

最近では機械学習の計算のためにLinuxマシンを構築しては消し、を繰り返すことが多い。サーバの構築と消去が柔軟に可能なことからもEC2やGCEなどクラウドのインスタンスをよく使うということも影響している。 この記事では一般的なサーバ構築の記事では紹介されていない、クラウドのインスタンスで意外と盲点になる点を中心に、機械学習の計算用サーバとして安定した運用をするために最低限必要な設定をまとめた。 GPUドライバ(CUDA、cuDNN)やコンテナランタイム(Docker/NVIDIA Container Toolkit)の設定は別途必要となる。 Linuxで最初にやっておくべき設定 Amazon EC2やGoogle Compute …
続きを読む
2種類のBigQueryエクスポート GA4のBigQueryエクスポートデータには以下の2種類がある。 イベントデータ ユーザーデータ ユーザーデータは1行1人で、user_pseudo_id単位で集約したデータと、user_id単位で集約したデータのそれぞれのテーブルが生成される。 所属するオーディエンスの情報やユーザ(user_pseudo_id / user_id)単位の通算指標が含まれる。 分析によく使うのがイベントデータで、1行1イベントでイベントパラメータなどがネストされて含まれている。 エクスポートの頻度 イベントデータの出力頻度は以下の3種類がある。 ストリーミング=リアルタイム。重複や使えない列あり(トラフィック …
続きを読む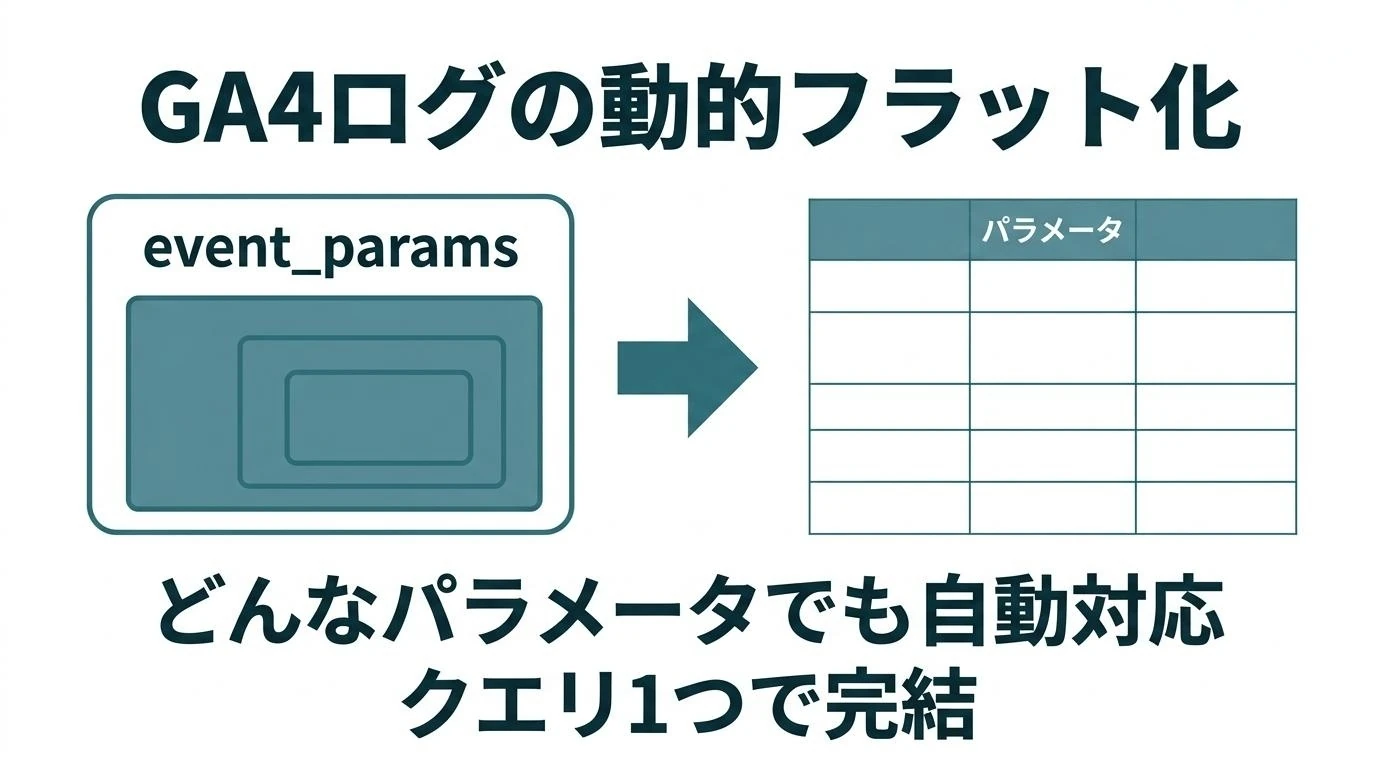
GA4(Firebase)のログを扱う際、ネストされているイベントパラメータやユーザープロパティをフラット化しないと使いにくい。ところが格納されているパラメータやプロパティは決まっているわけではないため、通常はそれをハードコーディングで指定することが多い。つまり使用しているパラメータやプロパティに応じてその都度クエリを手動作成することになる。 しかしそれでは面倒なので、どんなイベントパラメータやユーザープロパティを使っていても、それがどんな型であっても、オールマイティにフラット化するクエリを作る。存在するパラメータやプロパティに基づいて動的にクエリを作って実行する。このクエリひとつあればどんなケースにも対応できる、汎用的なものである …
続きを読む
- GCPのIAMポリシー(権限設定) GCPにおける階層と言葉の定義 組織 (フォルダ) プロジェクト 各種リソース Cloud Storage BigQuery Compute Engine
- プロジェクトとリソースを中心に考える。 フォルダや組織はプロジェクトを便宜的に束ねるもの。フォルダや組織は設定しなくてもいい →後述するが、組織/プロジェクト/リソース単位で権限設定ができる アカウント アカウントには2種類 ユーザーアカウント Googleのログイン画面からログインできるアカウント 人間ユーザ。異動や退職とともにアカウントがなくなるケースも想定する必要がある 一部のGoogleアカウントではアカウント単位のコストが発生する …
続きを読む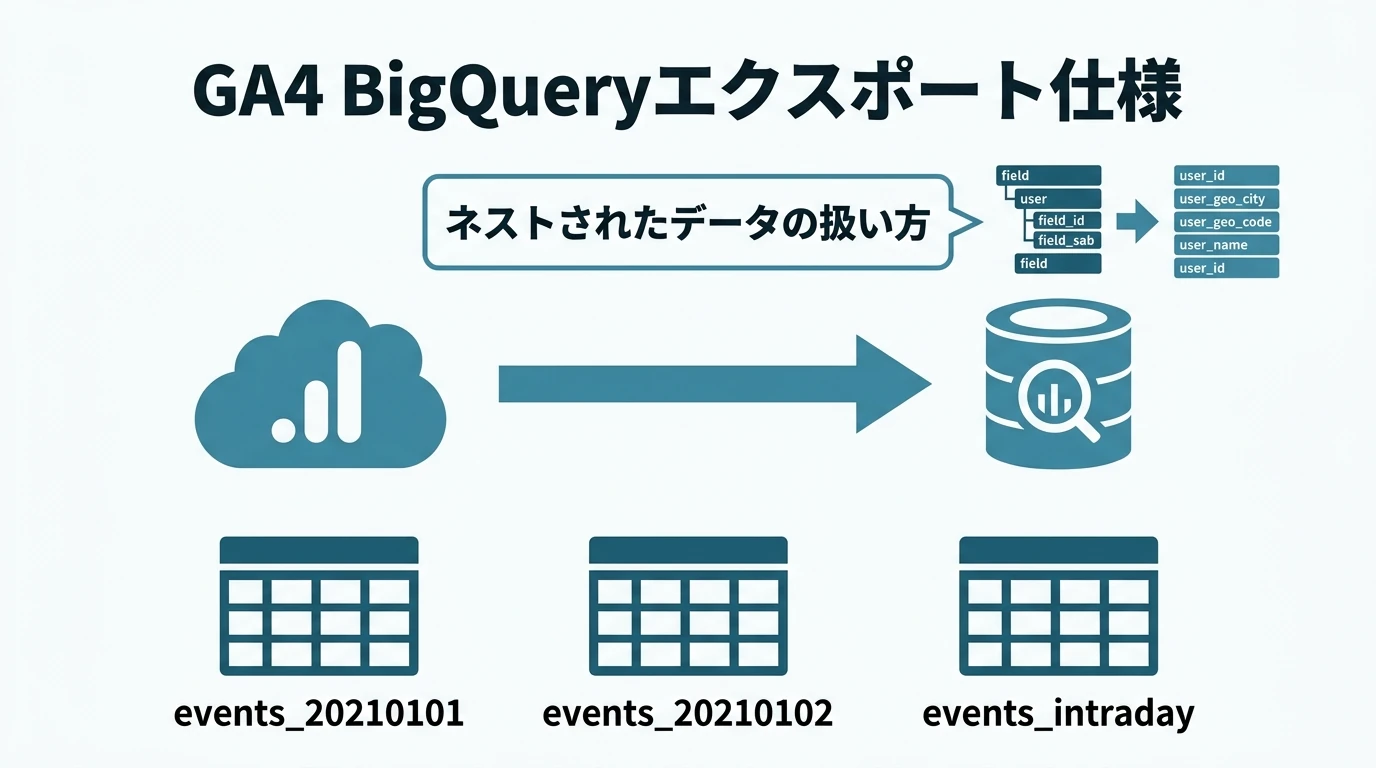
GA4のBigQueryエクスポートの仕様とデータの扱い方を説明する。GA4のログはネストされたレコードなど特殊な形式になっており、そのままでは扱いにくいのでいくつかテクニックがある。 BigQueryへのエクスポート設定 GA4の管理画面で設定するが、手順はこちらの記事を参照。 https://www.marketechlabo.com/ga-app-web-property-to-bigquery/ テーブルの場所 プロジェクト:GA4のBigQueryエクスポート設定で指定したプロジェクト データセット「analytics_999999999」(「999999999」の部分はプロパティID) テーブル名 前日までのデータ(日付 …
続きを読む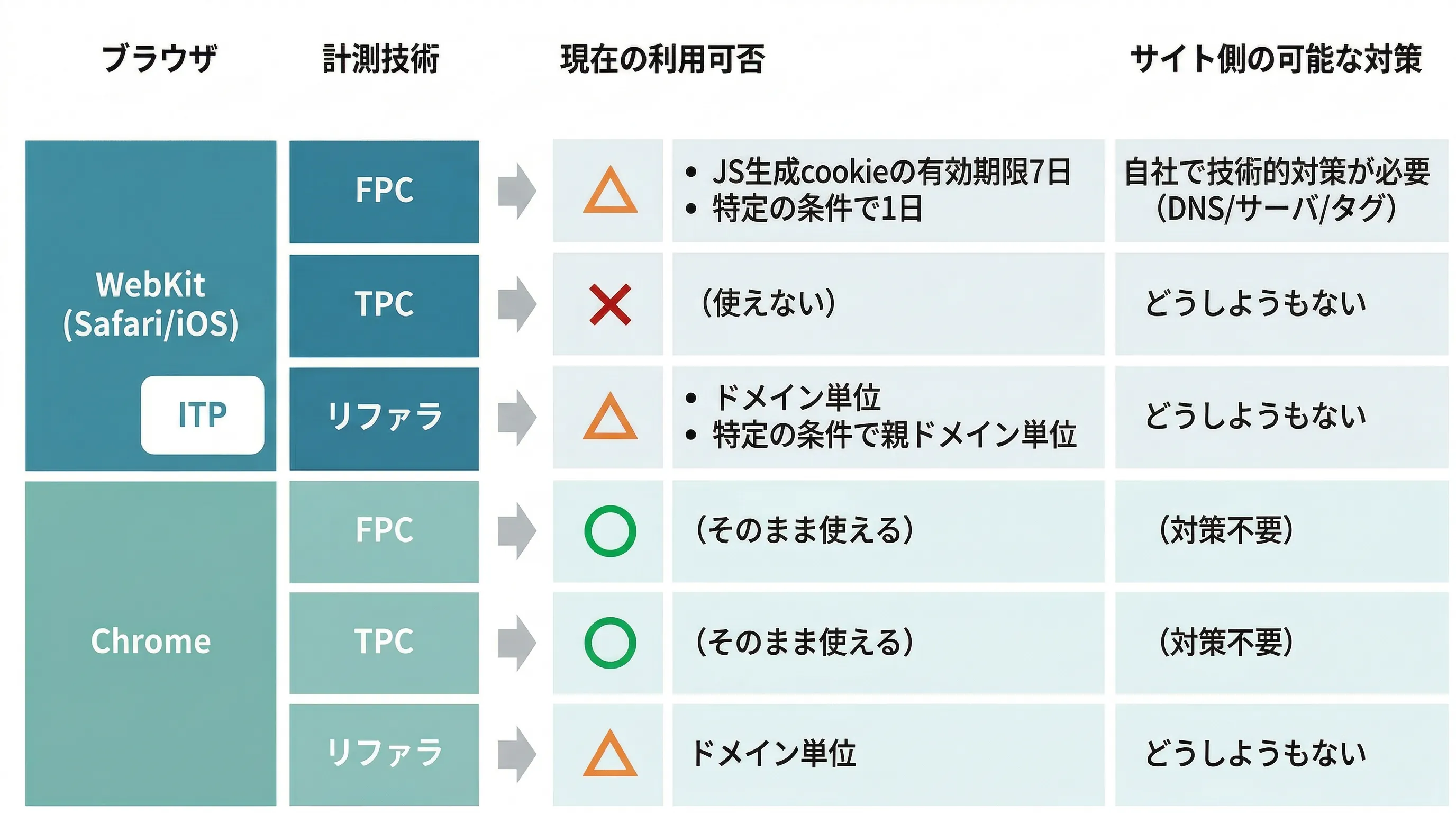
Googleは現時点では廃止自体を諦めたものの、個人のプライバシー尊重の観点からサードパーティcookieを廃止する動きを進めていた。AppleのiOSやSafariではすでにITPによってサードパーティcookieはデフォルトで使えなくなっている。 そんな中サードパーティcookieに代替する技術としてさまざまな技術をGoogle自身も開発し、他のベンダもそういった技術を開発してきた。その結果さまざまな自称「ポストcookie」「cookieレス」ソリューションが出てきているのだが、それらはどれも完全にサードパーティcookieを代替するわけではなく、これまでサードパーティcookieが担ってきた役割を部分的に違う方法で実現しよう …
続きを読む
Firebase公開データでユーザー継続予測を行う手順(BigQuery + BQML) Firebase Analyticsの公開データを使用して、ユーザーの1か月後継続を予測するための一連の分析手順である。生ログのフラット化から機械学習モデルの構築まで、BigQueryとBQMLだけで完結する手法を示す。 使うデータセット Firebaseのパブリックデータがfirebase-public-project.analytics_153293282.events_*にあるのでこれを使う。 20180612~20181003の114日分のデータ 基本集計(EDA) データの全体像を把握するため、まずイベントの発生傾向を確認する。どのよ …
続きを読む
本ブログではたびたび静的ウェブ配信について説明してきたが、 GCP静的ウェブ配信、Firebase Hostingとあわせて、個人で静的配信するなら決定版といえる方法を紹介する。 Netlifyとは WordPressで静的サイトを生成し、Netlifyで公開する。Netlifyは 静的サイトのホスティング AWS Lambdaのような関数 フォーム などができる、サーバレスで何らかのサービスを配信するためのプラットフォームである。個人用途であれば大部分の機能を無料で使える(複数ユーザ、Basic認証などは有料)。 端的に言うと静的サイトの配信を無料でできるサービスである。リダイレクトや転送/リバースプロキシも可能でリスト形式で設定 …
続きを読む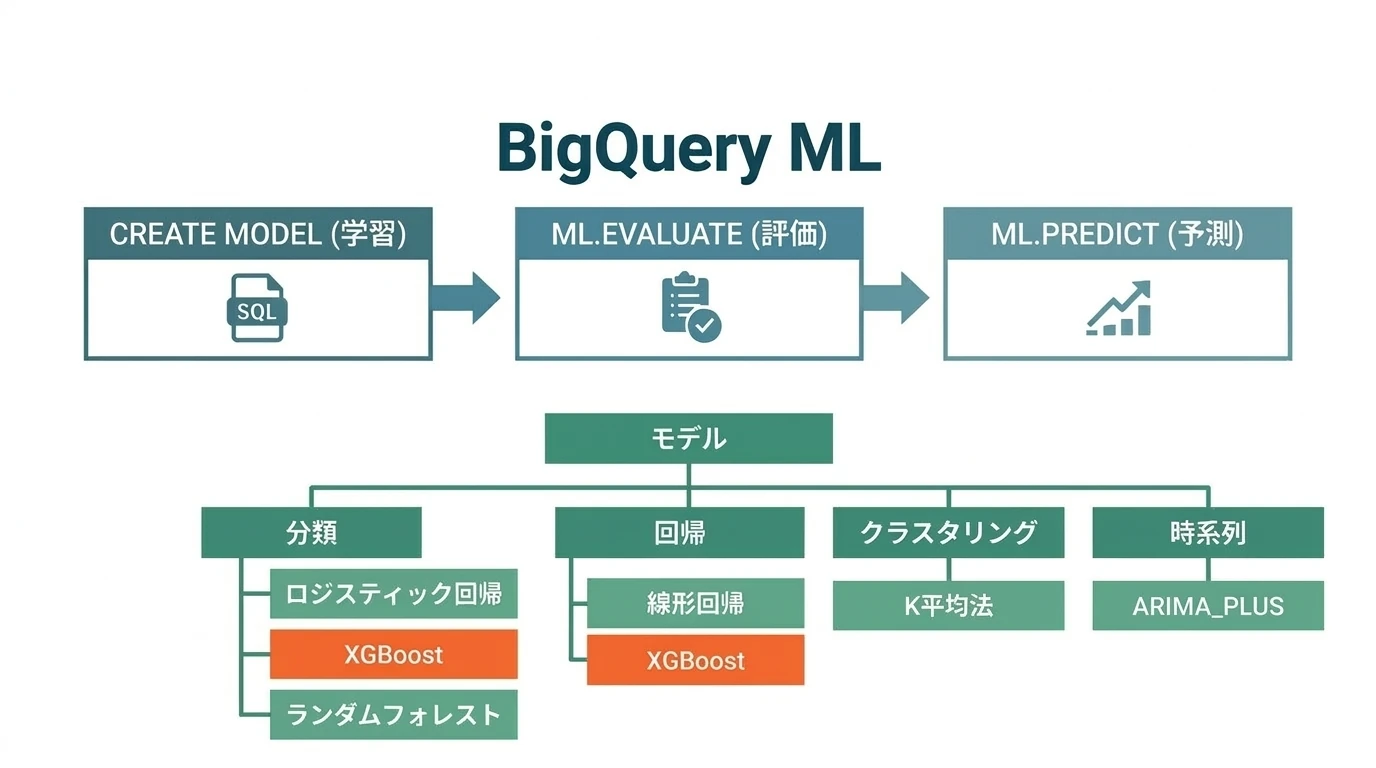
BigQuery MLは生成AI(Geminiなど)との連携やVertex AI統合など多様な機能を提供しているが、企業の日常業務で扱う構造化データ(売上、顧客、在庫など)の予測分析において、最もコストパフォーマンスが高く実用的な手法は依然として勾配ブースティング木(XGBoost系)である。この記事では、SQLだけで完結するMLパイプラインの構築方法を実例とともに解説する。 BigQuery ML(BQML)では以下のモデルが使える: 線形回帰 - 類似のリモートデータでトレーニングされたモデルを使用して、新しいデータの数値指標の値を予測する。ラベルは実数で、正の無限大、負の無限大、NaN(非数値)にはできない。 ロジスティック回 …
続きを読む