BigQueryはビッグデータを扱える高速安価なデータウェアハウスとして知られているが、
あまりに高速であるためにDWH(つまりデータベース)としての使い方にとどまらず、
さまざまな数学的な計算処理に使われることがある。
一般的に数学的な処理をする場合、普通はBigQueryでは基本的な集計までにとどめ、
あとはPythonやRなどの言語からBigQueryのデータを読み込んで計算処理をすることが多い。
Rなどは計算処理専門の言語なので、BigQueryより関数も充実している。
しかしBigQueryだけでそういった処理を完結できるならそれは望ましい。
プログラミング言語を使おうとすると、それを動かすインスタンスが必要になったり準備や管理が大変になる。
ということで、本来のBigQueryの使い方ではないのだが、世の中には数学的な計算処理をBigQueryで実現する一案を紹介する。
目次
BigQueryでcos類似度を計算する
cos類似度とは
2つのベクトル間の類似度を表すもの。アイテムがそれぞれ特徴量のベクトルを持っていると考えると、アイテム間の類似度を表すことができる。cos類似度の計算式は
$$ cos( \vec{a}, \vec{b} ) = \frac{\vec{a} \cdot \vec{b}}{|\vec{a}| \cdot |\vec{b}|} = \frac{\sum_{i=1}^n a_i b_i}{\sqrt{\sum_{i=1}^n a_i^2} \sqrt{\sum_{i=1}^n b_i^2}}$$
レコメンドの古典的な手法である協調フィルタリングに使われることがある。つまりBigQueryだけでレコメンドすべきアイテムを抽出できるということになる。
元データの形式
類似度を計算する対象のアイテムのデータの形式
- 行がアイテム
- 列がアイテムのIDと特徴量
- アイテム間の類似度を算出する
- 汎用化するため、列(特徴量)は決まっていない。ただし数が多い
というケースを想定
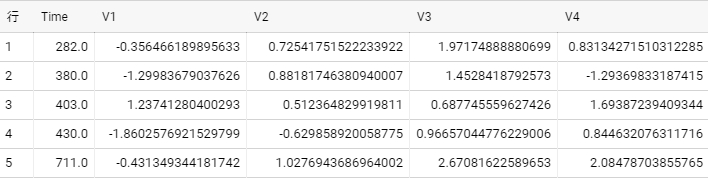
今回使うデータ
BigQueryのパブリックデータの
bigquery-public-data:ml_datasets.ulb_fraud_detection
を使う。1行1取引で、取引ごとの特徴量(V1–V28)とそれが詐欺かどうか(Class)を表す。Timeがトランザクションのタイムスタンプ。
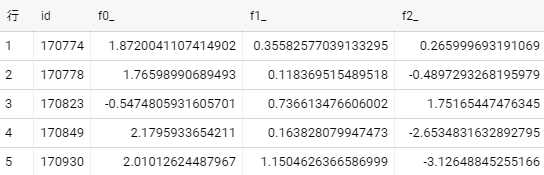
行(取引)のIDを付加した別テーブルを用意する。
create or replace table `my-project.test_dataset.ulb_fraud_detection` as
select row_number() over() id, * from `bigquery-public-data.ml_datasets.ulb_fraud_detection`;
流れ
列が可変ということで、SQLではないプログラム的な処理が必要になる。そこでBigQuery Scriptingを使う。
- 必要なデータを抽出
- 各行の特徴量をベクトル(ARRAY)化する
- 下三角行列に対応するIDの組み合わせテーブルを作る
- 類似度を計算して値を入れる
アウトプットの形式は行列そのものではなく、各IDの組み合わせに対する類似度
計算方法は
https://stackoverflow.com/questions/53953848/calculating-pairwise-cosine-similarity-between-quite-a-large-number-of-vectors-i
のとおりで、まず1~2で特徴量をベクトル化したデータ
with id_vectors as(
...
)
の部分を作成する。
特徴量の列名を抽出する
データのテーブルから類似度の計算に使う列の一覧を抽出する。列が可変なので動的に抽出するのだが、列情報がINFORMATION_SCHEMAにあるのでそれを使う。型で絞り込むこともできるし名前で絞り込むこともできる。
select
column_name
from
`my-project.test_dataset.INFORMATION_SCHEMA.COLUMNS`
where
table_name = 'ulb_fraud_detection' -- 対象のテーブル名
and data_type in ('INT64', 'FLOAT64') -- 型で絞り込み
and column_name like 'V%' -- 名前で絞り込み
order by ordinal_position;
ここで取得した列の値を取得する
各列の値を取得する
動的クエリの使い方
上で取得した列一覧に対してSELECTを行うのだが、format()でクエリ文を生成し、BigQuery Scriptingのexecute immediateで動的実行する。
declare str_columns string; -- 変数を宣言
set str_columns = 'x,y,z'; -- 変数に代入
execute immediate format("""
select id, %s from `prj.dataset.table_name`
""", str_columns);
これにより
select id, x,y,z from `prj.dataset.table_name`
というクエリが生成され、実行される。
%sの部分にstr_columnsの文字列を代入できる。str_columnsには’列1, 列2, …’という文字列を入れることになる。
クエリの動的部分の生成
string_agg()で複数行の結果を一つの文字列として結合できるので、select %sの%sの部分の文字列を先の列名一覧から生成する。set str_columns = (クエリ)でクエリの結果を変数に代入できる。
declare str_columns string;
set str_columns = (select
string_agg('safe_cast(' || column_name || ' as float64)' order by ordinal_position)
from `my-project.test_dataset.INFORMATION_SCHEMA.COLUMNS` where table_name = 'ulb_fraud_detection' and data_type in ('INT64', 'FLOAT64') and column_name like 'V%'
);
生成されたstr_columnsという文字列は
safe_cast(V1 as float64),safe_cast(V2 as float64),safe_cast(V3 as float64),safe_cast(V4 as float64),safe_cast(V5 as float64),safe_cast(V6 as float64),safe_cast(V7 as float64),safe_cast(V8 as float64),safe_cast(V9 as float64),safe_cast(V10 as float64),safe_cast(V11 as float64),safe_cast(V12 as float64),safe_cast(V13 as float64),safe_cast(V14 as float64),safe_cast(V15 as float64),safe_cast(V16 as float64),safe_cast(V17 as float64),safe_cast(V18 as float64),safe_cast(V19 as float64),safe_cast(V20 as float64),safe_cast(V21 as float64),safe_cast(V22 as float64),safe_cast(V23 as float64),safe_cast(V24 as float64),safe_cast(V25 as float64),safe_cast(V26 as float64),safe_cast(V27 as float64),safe_cast(V28 as float64)
これを%sに代入する。
特徴量をベクトル化する
cos類似度の計算にあたり、特徴量をベクトル化する。
フラットなクエリでは
execute immediate format("""
select id, %s from `my-project.test_dataset.ulb_fraud_detection`
""", str_columns);
の形式だが、特徴量をベクトル化するとは
execute immediate format("""
select id, [%s] from `my-project.test_dataset.ulb_fraud_detection`
""", str_columns);
のように特徴量をまとめて一つの列にし、ARRAYとして扱う。
計算
3~4の実際にcos類似度を計算する
方法1:cos類似度の計算式をそのまま使う
declare str_columns string;
set str_columns = (select
string_agg('safe_cast(' || column_name || ' as float64)' order by ordinal_position)
from `my-project.test_dataset.INFORMATION_SCHEMA.COLUMNS` where table_name = 'ulb_fraud_detection' and data_type in ('INT64', 'FLOAT64') and column_name like 'V%'
);
execute immediate format("""
create or replace table `my-project.test_dataset.cos_sim_1` as
with id_vectors as(
select id, [%s] coords from `my-project.test_dataset.ulb_fraud_detection`
), pairwise as (
select t1.id id_1, t2.id id_2
from id_vectors t1
inner join id_vectors t2
on t1.id < t2.id
), similarity as (
select id_1, id_2, (
select
safe_divide(sum(value1 * value2), sqrt(sum(value1 * value1)) * sqrt(sum(value2 * value2)))
from unnest(a.coords) value1 with offset pos1
join unnest(b.coords) value2 with offset pos2
on pos1 = pos2
) cosine_similarity
from pairwise
join id_vectors a on a.id = id_1
join id_vectors b on b.id = id_2
)
select * from similarity
order by 1,2;
""", str_columns);
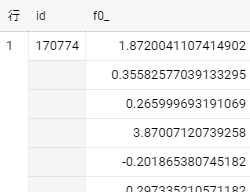
結果が
ポイント
cos類似度を計算するとき、
- 大きい数の掛け算なのでint64だと桁あふれエラー(オーバーフロー)になる。そこで事前にfloat64型にしておく。
- 一方のアイテムのノルムが0の場合分母が0になる。そのまま割るとエラーになるので、それを防ぐ(分母が0の場合はNULLにする)ために
safe_divide()を使う。
id_vectorsの部分で事前に...の部分を計算しておくと処理が軽くなるということで、その方法を次で紹介する。
方法2:事前にノルムを計算する
id_vectorsを作る段階でIDごとのノルムを計算する式を動的に生成し、%sに代入する。id_vectorsの段階でノルムが入った状態にする。
declare str_norm string;
set str_norm = (select
'sqrt(sum(square(' || string_agg(column_name, ') + square(') || ')) over(partition by id))'
from `my-project.test_dataset.INFORMATION_SCHEMA.COLUMNS` where table_name = 'ulb_fraud_detection' and data_type in ('INT64', 'FLOAT64') and column_name like 'V%'
);
生成されるstr_normは
sqrt(sum(square(V1) + square(V2) + square(V3) + square(V4) + square(V5) + square(V6) + square(V7) + square(V8) + square(V9) + square(V10) + square(V11) + square(V12) + square(V13) + square(V14) + square(V15) + square(V16) + square(V17) + square(V18) + square(V19) + square(V20) + square(V21) + square(V22) + square(V23) + square(V24) + square(V25) + square(V26) + square(V27) + square(V28)) over(partition by id))
なおsquare()は2乗を計算するUDF。記述量を減らすためにUDF化している。
これを使って
declare str_columns string;
declare str_norm string;
create temp function square(x any type) as (
safe_cast(x as float64) * safe_cast(x as float64)
);
set str_columns = (select
string_agg(column_name)
from `my-project.test_dataset.INFORMATION_SCHEMA.COLUMNS` where table_name = 'ulb_fraud_detection' and data_type in ('INT64', 'FLOAT64') and column_name like 'V%'
);
set str_norm = (select
'sqrt(sum(square(' || string_agg(column_name, ') + square(') || ')) over(partition by id))'
from `my-project.test_dataset.INFORMATION_SCHEMA.COLUMNS` where table_name = 'ulb_fraud_detection' and data_type in ('INT64', 'FLOAT64') and column_name like 'V%'
);
execute immediate format("""
create or replace table `my-project.test_dataset.cos_sim_2` as
with id_vectors as(
select id, [%s] coords, %s norm from `my-project.test_dataset.ulb_fraud_detection`
), pairwise as (
select t1.id id_1, t2.id id_2
from id_vectors t1
inner join id_vectors t2
on t1.id < t2.id
), similarity as (
select id_1, id_2, (
select
safe_divide(sum(value1 * value2), a.norm * b.norm)
from unnest(a.coords) value1 with offset pos1
join unnest(b.coords) value2 with offset pos2 on pos1 = pos2
) cosine_similarity
from pairwise
join id_vectors a on a.id = id_1
join id_vectors b on b.id = id_2
)
select * from similarity
order by 1,2;
""", str_columns, str_norm);
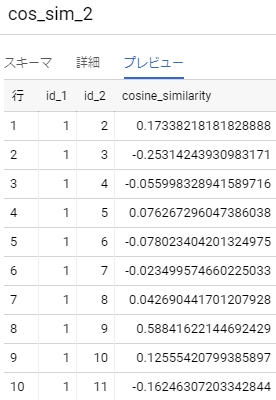
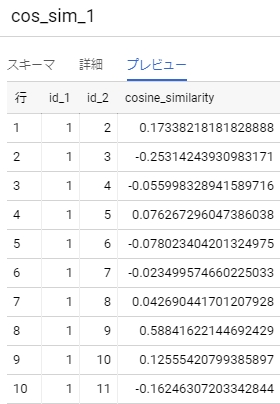
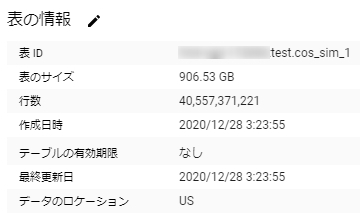
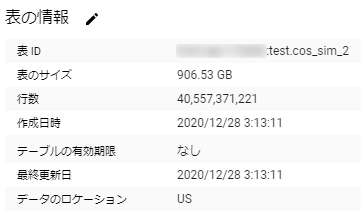
結果は方法1と方法2とで同じで、
方法1
方法2

速度を比較すると
方法1
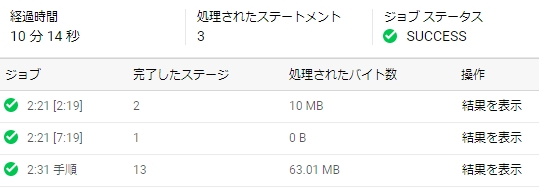
方法2
方法2のほうがやや高速になった
BigQueryのコスト
cos類似度を計算すること自体については以上のようにしか60MB程度しかメモリを使わない。課金額にしたらほぼ無料である。しかし出来上がったデータを見ると
なんと400億行900GBのデータである。たしかに28万行×28万行の下三角行列と考えればそれだけの行数になる。
この類似度テーブルに基づいて類似度の高いアイテムを抽出しようとするとこのテーブル全体に対してクエリをかける必要がある。
その都度900GB分のクエリ課金が発生することになる。クエリ毎回5ドル近いコストがかかるということで、これはやばい。
レコメンドをBigQueryで完結させる名案ではあるのだが、コストも考慮して使うかどうかを判断したほうがいい。RやPythonで疎行列として扱うのが適していると判断されることも大いにある(このケースで疎行列としてのは難しいが)。
データ分析 の記事一覧




