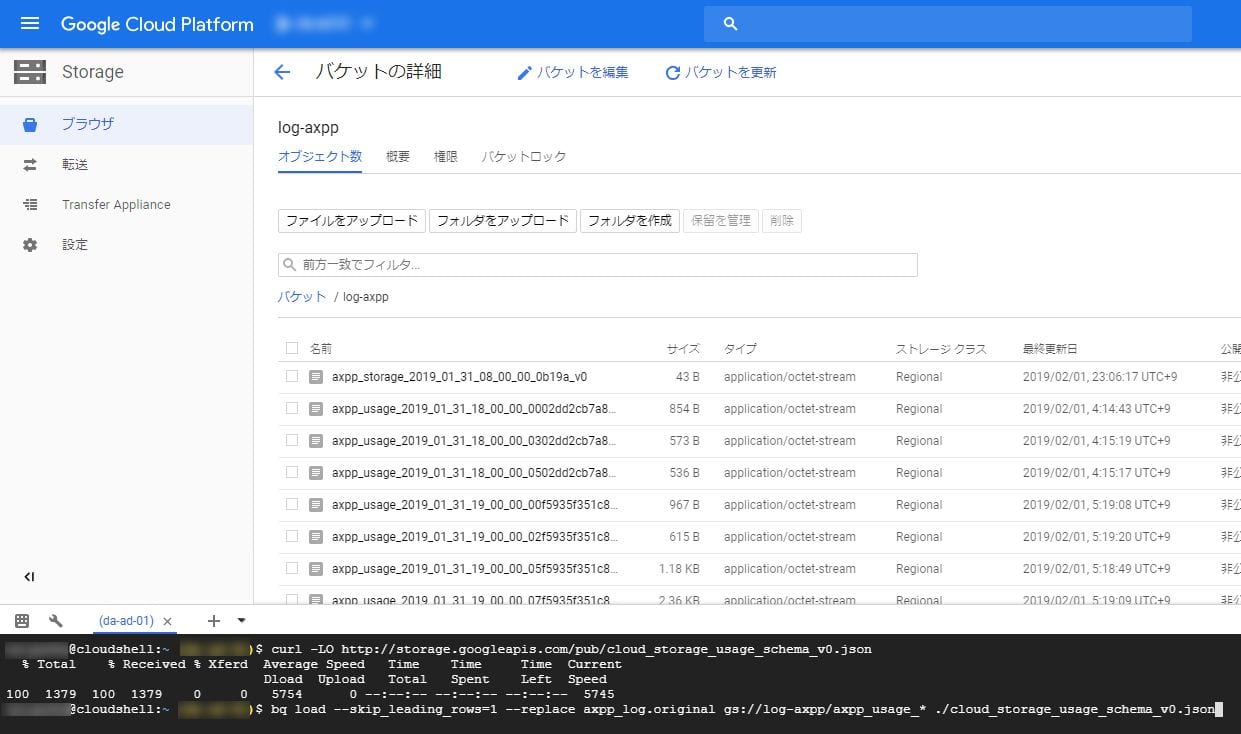
Google Cloud Shellを起動し、以下のコマンドを実行する。
- ログファイル
- バケット:
log-axpp - ファイル:
axpp_usage_*
- バケット:
- 取り込み先
- データセット:
axpp_log - テーブル:
original
- データセット:
# ログファイルの列の定義ファイルのダウンロード
curl -LO http://storage.googleapis.com/pub/cloud_storage_usage_schema_v0.json
# データセットを作成する(未作成の場合のみ)
bq mk axpp_log
# 実際の取り込みコマンド
bq load --skip_leading_rows=1 --replace axpp_log.original gs://log-axpp/axpp_usage_* ./cloud_storage_usage_schema_v0.json
ログにはstorageログとusageログの2種類あるが、usageログのみでいい。axpp_usage_*でusageログのみ指定している。実際にはreplaceではなく日次バッチなどで追加されたファイルだけappendしていく形になるだろう。
一般的で使いやすいデータ形式に変換
取り込んだデータが以下のようになる。

1行1ヒットの形式でデータが入っている。そこにIPアドレスやタイムスタンプ(マイクロ秒形式)などが含まれる。cs_uriがビーコンのURIで、ここにクエリ文字列の形式で送ったcidなどさまざまなパラメータの値が入っている。このままのデータ形式では扱いにくいので、扱いやすい形式に加工する。
ここではGA360でカスタムディメンションを格納しているようなBigQueryのrepeated record形式を使う。すべてのパラメータ変数を列に展開する方法もあるが、値が入っていたり入っていなかったりするうえ、不要な変数もあるかもしれない。GA360でも使われているし、BigQueryだとこの方法がスマートである。
データセットaxpp_logのテーブルformat1に加工したデータを入れる場合、以下のクエリになる。
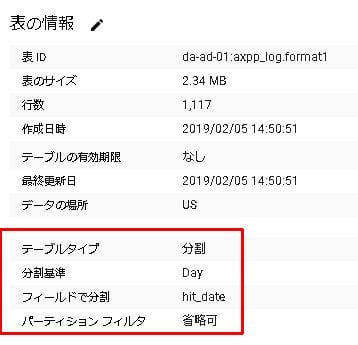
なおヒットの日付でパーティション分割されたテーブルにしている。レコード数が増えても分割しておけばクエリ節約可能になる。
create or replace table `axpp_log.format1` partition by hit_date as
with t1 as (
-- ごくまれに重複が発生することがあるらしい
select distinct * from `axpp_log.original` where cs_object = 'collect' and sc_status = 200
), t2 as (
select
* except(time_micros),
extract(datetime from timestamp_micros(time_micros) at time zone 'Asia/Tokyo') timestamp,
regexp_extract_all(cs_uri,r'(?:\?|&)(?:([^=]+)=(?:[^&]*))') key,
regexp_extract_all(cs_uri,r'(?:\?|&)(?:(?:[^=]+)=([^&]*))') value
from t1
), t3 as (
select
* except (key, value),
(select array_agg(struct(k as key, value[offset(off)] as value)) from unnest(key) k with offset off) params,
date(timestamp) hit_date
from t2
)
select * from t3;
単純なURLのクエリ文字列をこの形式にするのは大変で、クエリ自体はかなり高度になっている。このままコピーして使えばいい。
アウトプットは以下のような形式になる。
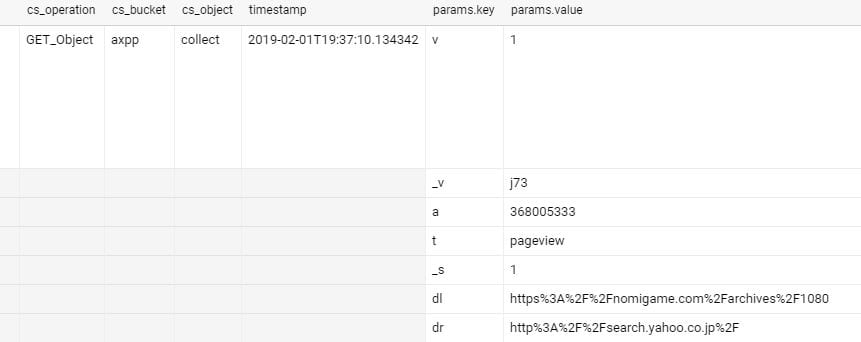
ヒットの日付(日本時間)hit_dateで分割されたテーブルになっているので、この後のクエリではこの列で絞り込むことでクエリ節約できるようになっている。
パラメータの値の取り出し
たとえばGooglebotのクロールログだけを抽出するには
-- 値はURLエンコードされているので必要に応じてデコードする。BigQueryにはネイティブの関数がないのでJavaScript関数を使う。
create temporary function url_decode(enc string)
returns string
language js as """
try {
return decodeURIComponent(enc);;
} catch (e) { return null }
return null;
""";
select
(select value from unnest(params) where key = 'cid') cid,
c_ip,
cs_user_agent,
timestamp,
(select url_decode(value) from unnest(params) where key = 'dl') dl,
(select url_decode(value) from unnest(params) where key = 'dt') dt,
(select url_decode(value) from unnest(params) where key = 'dr') dr,
(select url_decode(value) from unnest(params) where key = 'ul') ul,
(select value from unnest(params) where key = 'sr') sr,
(select value from unnest(params) where key = 'vp') vp,
(select value from unnest(params) where key = 'cd7') navigation_type
from `axpp_log.format1`
where cs_user_agent like '%Googlebot%'
order by 4,3,1,2
GA360のBigQueryでカスタムディメンションを取り出すときにおなじみの
(select value from unnest(params) where key = 'sr')
の記法を使えるのは楽。だからこのような形式のテーブルにするといい。
上記とクエリ(抽出している列)自体は違うが、このような形式になる。

cs_uriの複雑な文字列がきれいに列として分かれて出力されている。
最後に
AWSの場合はCloudFront+S3+Athenaで同様のことを実現できる。こちらはGoogleアナリティクスの機能を使わない形でのcookieを使ったトラッキングもできる。
今回はGoogleアナリティクスを拡張したデータ収集方法を紹介したが、次はBigQueryに取り込んだデータにブラウザやOS、地域など外部データを紐づけて分析しやすくする方法を紹介する。
Google の記事一覧