Rのおすすめパッケージをアップデートしてまとめた。定番の分析手法をはじめ、可視化やデータ処理に便利なものなど、幅広く紹介した。中にはマストというものもあるし、意外と知られていないがインストールしておくと便利なものまで、使い方の例も挙げて説明している。
目次
ミドルウェア的なレイヤーのライブラリ(must)
curl
ファイルをwebからダウンロードするときに使う。
データファイルやパッケージのダウンロードが発生する処理で内部的に使われるライブラリで、他のパッケージのインストールの際に同時にインストールされることが多く、意識されることは少ないパッケージ。たまに依存関係の問題でも解決されずに未インストールの場合があるので、明示的にインストールする必要がある。
read.csv('https://...')
などのために必要。
devtools
GitHubからのインストールなど。ほとんどがGitHubからのインストールで使う
ほとんどがこの使い方
devtools::install_github('アカウント名/リポジトリ名')
doParallel
簡単な並列処理のためのラッパー。並列処理にはこのライブラリの関数群を使っておけばいい。
使い方の例
registerDoParallel(detectCores()-1)
foreach(
i = 1:nrow(tune_params),
.verbose = T, .multicombine = T, .packages='data.table'
) %dopar% {
output <- some_function(tune_params[i,alpha])
fwrite(cbind(i=i, output), file='out.csv', append=T)
}
基本的なデータ処理
data.table
データフレームの高速化
reshape2
縦横変換(melt()とdcast())
横→縦
USArrests$state <- rownames(USArrests)
melt(data=USArrests, id.vars='state', measure.vars=c('Murder', 'Assault', 'Rape'))
state variable value
Alabama Murder 13.2
Alaska Murder 10.0
Arizona Murder 8.1
Arkansas Murder 8.8
縦→横
dcast(data=CO2, formula=Type + Treatment + conc ~ Plant, fill=NA, value.var='uptake')
# 集計(ピボット)もできる
dcast(data=CO2, Type ~ Plant, fun.aggregate = sum, value.var='uptake')
Type Qn1 Qn2 Qn3 Qc1 Qc3 Qc2 Mn3 Mn2 Mn1 Mc2 Mc3 Mc1
Quebec 232.6 246.1 263.3 209.8 228.1 228.9 0.0 0.0 0.0 0 0.0 0
Mississippi 0.0 0.0 0.0 0.0 0.0 0.0 168.8 191.4 184.8 85 121.1 126
dplyr
データ加工を直感的かつ簡単に行う関数群。パイプを使って処理を連結しながら全体の処理を書く
tidyr
縦横変換(gather()とspread())。dplyrのパイプの中で使う
横→縦
USArrests %>% rownames_to_column %>% gather(key=type, value=occurrence, c(Murder, Assault, Rape))
rowname UrbanPop type occurrence
Alabama 58 Murder 13.2
Alaska 48 Murder 10.0
Arizona 80 Murder 8.1
Arkansas 50 Murder 8.8
:
縦→横
CO2 %>% data.frame %>% spread(key=Plant, value=uptake)
Type Treatment conc Qn1 Qn2 Qn3 Qc1 Qc3 Qc2 Mn3 Mn2 Mn1 Mc2 Mc3 Mc1
Quebec nonchilled 95 16.0 13.6 16.2 NA NA NA NA NA NA NA NA NA
Quebec nonchilled 175 30.4 27.3 32.4 NA NA NA NA NA NA NA NA NA
Quebec nonchilled 250 34.8 37.1 40.3 NA NA NA NA NA NA NA NA NA
Quebec nonchilled 350 37.2 41.8 42.1 NA NA NA NA NA NA NA NA NA
:
stringr
文字列操作の便利な関数群
factorとcharacterを同様に扱える
結合
x <- 2
str_c('Started ', x, 'days ago', sep='')
'Started 2days ago'
ベクトルの結合
str_c(month.name, collapse=', ')
'January,February,March,April,May,June,July,August,September,October,November,December'
正規表現一致
str_detect(month.name, 'er$')
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
TRUE
TRUE
TRUE
TRUE
正規表現抽出
全体
str_extract(month.name, '^[A-z]{3}')
'Jan'
'Feb'
'Mar'
'Apr'
'May'
'Jun'
'Jul'
'Aug'
'Sep'
'Oct'
'Nov'
'Dec'
後方参照
str_match(month.name, '^[A-z]{3}([A-z]{3})')
Januar uar
Februa rua
NA NA
NA NA
NA NA
NA NA
NA NA
August ust
Septem tem
Octobe obe
Novemb emb
Decemb emb
全体が1列目、1番目のマッチが2列目、…
正規表現置換
str_replace(month.name, 'r', 'R')
'JanuaRy'
'FebRuary'
'MaRch'
'ApRil'
'May'
'June'
'July'
'August'
'SeptembeR'
'OctobeR'
'NovembeR'
'DecembeR'
小文字に
str_to_lower(month.name)
'january'
'february'
'march'
'april'
'may'
'june'
'july'
'august'
'september'
'october'
'november'
'december'
大文字に
str_to_upper(month.name)
'JANUARY'
'FEBRUARY'
'MARCH'
'APRIL'
'MAY'
'JUNE'
'JULY'
'AUGUST'
'SEPTEMBER'
'OCTOBER'
'NOVEMBER'
'DECEMBER'
前後のトリム
str_trim(' Hello, hello. ', side="both")
'Hello, hello.'
ggplot2
言わずと知れたリッチな可視化
Matrix
疎行列(初期インストール済み)
qlcMatrix
疎行列の便利なメソッド
bit64
integerを64bitに拡張。大きな整数を扱う際には必須
データ読み込み
bigrquery
変数加工
proxy
さまざまな種類の距離・類似度を算出する関数群。クラスター分析で必須。
mice
さまざまな方法での欠損値補完をする関数群
moment
任意の次数のモーメント統計量を算出
greybox
細かい便利な関数群(mcor(): カテゴリ変数と数値型変数の相関係数を一発で出せるなど)
FeatureHashing
Feature Hashing
libFMexe
Factorization Machines
CRANにないのでインストールは
devtools::install_github('andland/libFMexe')
手法
これらは代表的な手法で、それぞれ手法を実施するのに必要。同じ手法で類似のパッケージもある中、使いやすいものを紹介している。
一般化線形モデルとその拡張
- glmnet: GLMで正則化回帰
- MASS: 主にglm.nbで使う(初期インストール済み)
- pscl: ゼロ切断/過剰モデル
- AER: dispersiontest
- mlogit: 多項ロジット
- mgcv: GAM(初期インストール済み)
- glmmML: 一般化線形混合分布モデル
- pls: PLS回帰
イベントヒストリー分析
- survival: イベントヒストリー分析の基本(初期インストール済み)
- ggfortify: survfitの可視化(ggplot)
- muhaz: イベントデータからhazardを推定する
- survrec: 繰り返しイベントヒストリー分析。終了したのでアーカイブからインストールする
install.packages('https://cran.r-project.org/src/contrib/Archive/survrec/survrec_1.2-2.tar.gz')
時系列
- xts: 時系列のデータ形式
- forecast: 時系列
- bsts: 状態空間モデル。使いやすい
- CausalImpact: キャンペーン効果の推定などに使う
- TSstudio: bstsにも対応した時系列分析を簡単にやりやすくしてくれるパッケージ
ツリーモデル
- rpart: 決定木(初期インストール済み)
- rpart.plot: rpartの可視化
- ranger: ランダムフォレスト
- xgboost: XGBoost
アソシエーションルール
- arules: アソシエーションルール
- arulesViz: arulesの可視化(いろいろ余計なものをインストールする)
- recommenderlab: アソシエーションルール
テキストマイニング
- tm: テキスト処理
- SnowballC: テキスト処理
- text2vec: テキストマイニング
その他
- e1071: fuzzy c-means
- kernlab: SVM
- nnet: Neural network(初期インストール済み)
モデルの評価
上記の手法に比べてパッケージが新しくマイナーなものが多い。
MLmetrics
AUCやGini係数など、意外とデフォルトで実装されておらず定義が必要な指標も計算できる
bounceR
変数選択
CRANにないのでインストールは
devtools::install_github('STATWORX/bounceR')
モデルの解釈
DALEX
機械学習手法で変数の重要度を知る。汎用的に使えそう
iml
汎用的。Shapley valueも出せる。
pdp
数多くのモデルに対応した部分従属プロットを描く。edarfより多数のモデルに対応している
ShapleyR
Shapley valueを算出。mlrオブジェクトにのみ対応
CRANにないのでインストールは
devtools::install_github('redichh/ShapleyR')
inTrees
ランダムフォレスト系のアルゴリズムで重要なルールを抽出。xgboostにも対応
lares
機械学習のいい感じオールインワンプロット
CRANにないのでインストールは
install.packages(c('fracdiff', 'uroot'))
devtools::install_github('laresbernardo/lares', dependencies=T)
lares::mplot_full(tag = label, score = predicted, splits = 8, subtitle = NA, model_name = NA, save = FALSE, file_name = "viz_full.png", subdir = NA)
GUI/可視化
Deducer
GUI
GrapheR
GUIでグラフ作成(レガシープロット)
使い方
require(GrapheR)
run.GrapheR()
レガシーな画面ではあるが、GUIでチャートの種類やパラメータを指定できる。
「DRAW」をクリックするとこのようなチャートが現れる。
esquisse
ggplot2をGUIで操作。
数あるggplotをGUIで操作することを試みたパッケージの中で、必要なすべての機能を持った完成版のパッケージと言っていいだろう。BIツールのチャート生成画面のようなわかりやすいUIである。
ggplot2のコードはすぐ忘れてしまうため大変ありがたく、これ一つインストールしておけばggplot2はOK。使い方は以下の通り
# install.packages()でなければ
devtools::install_github("dreamRs/esquisse")
esquisse::esquisser(iris)
こんな画面で変数をドラッグすると
件数の形式に合わせたチャートが表示される(この例では連続量なのでヒストグラム)
XY軸で変数を掛け合わせると
散布図になる
GUIでドットを大きくすることもできる
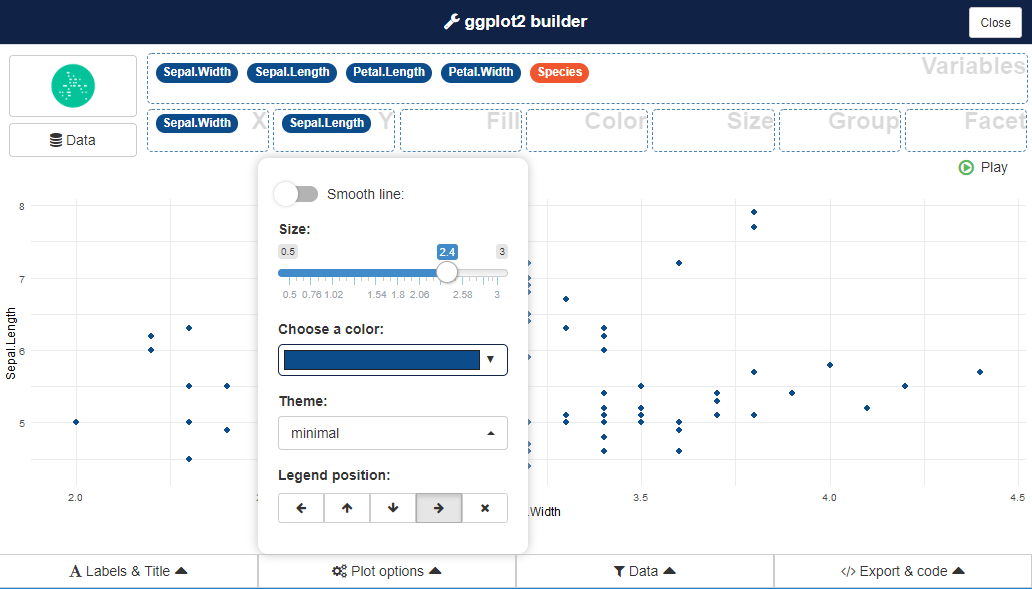
Colorに因子型変数をドラッグすると色分けできる
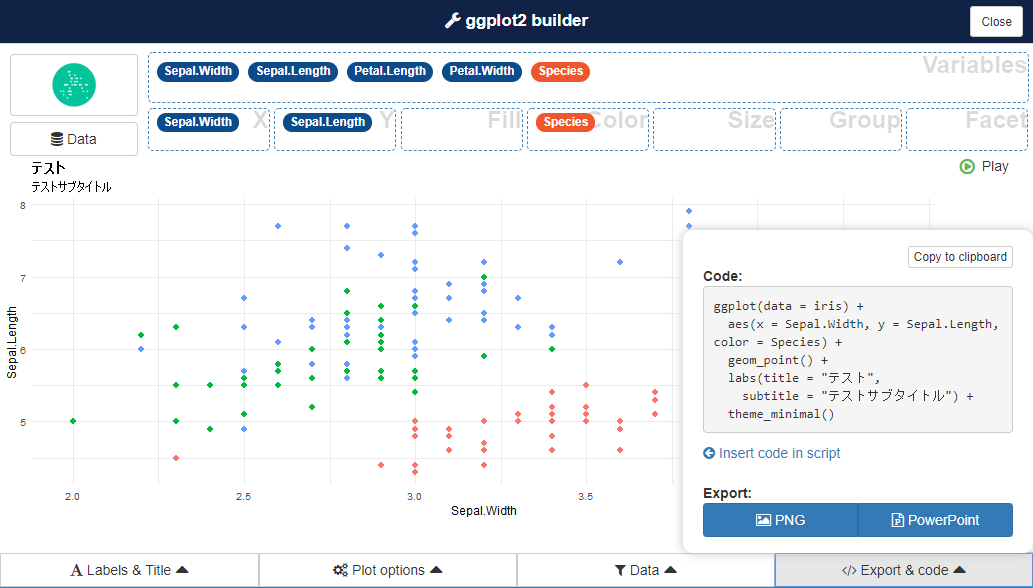
チャートを生成するコードも出力できる
- plotly: JSのチャートを出力。ggplot2のプロットオブジェクトからも直接生成できる
楽にデータ操作するパッケージ
rpivotTable
データフレームをPivotTable.jsに出力。HTML+JSのピボットテーブルに出力できるので納品時などに大変便利。
rpivotTable::rpivotTable(iris)
DataExplorer
データ確認用のプロットをHTMLに一括出力
DataExplorer::create_report(iris)
skimr
データ確認をCUIで行う
https://cran.r-project.org/web/packages/skimr/vignettes/Using_skimr.html
XLConnect
データの編集を直接Excelで行う
詳細はデータをExcel上で編集するを参照。
openxlsx
xlsxファイル入出力
詳細はRとExcel(ファイルの読み書き)を参照。
officer
MS PowerPointやWordのファイル出力
https://cran.r-project.org/web/packages/officer/vignettes/powerpoint.html
使い方の例
require(officer)
read_pptx('template.pptx') %>%
add_slide(layout="Title and Content", master = "Office Theme") %>%
ph_with_text(type = "title", str='') %>%
ph_add_text(type = "title", str = 'モデル1\n', style = fp_text(font.size = 20)) %>%
ph_add_text(type = "title", str = '説明文説明文説明文', style = fp_text(font.size = 16)) %>%
ph_with_vg_at(code={plot(predicted_model1); abline(h=0)}, height=6, width=8, top=1, left=1.4) %>%
add_slide(layout="Title and Content", master = "Office Theme") %>%
ph_with_text(type = "title", str='') %>%
ph_add_text(type = "title", str = 'モデル2\n', style = fp_text(font.size = 20)) %>%
ph_add_text(type = "title", str = '説明文説明文説明文', style = fp_text(font.size = 16)) %>%
ph_with_vg_at(code={plot(predicted_model2); abline(h=0)}, height=6, width=8, top=1, left=1.4) -> ppt
print(ppt, target = "model_performances.pptx")
mlr
機械学習の手続きを簡略化・統一化。caretと同じだが機能が豊富そう。何よりもshinyを使ったGUIラッパーがあるのが便利。
shinyMlr
mlrのshinyラッパー
# install.packages()でなければ
devtools::install_github("mlr-org/shinyMlr")
shinyMlr::runShinyMlr()
パッケージインストール時の便利なオプション
CRANのレポジトリのURLを指定
CRANのレポジトリのURLを指定する。MS R Openではデフォルトであらかじめ設定された日付のレポジトリのスナップショットからしか取得できないので、最新のパッケージをインストールできない。それをこの方法で回避する。
options(repos = c(CRAN = "https://mran.revolutionanalytics.com/snapshot/YYYY-MM-DD"))
これをinstall.packages()の前に実行しておく。
インストールされていない場合にのみインストール
パッケージがインストールされていない場合にのみインストールする。
スクリプトを汎用的に使いたい場合などはこのように記述しておくといい。
if (!require("devtools")){install.packages("devtools")}
依存関係でインストールするパッケージを拡張
必須ではないが推奨の依存パッケージをインストールする。install.packages()はデフォルトでは基本的に必須の依存パッケージしかインストールしないが、この方法ではそれを拡張する。
caretやmlrなどの汎用的な機械学習ライブラリのインストール時には、その機械学習ライブラリが対応しているすべてのアルゴリズムのパッケージをインストールするので便利なことがある。
install.packages("mlr", dependencies = c("Depends", "Suggests"))
コンパイル時に使用するコア数を指定
コンパイル時に使用するコア数を指定する。make -j4と同じ。
install.packages("xgboost", Ncpus = getOption("Ncpus", 4L))
データの加工や分析で使うRの使い方 の記事一覧




