
Rでローデータの読み込み(データフレーム、data.table、webデータの取得)
概要
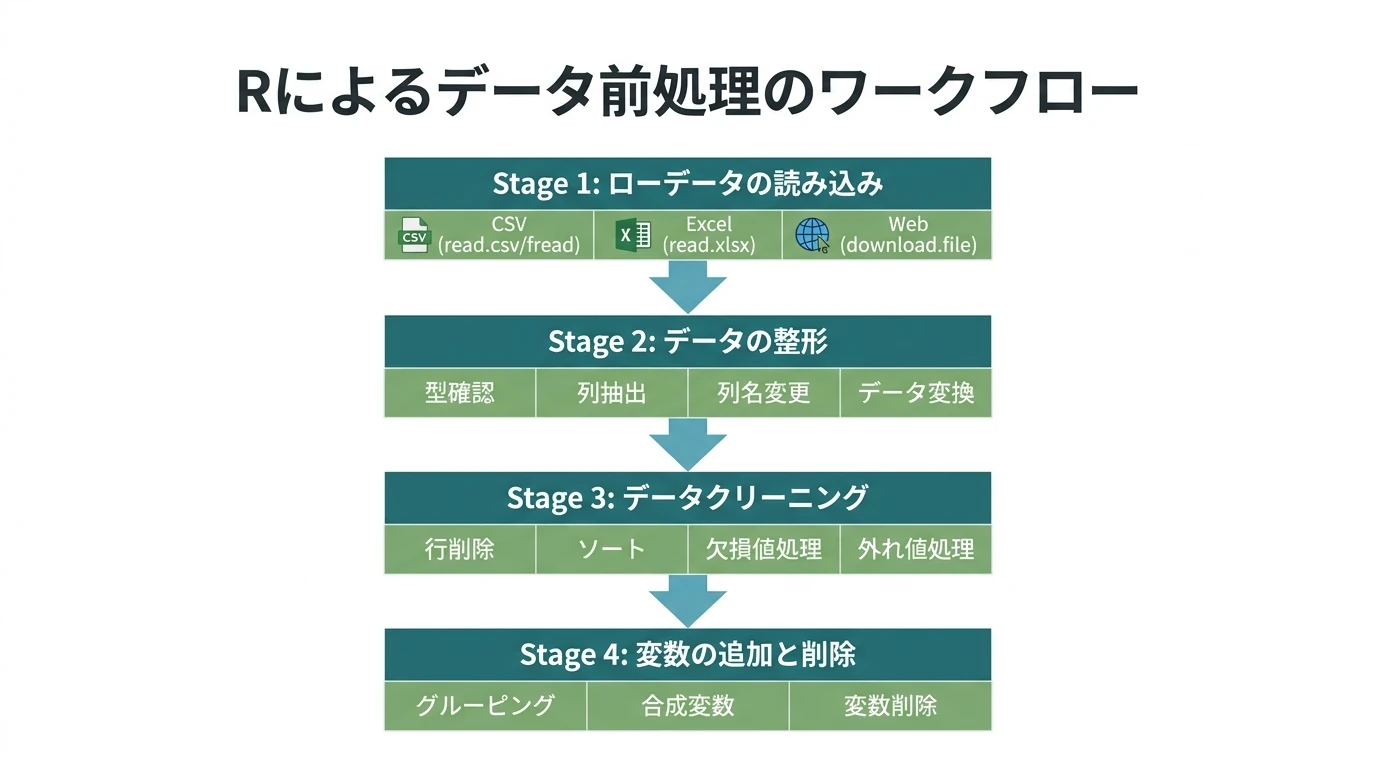
Rを使ったデータ前処理の方法を解説する。 データフレーム形式だけでなく、大きなデータを扱うのに高速なdata.tableを使ったデータの前処理の方法も解説する。 まず一般的にデータの前処理の手順は以下のようなものである。
- ローデータの読み込み
- データの整形(分析用データセットの生成。データの持つ情報は保持)
- データの型確認
- 必要な(分析対象とする)列の抽出
- 列名の変更
- データ変換
- データの型変換
- 日時データの生成
- 因子データの生成(ordered)
- データクリーニング(正しく分析できるように必要に応じて情報を一部削る)
- 行の削除(抽出)
- 行の並べ替え(ソート)
- 標準化(scale)
- 欠損値処理
- 外れ値処理
- 結合
- 変数の追加と削除
- 変数の追加
- コーディング/グルーピング
- 合成変数の生成
- 変数の削除
- 変数の追加
この順を追って、データの前処理の方法を解説する。
※data.tableオブジェクトはデータフレームクラスにも属しているため、多くの場合でデータフレームのように扱うことができるが、data.tableで扱う方が高速である。 data.tableをデータフレームと比べた時に気をつけるべき大きな違いは
- 日付でPOSIXltは使えない
- rownamesを使わない
ワーキングディレクトリのセット
プロジェクトごとにワーキングディレクトリをセットするといい
setwd('/home/ruser/data/')
テキストファイル(CSV)の読み込み
データフレーム
万能の(オプションを詳細に指定する必要があるが)read.table()、CSVファイルの読み込みに特化したread.csv()、タブ区切りテキストの読み込みに特化したread.delim()がある。
x.df <- read.csv('filename.csv', stringsAsFactors = F, fileEncoding = 'UTF-8-BOM', na.strings = '')
- ヘッダ
header = T/F
デフォルトでread.csv()はヘッダあり、read.table()はヘッダなし - 文字コード
fileEncoding = "文字コード名"
Windowsで作ったCSVを読み込む際BOMが付いていることがあるので、その場合はfileEncoding = "UTF-8-BOM"とする - 区切り文字
sep = '区切り文字'read.table()では指定必須(デフォルトで空白が区切り文字になる)。 - 文字列の扱い
stringsAsFactors = T/F
文字列が自動的にfactor型になるので、不都合な場合はstringsAsFactors = Fを指定する - 欠損値(
NA)の扱いna.strings = c('文字列', '文字列')
デフォルトではNAという文字列のみがNAと認識される。1種類であれば文字列で与える。複数種類であればベクトルで与える。データベースからエクスポートしたCSVなどでNULLという文字列を欠損値扱いする場合はna.strings = 'NULL'、空文字を欠損値扱いする場合はna.strings = ''を指定する(そうしないと空文字は長さ0の文字列として認識される)。 - 変数名と変数の型
バッチ処理では変数が決まっているので変数名と型をあらかじめ指定して読み込むことができる。col.names=c("pid", "pageName", "sales", ...)colClasses=c("integer", "character", "numeric", ...)
data.table
サイズの大きいファイルの読み込みが速い。巨大なファイルの読み込みはこれを使う一手。
カンマ区切りテキスト、その他区切りテキストいずれも同じ関数fread()で読み込む。
x.dt <- fread('filename.csv', encoding='UTF-8', sep='\t', na.strings = c(NULL, ''))
重要なオプション
read.table()やread.csv()と異なる点
- ヘッダ
header = T/F
デフォルトでヘッダ行は自動判定するが、1行目がヘッダ行でなく、かつ文字列ではない場合のみheader = Fが必要。 - 文字コード
encoding = "文字コード名"read.table()とは異なり、'ASCII'(デフォルト)と'UTF-8'しか指定できない。'UTF-8-BOM'も指定できない。data.table 1.14以降では'Latin-1'も指定可能。 - 区切り文字
sep = '区切り文字'
デフォルトで「,\t |;:」の中でファイルの最初に現れた文字("..."に囲まれた部分を除外)になる。 - 文字列の扱い
stringsAsFactors = T/Fread.table()と異なり、デフォルトで文字列はfactor型には変換せず、character型として読み込む(stringsAsFactors = Tを指定するとfactor型に変換する)。select(取得列指定),drop(削除列指定)も指定できるが、一度データを取り込んで内容を確認してからこれらの操作を行うのが普通なので、ここでは指定しない。
read.table()やread.csv()と共通
- 欠損値(
NA)の扱いna.strings = c('文字列', '文字列')
デフォルトではNAという文字列のみがNAと認識される。1種類であれば文字列で与える。複数種類であればベクトルで与える。データベースからエクスポートしたCSVなどでNULLという文字列を欠損値扱いする場合はna.strings = 'NULL'、空文字を欠損値扱いする場合はna.strings = ''を指定する(そうしないと空文字は長さ0の文字列として認識される)。 - 変数名と変数の型
col.namesとcolClassesを指定できる。 - 変数名を指定しない場合、「V1」「V2」…と自動採番される
分割されたファイルの読み込み
処理するデータが大きくなるので、読み込む対象のファイルが分割されていることもある。これをまとめて一つのdata.tableに入れる。 ファイルを個別に指定して読み込む
fread('adwords_ad_000000000000.csv', encoding = 'UTF-8') -> t_adw
fread('ss_ad_000000000000.csv', encoding = 'UTF-8') -> t_ss
fread('ss_ad_000000000001.csv', encoding = 'UTF-8') |> bind_rows(t_ss)-> t_ss
指定したディレクトリ/path/to/datadirにあるすべてのzipファイルを解凍して読み込み、
customer.dtという名前のdata.tableに代入する。
for (.f in list.files('/path/to/datadir')[grep('+\\.zip$', list.files('/path/to/datadir'))]) {
if (exists('customer.dt')) {
.str_cmd <- paste0("customer.dt <- fread(unzip('/path/to/datadir/", .f, "'), encoding='UTF-8', sep='\t', na.strings='') |> bind_rows(customer.dt)")
} else {
.str_cmd <- paste0("customer.dt <- fread(unzip('/path/to/datadir/", .f, "'), encoding='UTF-8', sep='\t', na.strings='')")
}
eval(parse(text=.str_cmd))
}
customer.dtがなければ生成、あれば追記している。
Excelファイルの読み込み
read.xlsx{openxlsx}を使う。
m_user.df <- read.xlsx('C:/home/user1/doc/マスタ.xlsx', na.strings = '', sheet = 'ユーザ') |> mutate(id = as.integer(id))
データファイルのダウンロード(webからデータを取得)
R-3.2.2以降デフォルトでHTTPSでのダウンロードをサポートするようになり、HTTPSでのファイルの取得が容易になった。現代的な実装としては{httr2}を推奨する。自己署名型の証明書には標準のdownload.file()は対応していないため、オレオレ証明書のサイトでは{httr2}または{RCurl}を使う。
CSVファイル
banques <- read.table("https://archive.ics.uci.edu/ml/machine-learning-databases/00202/banques.txt", header=T, sep="\t", stringsAsFactors=FALSE)
圧縮ファイル(.zip)→ダウンロードしてから展開する必要がある
ファイルを圧縮している場合
# ダウンロード
tmp <- tempfile()
download.file("https://archive.ics.uci.edu/ml/machine-learning-databases/00206/slice_localization_data.zip", tmp)
# 解凍と読み込み
localization <- read.table(unzip(tmp), header=T, sep=",", stringsAsFactors = FALSE)
# 使い終わったファイルの削除
unlink(tmp);rm(tmp)
ディレクトリを圧縮している場合
# ダウンロード
tmp <- tempfile()
download.file("https://archive.ics.uci.edu/ml/machine-learning-databases/00296/dataset_diabetes.zip", tmp)
# 解凍と読み込み
files <- unzip(tmp)
diabetes <- read.table(files[1], header=T, sep=",", stringsAsFactors = FALSE)
# 使い終わったファイルの削除
unlink(files);rm(files)
unlink(tmp);rm(tmp)
httr2を使う(推奨)
{httr2}は{curl}の上に構築された現代的なHTTPクライアントで、パイプ可能なAPIとretry・OAuthなどの機能を備える。request()でリクエストオブジェクトを作成し、req_perform(path = ...)でレスポンスボディを直接ファイルに保存できる。大容量でもメモリに載せずに済む。自己署名証明書のサイトではreq_options(ssl_verifypeer = 0)を付与する。
# ダウンロード
library(httr2)
tmp <- tempfile()
request("https://archive.ics.uci.edu/ml/machine-learning-databases/00296/dataset_diabetes.zip") |>
req_options(ssl_verifypeer = 0) |>
req_perform(path = tmp)
# 解凍と読み込み
files <- unzip(tmp)
diabetes <- read.table(files[1], header = T, sep = ",", stringsAsFactors = FALSE)
# 使い終わったファイルの削除
unlink(files); rm(files)
unlink(tmp); rm(tmp)
RCurlを使う→自由度高い
# ダウンロード
require(RCurl)
binData <- getBinaryURL("https://archive.ics.uci.edu/ml/machine-learning-databases/00296/dataset_diabetes.zip", ssl.verifypeer=F)
tmp <- tempfile()
conObj <- file(tmp, open = "wb")
writeBin(binData, conObj)
close(conObj)
# 解凍と読み込み
files <- unzip(tmp)
diabetes <- read.csv(files[1], stringsAsFactors = FALSE)
# 使い終わったファイルの削除
unlink(files);rm(files)
unlink(tmp);rm(tmp)