
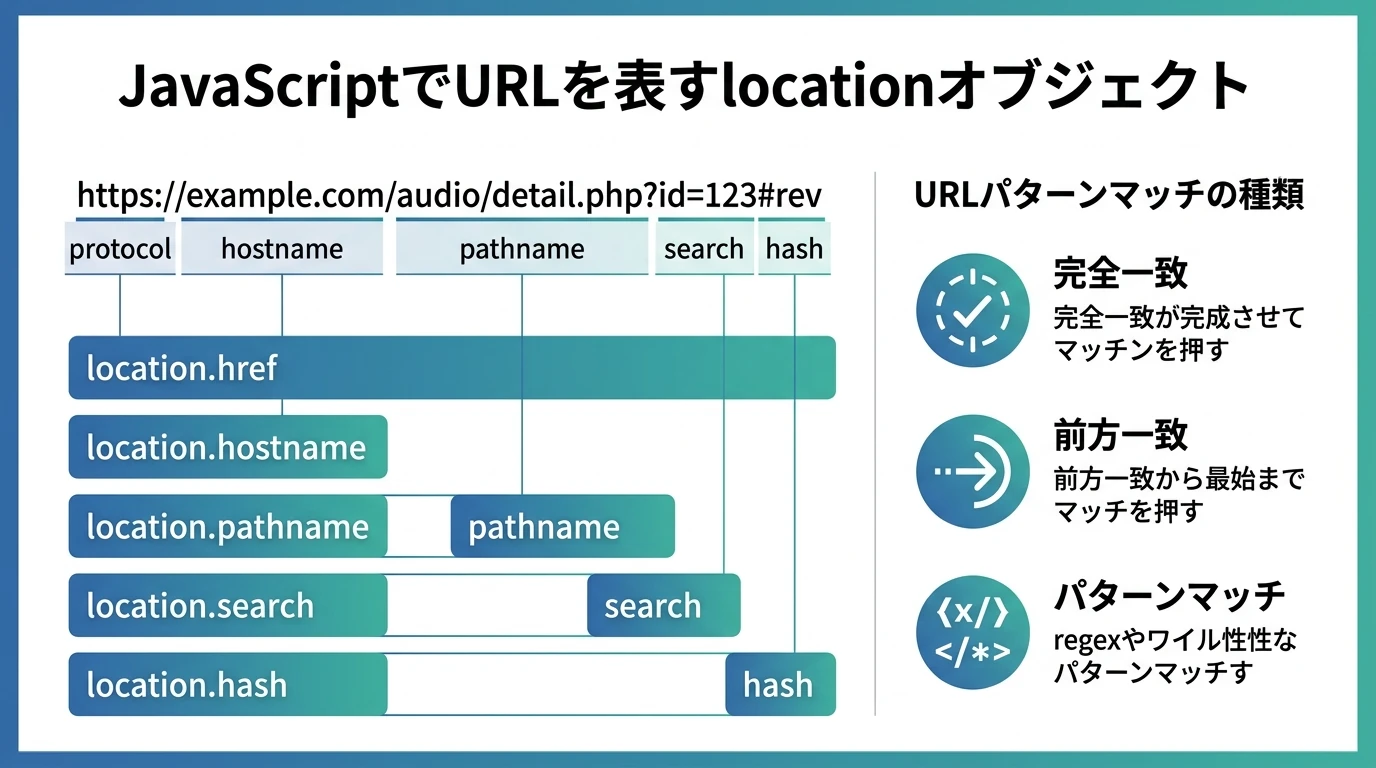
JavaScriptでURLを表すlocationオブジェクト URLとそのパーツはJavaScriptの変数として取得できる。 タグマネージャなどでJavaScriptの変数を使ってURL(の一部)を指定する場合や、直接Javascriptを書いてURLを指定する場合にこれらを使うことがある。 URLの構造についてはURLと向き合う必要性を参照。 変数名 意味 例 window.location.href URL全体 https://example.com/audio/detail.php?id=123#rev window.location.protocol プロトコル https: …
続きを読む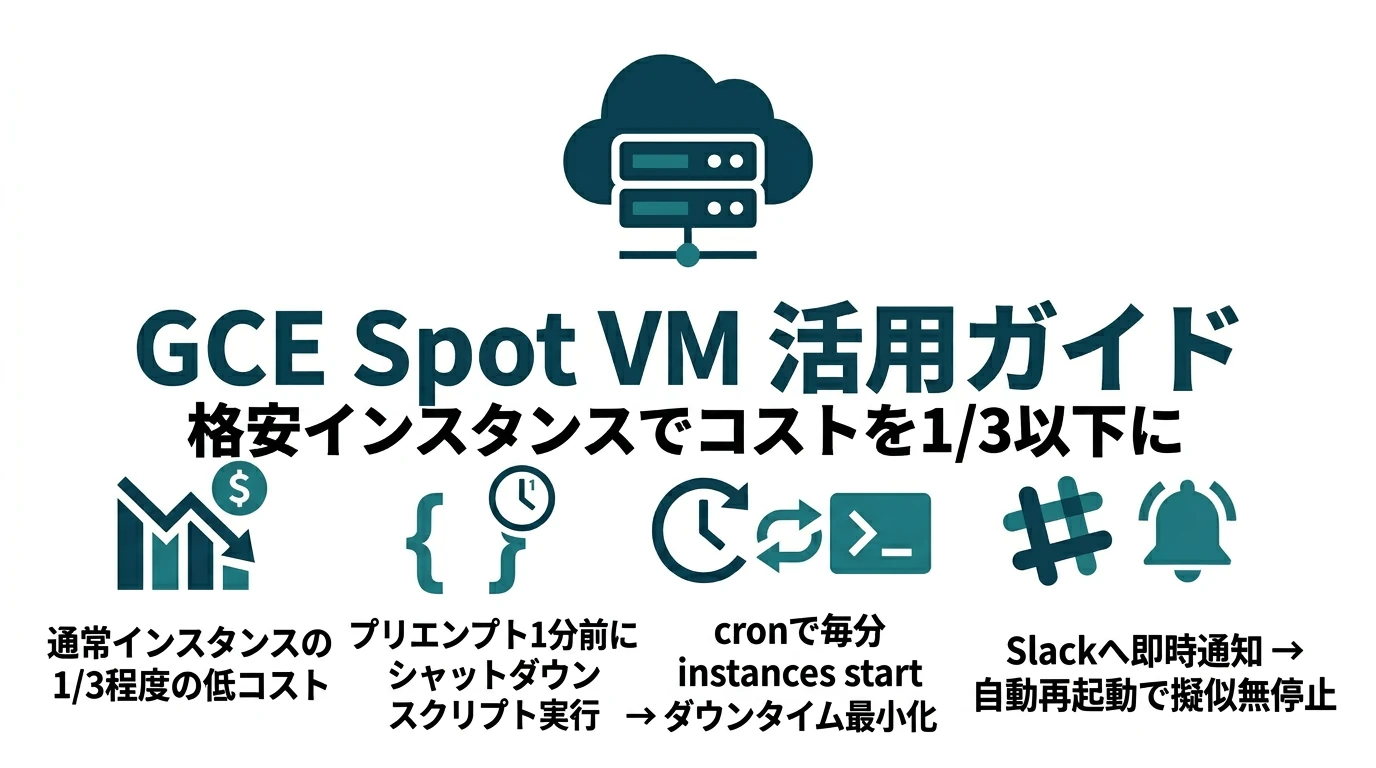
格安で使えるGCEのSpot VM(旧プリエンプティブインスタンス)。問答無用でシャットダウンされるというクセが困りものだが、使いようによってはハイスペックのインスタンスを安く効果的に使うことができる。ここではそのシャットダウン対策と最大限活用するためのヒントを紹介する。 機械学習用途ではVertex AI TrainingやGKE Autopilotなどマネージドサービスが充実しており、GCE直接利用は減少傾向にあるが、GPU/TPUを利用した機械学習ワークロードでコストを抑えたい場合などにSpot VMは有効である。 Spot VM(旧プリエンプティブインスタンス)とは Google Compute EngineのSpot VM …
続きを読む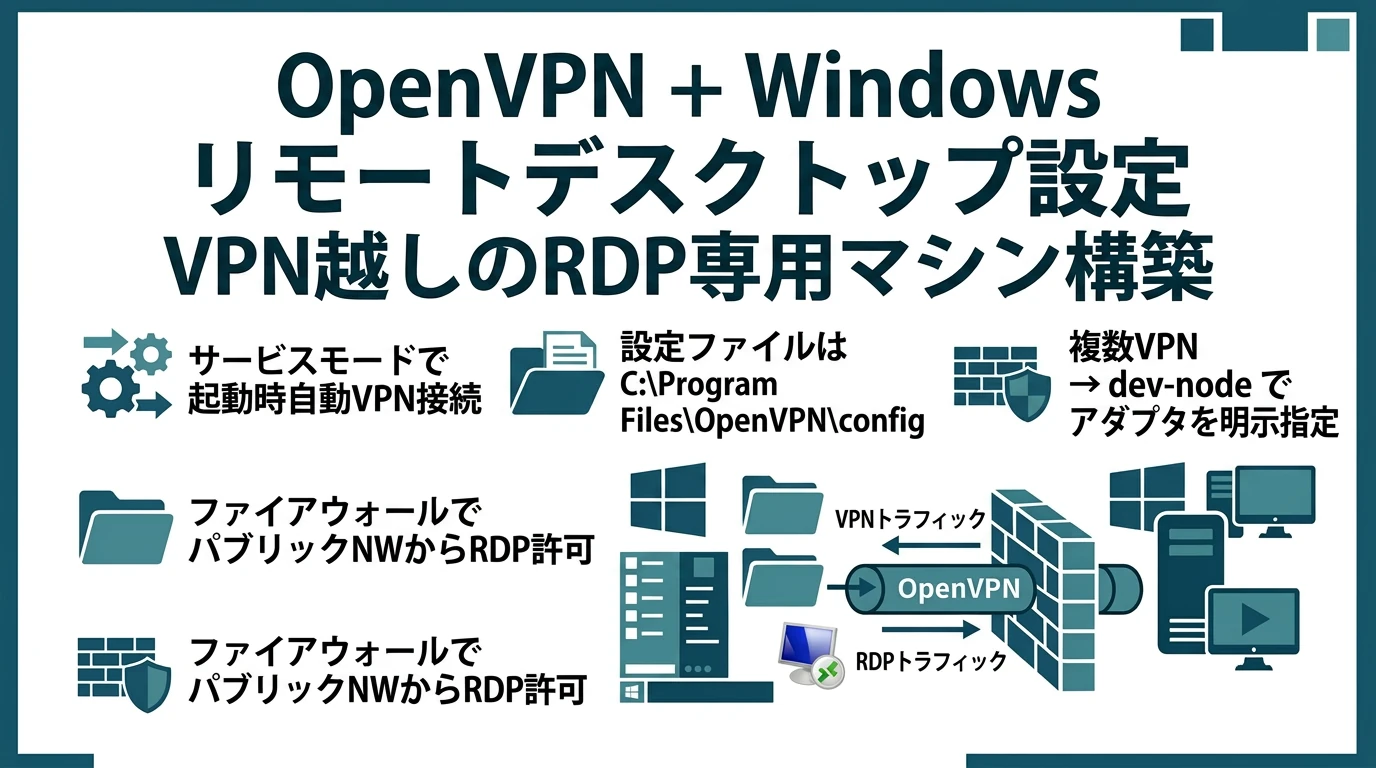
リモートデスクトップで接続される専用のWindowsマシンを用意するにあたり、VPN接続は必須である。VPNにはWireGuardやTailscaleなどゼロ構成の選択肢もあるが、従来型のOpenVPNでサーバ・クライアントともに設定する場合、2026年時点ではOpenVPN 2.6以降でTAPからWintunドライバへの移行が進んでいる。 OpenVPNクライアントをWindows 10/11にインストールし、そこから常時VPNサーバに接続する形でプライベートネットワークを作り、外の端末からセキュアにWindows機にリモートデスクトップ接続する。Windows機をVPNサーバにするのではない。このやり方、意外と難しいので説明する …
続きを読む
無料でPythonの実行環境を使わせてもらえるGoogle Colaboratory(以下、Colab)。現在の無料枠でも、T4やL4などの高性能なGPU、約12GB〜16GBのメモリ、そして100GB前後のディスクスペースが利用できる強力な環境であり、手元のPCよりハイスペックな人も多いだろう。 データサイエンスの分野ではPythonが主流である一方で、Rユーザにとっては「PythonだけでなくRでも使えたらいいのに」と思うところである。実は、Colabのインスタンスには標準でRの環境が用意されており、用途に応じて複数のアプローチでRを利用することができる。この記事では、最新環境に合わせてColabでRを使い倒す方法と、その高速化 …
続きを読む
Javascriptで正規分布の乱数発生(rnorm)、確率密度関数(dnorm)、累積分布関数(pnorm)、累積分布の逆関数(qnorm)を実装する。すべて標準正規分布を想定。 Javascriptに限らず使えるアルゴリズムだが、日本語でまとまっている情報があまりないのと、ブラウザ上でA/Bテストなど有意性をみる検定などできたら面白いということでJSでやってみる。 なお、実務で手軽に使いたい場合は stdlib-js や jStat といったライブラリも検討するとよい。本記事はアルゴリズムの中身を理解する目的で、ライブラリを使わずスクラッチで実装する。 正規乱数の生成(rnorm) 1行でBox-Muller法で。 …
続きを読む
linuxなどで使うテキスト編集コマンドの使い方で、これさえ知っていればOKというもののまとめ(vi, sed, grep, sort, uniq, cut, join, tr, iconv, diff)。 後半は特に必要とはいえないため適当。重要なのはvi, sed, grepまでかな。 複数のファイルを扱う場合に使うxargsコマンドについても説明する。 テキスト検索にはripgrep(rg)やfzfなどのモダンなツールもあるが、本記事では基本的なコマンドに絞る。 vi ※(数指定)のついているものは、コマンドの前に数を指定することで指定された数だけ該当する操作を行える。 (6hで6字分左に移動) コマンドモードと入力モード コ …
続きを読む
DBの管理系コマンドは導入専門にやっていれば忘れることはないのだが、 分析目的でちょっとインストールした場合など、そんな頻繁に設定しない場合は忘れてしまう。 そんなPostgreSQLの管理コマンド、ユーザ管理など意外と落とし穴があるので復習しておく。 Cloud SQL、RDS、AlloyDBなどのマネージドDBを利用する場合はpg_ctlやinitdbは不要である。 導入手順は インストール データベースディレクトリの作成(initdbコマンド) 起動(pg_ctlコマンド) ユーザの登録(createuserコマンド) データベースの作成(createdbコマンド) データベースの権限管理 という順になる。 pg_ctlコマン …
続きを読む
Perlのワンライナー。 sedやawkでは扱いにくい、複雑な条件分岐や変換が必要なテキスト加工(CSVファイル処理など)に適している。UTF-8が標準化した現在では文字コード変換のニーズは減っているが、複雑な正規表現やPerlの組み込み機能を活用できる場面では有用である。 いろいろオプションはあるのだが、最小限に絞って備忘録的に。 よく使うオプション 基本 -e 'スクリプト': 実行するPerlスクリプトを指定(1行) perl -e 'print "Hello"' output: Hello 入力が前提 -l:(入力から改行を取り除いたうえで最後に)出力結果を改行する。表示制御の目的で使われることが多い。データ加工の際は使わな …
続きを読む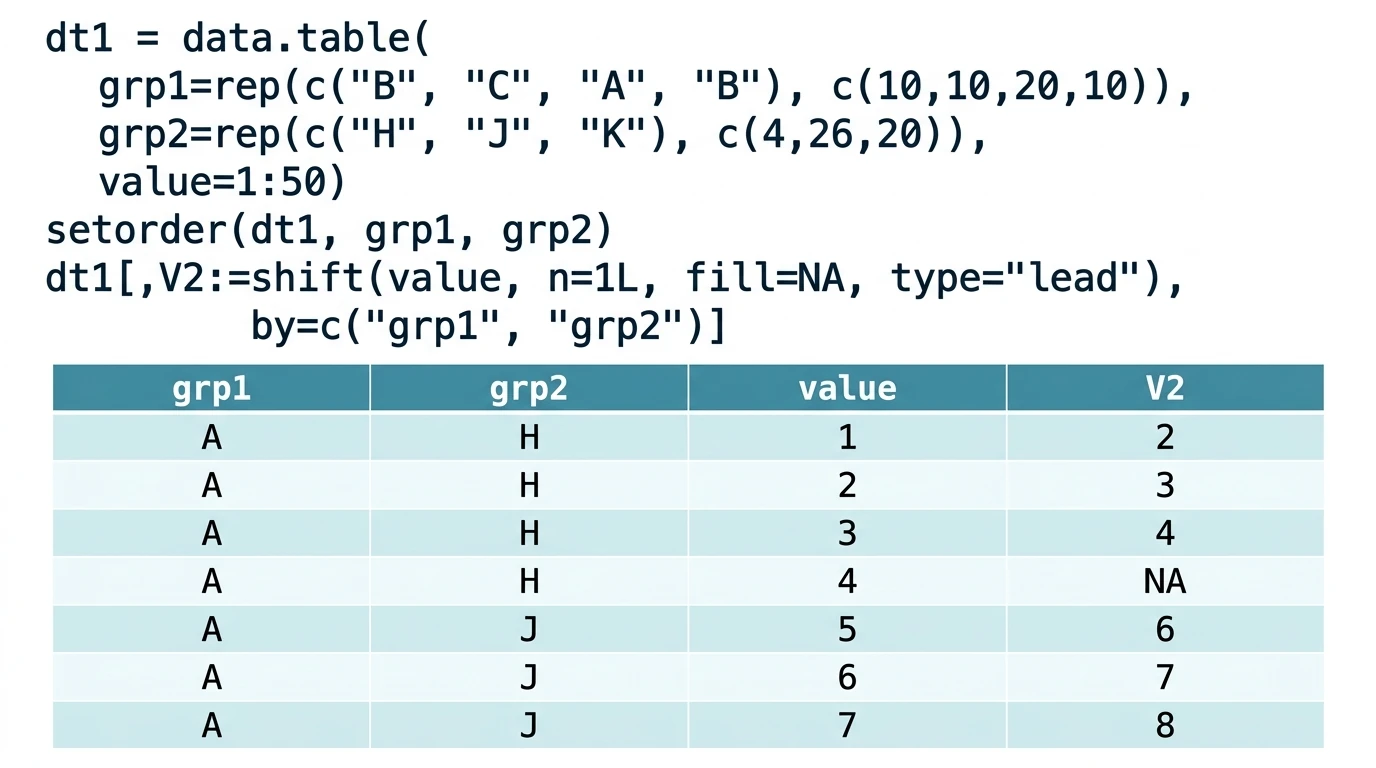
Rのdata.tableはデータフレームを高速に扱えるように改良した形式だが、この機能を提供するdata.tableパッケージには添え字を使ったdata.tableの処理機能だけでなく、さまざまな関数が実装されている。 中にはdata.table以外の形式にも使える関数もあり、 dt[,col1:=関数()] の形式で使えるdata.table用の関数にも一般的に知られていない便利なものが数多くある。 特に高速化を意識しているものが多く、知っていると処理時間を短縮できる。 data.tableはdplyrとセットで使われることも多いが、dplyr自体はdata.tableの高速仕様にのっとったものではない(tibble形式)ため、 …
続きを読む
XGBoostは機械学習手法として 比較的簡単に扱える 目的変数や損失関数の自由度が高い(欠損値を扱える) 高精度の予測をできることが多い ドキュメントが豊富(日本語の記事も多い) ということで大変便利。 ただチューニングとアウトプットの解釈については解説が少ないので、このあたりについて説明する。 XGBoostとは? 勾配ブースティングのとある実装ライブラリ(C++で書かれた)。イメージ的にはランダムフォレストを賢くした(誤答への学習を重視する)アルゴリズム。RとPythonでライブラリがあるが、ここではRライブラリとしてのXGBoostについて説明する。 XGBoostのアルゴリズム自体の詳細な説明はこれらを参照。 …
続きを読む