目次
NSEとは
NSEとはNon-standard evaluationの略。
関数に対して値を与えるのではなく、表現式(expression)を与えて処理させる方法。
言葉にするとわかりにくいので、具体例で。
NSEを使う局面
やりたいこと
たとえばデータフレームcustomer.df内の
f_purchaseとdurationという列に対して処理をする関数myfun()を作りたい場合
直感的には
myfun(customer.df, f_purchase, duration)
という引数の与え方をしたい。これがRのもっとも自然なコーディングである。
たとえば
glm(f_purchase ~ duration, data = customer.df, family = binomial())
などと同じである。
これを実現するのがNSEである。
NSEを使わない場合、
myfun(customer.df$f_purchase, customer.df$duration)
という指定をせねばならず、引数が増えた場合などさらに「customer.df$」を繰り返すことになり、Rのコーディングとしてイケてない。
NSEはイケてるRっぽいコーディングをする方法の一つなのである。
ちなみにNSEの対義語がSE(Standard evaluation)になる。
NSEの具体的な利用例
RでNSEでの入力を前提にしている機能は主に
- dplyr
- ggplot2
- モデル式(formula)
自作関数の中でこれらを扱う際、自作関数の引数としてNSEを使えるようにする方法を説明する。
dplyrにおけるNSE
dplyrでは
data %>% mutate(y = x + 1)
のように引数に列名そのものを入れている。これがNSEになる。
というよりdplyrはデータ処理の変数指定方法においてNSEを使えるようにしたライブラリである。
一方、これがSE(Standard evaluation)となると
data %>% mutate_(y = 'x + 1')
引数を文字列として与えている。
そして関数名の末尾にアンダーバー「_」が付く。
dplyrの一般的な関数(mutate, filter, select, summariseなど)はNSEを扱うもので、これに対して末尾にアンダーバーが付いた関数(mutate_, filter_, select_, summarise_など)がSEとなる。
ちなみにdplyrではSEは非推奨とされている。
ggplot2におけるNSE
ggplot2では
ggplot(data=iris, aes(x = Sepal.Length, y = Sepal.Width)) + geom_point()
のようにプロットする変数をaes()で指定する。
このaes()内で指定しているのがここではデータフレームirisの列名そのものになっており、これがNSEになる(x = iris$Sepal.Lengthやx = 'Sepal.Length'のような指定の仕方ではない)。
ggplot2は、グラフ描画の変数指定方法においてNSEを使えるようにしたものである。
モデル式におけるNSE
Rの多くの分析関数では関数名(formula = モデル式, data = データフレーム)という形式になっていることが多い。たとえば
lm(formula = Petal.Length ~ Petal.Width, data = iris)
Petal.Length ~ Petal.Widthの部分がモデル式。データフレームirisの列名そのものを指定している。
ちなみにSE(Standard evaluation)を使う関数では
lsfit(iris$Petal.Width, iris$Petal.Length)
列を抽出したベクトルを引数とする。
モデル式を使った表現は、データ分析の変数指定方法においてNSEを使えるようにしたものである。
NSE関数の実装方法
共通して念頭におくべきこと
NSEとは引数を表現式(expression)で与えることである(復習)。
いずれの方法も、表現式で与えられた変数(引数)を関数の中で使うにはまずその変数自体をクォート処理する必要がある。表現式を解釈して処理の中で使えるようにすることである。
これを行うのがsubstitute()関数である(実際ににはこの関数にはもっと広い機能があるが、ここではそれだけ覚えておけばいい)。
# テストデータ
#data = data.frame(id = 1:10, n_pv_home = rpois(n = 10, lambda = 3), n_pv_list = rpois(n=10, lambda = 2))
myfun1 <- function(data, x, y) {
x <- substitute(x)
y <- substitute(y)
# x,yを使った処理
z = data[[x]] + data[[y]] # (1)
:
}
参考までに、関数の引数に代入する時点で(文字列そのものに対して)クォート処理を行うのがquote()関数である(それに対して変数に対してクォート処理を行うのがsubstitute())。
myfun2(data, quote(n_pv_home), quote(n_pv_list))
myfun2 <- function(data, x, y) {
# x,yを使った処理
# x,yを使った処理
z = data[[x]] + data[[y]] # (2)
:
}
(1)のx,yと(2)のx,yは同じものになる。quote()関数については忘れててもいい。
NSE関数の中でdplyrを使う
2017/12/12現在のdplyr(0.7.1から0.7.4)にはバグがあり、data.tableのNSE内の処理を正しく扱えない。そのため一度データフレームに変換して処理する必要がある。
dplyrにはクォート用の関数としてquo(), enquo()という関数が用意されている。
機能としてはbase Rのquote(), substitute()とそれぞれ同じなのでどちらを使ってもいい。
シンプルな例で
iris %>%
group_by(Species) %>%
summarise(y_mean = mean(Sepal.Length))
これと同じことをする自作関数myfun3()
ただしmyfun3(iris, Species, Sepal.Length)という形式で引数を与えて実行する関数を考える。
myfun3 <- function(data, x, y) {
# 変数のクォート
x <- enquo(x) # (1) equivalent to substitute(x)
y <- enquo(y) # (1) equivalent to substitute(y)
data %>%
as.data.frame %>% # (2)
group_by(!!x) %>% # (3) equivalent to group_by_(x)
summarise(
y_mean = mean(!!y)
) %>% return
}
ポイントは
- (1)
enquo()で変数をクォート - (1) base Rの
quote()とsubstitute()はそれぞれdplyrのquo()、enquo()と同じ - (2) dplyr0.7.1〜0.7.4ではデータフレーム化しないと処理できない
https://github.com/tidyverse/dplyr/issues/2937 - (3)
!!クォート済変数で、NSEとして扱える。!!を付けないと文字列扱いになり、SEでの扱いになる(group_by_()関数)
実際に使うのはもっと複雑なケースで、たとえば以下のようになる。
# xで与えた変数ごとにyで与えた変数を集計。もしbyを与えていればそれでもグループ化する
myfun4 <- function(data, x, y, y_label = NULL, by = NULL) {
# 変数のクォート
x <- enquo(x) # (1) equivalent to substitute(x)
y <- enquo(y) # (1) equivalent to substitute(y)
data %>%
as.data.frame %>% # (2)
group_by(!!x) -> .tmp # (3) equivalent to group_by_(x)
# もしbyが引数として与えられていれば、その列でgroup byする
if(!missing(by)) { # (a)
by <- enquo(by) # (1) equivalent to substitute(by)
.tmp %>% group_by(!!by, add = T) -> .tmp # (b) add = Tで追加group by
}
# 変数のラベルを作る変数。引数として与えられていればそれをそのまま採用し、
# 与えられていなければ変数名+' rate'をラベルに採用する
y_label <- ifelse(missing(y_label), paste0(quo_name(y), ' rate'), y_label) # (4)
# 集計処理
.tmp %>%
summarise(
# 変数名は「N」(固定値)
N = n(),
# (5) 変数名をy_labelで指定した値にする(動的)
!!y_label := sum(!!y) / N
) -> .tmp
return(.tmp)
}
- (4) クォート済みの変数
yに対してquo_name(y)で変数名の文字列そのもの(結局引数で与えたオリジナルのyの文字列)を取得できる - (5) 変数名をy_labelで指定した値として動的に付ける場合、
!!変数名 := 式とする
その他NSEではないが
- (a) 引数を与えなければ(NULLの場合)
missing()でTRUEになる。is.null()関数だとうまくいかない - (b)
group_by(data, var, add = T)で追加group byできる。デフォルトでFALSEで、その場合それまでにgroup byしたものがリセットされる。
参考
https://cran.r-project.org/web/packages/dplyr/vignettes/programming.html
https://speakerdeck.com/yutannihilation/dplyrzai-ru-men-tidyevalbian
NSE関数の中でggplot2を使う
ggplot2ではtidyeval(上記のdplyrのような操作を可能にする仕組み)をサポートしていないため、SE(Standard evaluation)化する。方法はggplot2でデータを指定するaes()関数をaes_()関数に書き換えて引数をクォートするだけである。基本的にその他の関数、引数ではデータを指定しないため、関係はない。
たとえば
ggplot(data=iris, aes(x=Sepal.Length, y=Sepal.Width)) + geom_point()
これと同じことをする自作関数myfun5()
ただしmyfun5(iris, Sepal.Length, Sepal.Width)という形式で引数を与えて実行する関数を考える。
myfun5 <- function(d, var1, var2) {
var1 <- substitute(var1) # (1)
var2 <- substitute(var2) # (1)
ggplot(
data = d,
aes_(x = var1, y = var2) # (2)
) + geom_point()
}
ポイントは
- (1)
substitute()で変数をクォート - (2)
aes_()関数ではクォート済みの変数をそのまま指定する
dplyrの書式でggplot()を実行する場合、つまり
iris %>%
ggplot() +
geom_point(aes(x=Sepal.Length, y=Sepal.Width))
と同じことをする場合(出力結果は先と同じだが、Rの文法上)
myfun6 <- function(d, var1, var2) {
var1 <- substitute(var1) # (1)
var2 <- substitute(var2) # (1)
d %>%
ggplot() +
geom_point(aes_(x = var1, y = var2)) # (2)
}
ただしこの場合dplyrを呼び出しているので、(1)の部分はenquo()関数を使ってもいい
(dplyrを呼び出していない場合はenquo()自体が使えない)
実際にの場面ではもっと複雑な処理が求められる。
たとえばaes_()以外でfacet_grid()を使う場合にはそこでデータを指定することになる。
また引数で与えた変数以外の変数を内部で生成し、それもプロットに使うこともある。
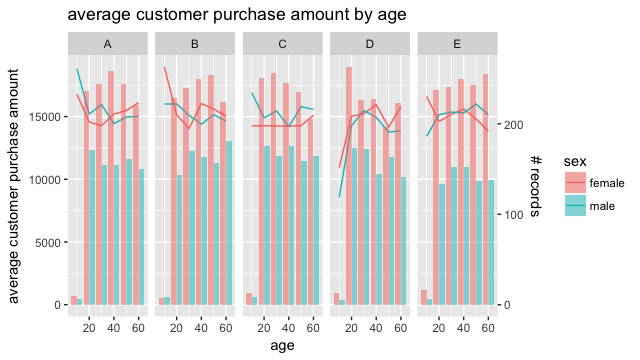
具体的な例でdplyrとggplot2の組み合わせで、dplyrで複数軸のグループごとに集計した結果をggplot2で複数グラフを表示する。言葉だとよくわからないので、たとえばこんな感じのグラフを出力する。

myfun7 <- function(data, x, y, y_label = NULL, by, facet = NULL) {
x <- enquo(x) # (1)
y <- enquo(y)
y_label <- ifelse(missing(y_label), paste0(quo_name(y), ' rate'), y_label)
by <- enquo(by) # (1)
data %>%
as.data.frame %>% # https://github.com/tidyverse/dplyr/issues/2937
group_by(!!x, !!by) -> .tmp
if(!missing(facet)) {
facet <- enquo(facet)
.tmp %>% group_by(!!facet, add = T) -> .tmp
}
.tmp %>%
summarise(
N = n(),
rate = sum(!!y) / N # (2)
) -> .tmp
.scale <- max(.tmp$rate) / max(.tmp$N)
# ここからggolot2の処理
.tmp %>%
ggplot() +
geom_line(aes_(x = x, y = quote(rate), group = by, colour = by)) + # (3)
geom_bar(aes_(x = x, y = quote(N * .scale), fill = by), stat = 'identity', alpha = 0.5, position = 'dodge') + # (4)
scale_y_continuous(
limits = c(0, NA),
sec.axis = sec_axis(~ . / .scale, name = '# records')
) +
xlab(quo_name(x)) +
ylab(y_label) +
ggtitle(paste0(y_label, ' by ', quo_name(x))) -> .gp
if(!missing(facet)) {
.gp + facet_grid(as.formula(substitute(. ~ facet))) # (5)
} else {
.gp
}
}
自作関数の引数のNSEを使う変数と、関数内部で発生する変数を同時にプロットする。プロットに使うのは(1)で指定した変数(自作関数の引数のNSE)と、自作関数内部で発生した変数(2)の両方。通常(2)のような変数はggplot2ではaes()で指定する。ところが今回は(1)がaes()に対応しないため、(2)をaes_()に合わせて変換して使う。
それが(3)のquote()関数になる。quote()関数では、(4)のように中に数式を入れることもできる。
(5)ではfacet_grid()で切り口にする変数を指定する。facet_grid()の引数は分類に使う変数(最大2個)をモデル式で指定する
facet_grid(縦軸 ~ 横軸)
指定の仕方は次で説明する。
NSE関数の中でモデル式を使う
たとえば
lm(formula = Petal.Length ~ Petal.Width, data = iris)
これと同じことをする自作関数myfun8()
ただしmyfun8(iris, Sepal.Length, Sepal.Width)という形式で引数を与えて実行する関数を考える。
myfun8 <- function(d, var1, var2) {
fit <- lm(formula = as.formula(substitute(var1 ~ var2)), data = d)
return(fit)
}
ポイントはsubstitute()でモデル式全体をクォートした上で、as.formula()関数にかけること。
以下も有効である。
myfun9 <- function(d, var1, var2) {
var1 <- substitute(var1)
var2 <- substitute(var2)
fit <- lm(formula = as.formula(substitute(var1 ~ var2)), data = d)
return(fit)
}
すでに一度クォート済みの変数を使う場合(このlm()以前のロジックで使用するなど)、このような書き方になる。dplyrを使っている場合、enquo()関数でもいい。先のfacet_grid()の例はこれと同じになる(モデル式で使う変数facetは事前にクォートして使用済み)。
facet_grid(as.formula(substitute(. ~ facet)))
交互作用分析の関数の実装例
たとえば交互作用分析をする際には、
- ベースのモデル式(交互作用のあるモデル、ないモデルのいずれにも含む共通部分)
- 交互作用を調べたい変数
を与える形式にするのがわかりやすい。
interactionAnalysis(ベースのモデル式, 交互作用を見る変数, data = データ)
# たとえば
interactionAnalysis(data = iris, var_res = Sepal.Length, vars_base = Sepal.Width + Petal.Length, Petal.Width)
このような引数の与え方を実現する関数を考える。
interactionAnalysis <- function(data, var_res, vars_base, var_interaction, family = 'gaussian'){
data %>%
as.data.frame %>% # https://github.com/tidyverse/dplyr/issues/2937
mutate_if(is.numeric, scale) -> data
non_interaction.glm <- glm(as.formula(substitute(var_res ~ vars_base + var_interaction)), data = data, family = family) # (1)
interaction.glm <- glm(as.formula(substitute(var_res ~ vars_base * var_interaction)), data = data, family = family) # (1)
if(grepl('^(binomial|poisson)$', non_interaction.glm$family$family)){
test <- 'Chisq'
} else if (grepl('^(pseudo|gaussian)', non_interaction.glm$family$family)){
test <- 'F'
}
compare.anova <-anova(non_interaction.glm, interaction.glm, test = test)
return(list(
conpare = compare.anova,
non_interaction_model = non_interaction.glm,
interaction_model = interaction.glm
))
}
2017/12/12現在のdplyr(0.7.1から0.7.4)にはバグがあり、data.tableのmutate_***()が機能しない。そのため一度データフレームに変換して処理する必要がある。
NSEに関連するのは(1)の部分のみ
as.formula(substitute(var_res ~ vars_base + var_interaction))
as.formula(substitute(var_res ~ vars_base * var_interaction))
参考
http://adv-r.had.co.nz/Computing-on-the-language.html
データの加工や分析で使うRの使い方 の記事一覧